Download as PDF, PPTX










![Pipeline
p = beam.Pipeline('DirectRunner')
(p | 'input' >> beam.Create(['Hello', 'World'])
| 'output' >> beam.io.WriteToText('gs://bucket/hello')
)
p.run()
(Pythonista )](https://image.slidesharecdn.com/dataflowdetensorflow-170315145018/85/Google-Cloud-Dataflow-meets-TensorFlow-13-320.jpg)
![Pipeline
(p | 'input' >> beam.Create(['Hello', 'World'])
| 'output' >> beam.io.WriteToText('gs://bucket/hello')
)
Pipeline |](https://image.slidesharecdn.com/dataflowdetensorflow-170315145018/85/Google-Cloud-Dataflow-meets-TensorFlow-14-320.jpg)
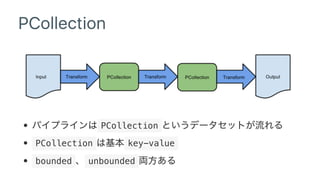
![PCollection
beam.Create(['Hello', 'World'])
plaintext 'Hello' 'World' 2
In Memory](https://image.slidesharecdn.com/dataflowdetensorflow-170315145018/85/Google-Cloud-Dataflow-meets-TensorFlow-17-320.jpg)











![train
TensorFlow OK Dataflow
def train(param):
import tensorflow as tf
from sklearn import cross_validation
#
iris = tf.contrib.learn.datasets.base.load_iris()
train_x, test_x, train_y, test_y = cross_validation.train_test_split(
iris.data, iris.target, test_size=0.2, random_state=0
)
# https://www.tensorflow.org/get_started/tflearn
feature_columns = [tf.contrib.layers.real_valued_column("", dimension=4)]
classifier = tf.contrib.learn.DNNClassifier(feature_columns=feature_columns,
hidden_units=param['hidden_units'],
dropout=param['dropout'],
n_classes=3,
model_dir='gs://{BUCKET}/models/%s'% model_id)
classifier.fit(x=train_x,
y=train_y,
steps=param['steps'],
batch_size=50)
result = classifier.evaluate(x=test_x, y=test_y)
ret = {'accuracy': float(result['accuracy']),
'loss': float(result['loss']),
'model_id': model_id,
'param': json.dumps(param)}
return ret](https://image.slidesharecdn.com/dataflowdetensorflow-170315145018/85/Google-Cloud-Dataflow-meets-TensorFlow-29-320.jpg)





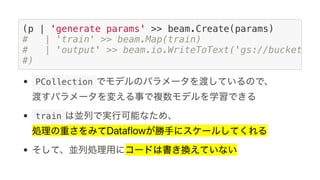

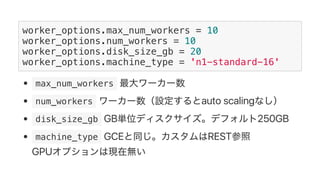









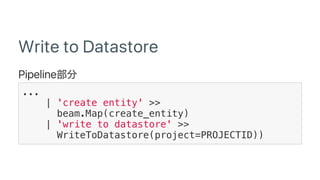
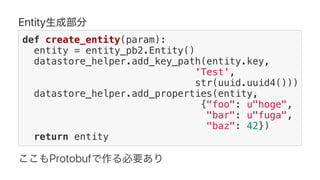



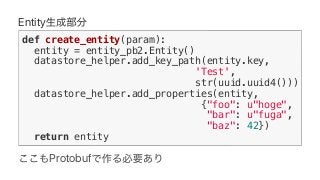
![Protobuf Datastore Client lib
def csv_format(entity_pb):
entity = entity_from_protobuf(entity_pb)
columns = ['"%s"' % entity[k]
for k in sorted(entity.keys())]
return ','.join(columns)
p = beam.Pipeline(options=options)
(p | 'read from datastore' >>
ReadFromDatastore(project=PROJECTID,
query=query)
| 'format entity to csv' >>
beam.Map(csv_format)
...](https://image.slidesharecdn.com/dataflowdetensorflow-170315145018/85/Google-Cloud-Dataflow-meets-TensorFlow-57-320.jpg)
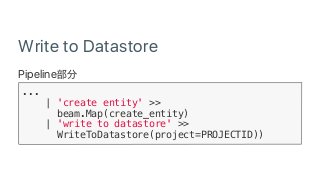




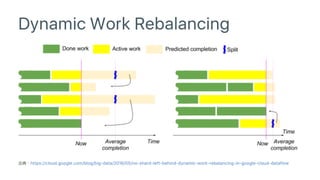
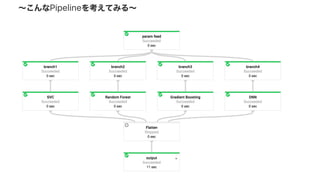
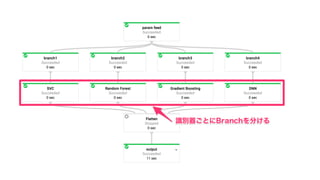
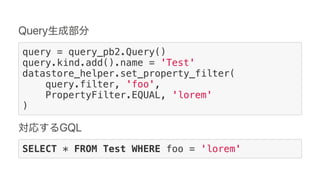
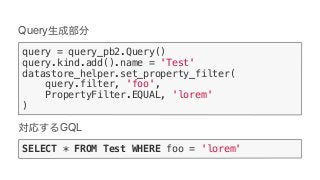
Google Cloud Dataflow can be used to build TensorFlow pipelines. Dataflow allows training multiple TensorFlow models in parallel and writing results to Cloud Datastore. A sample pipeline shows generating training parameters, mapping over them to train models, and writing accuracy results to Cloud Storage. Dataflow provides autoscaling and machine types can be configured. The new DatastoreIO allows reading from and writing to Cloud Datastore from Dataflow pipelines using Protobuf and entity conversion helpers.























































































