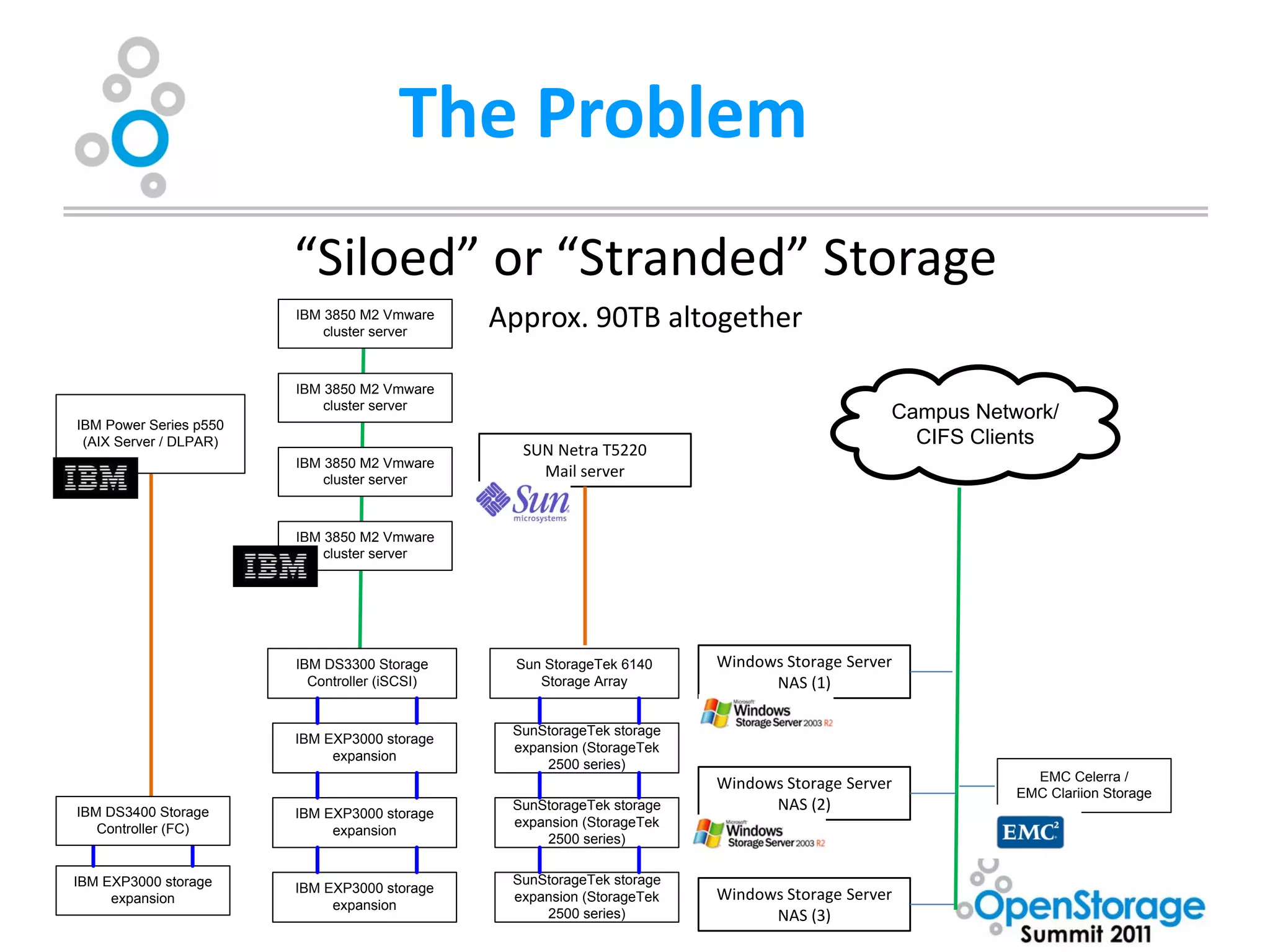
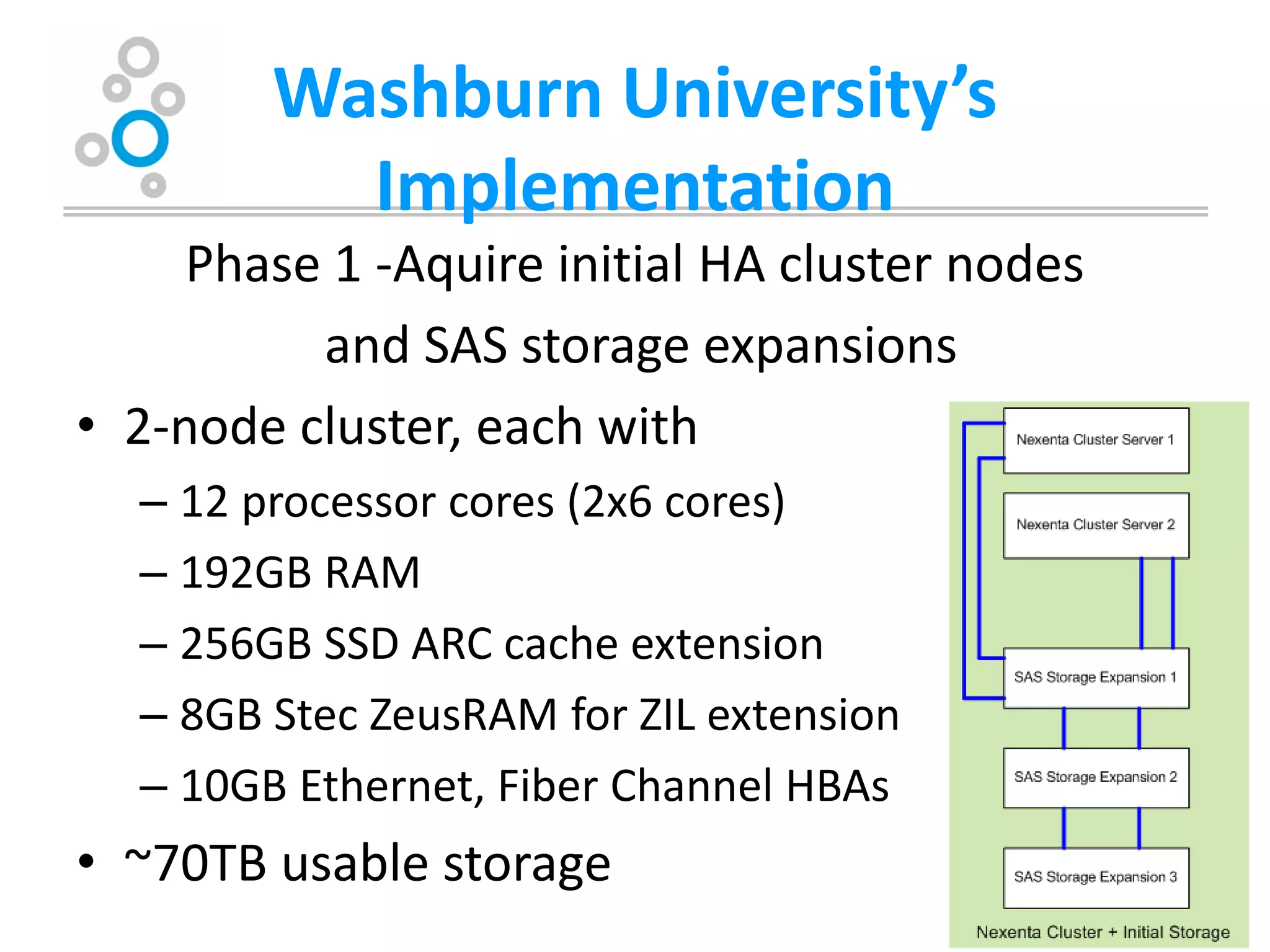
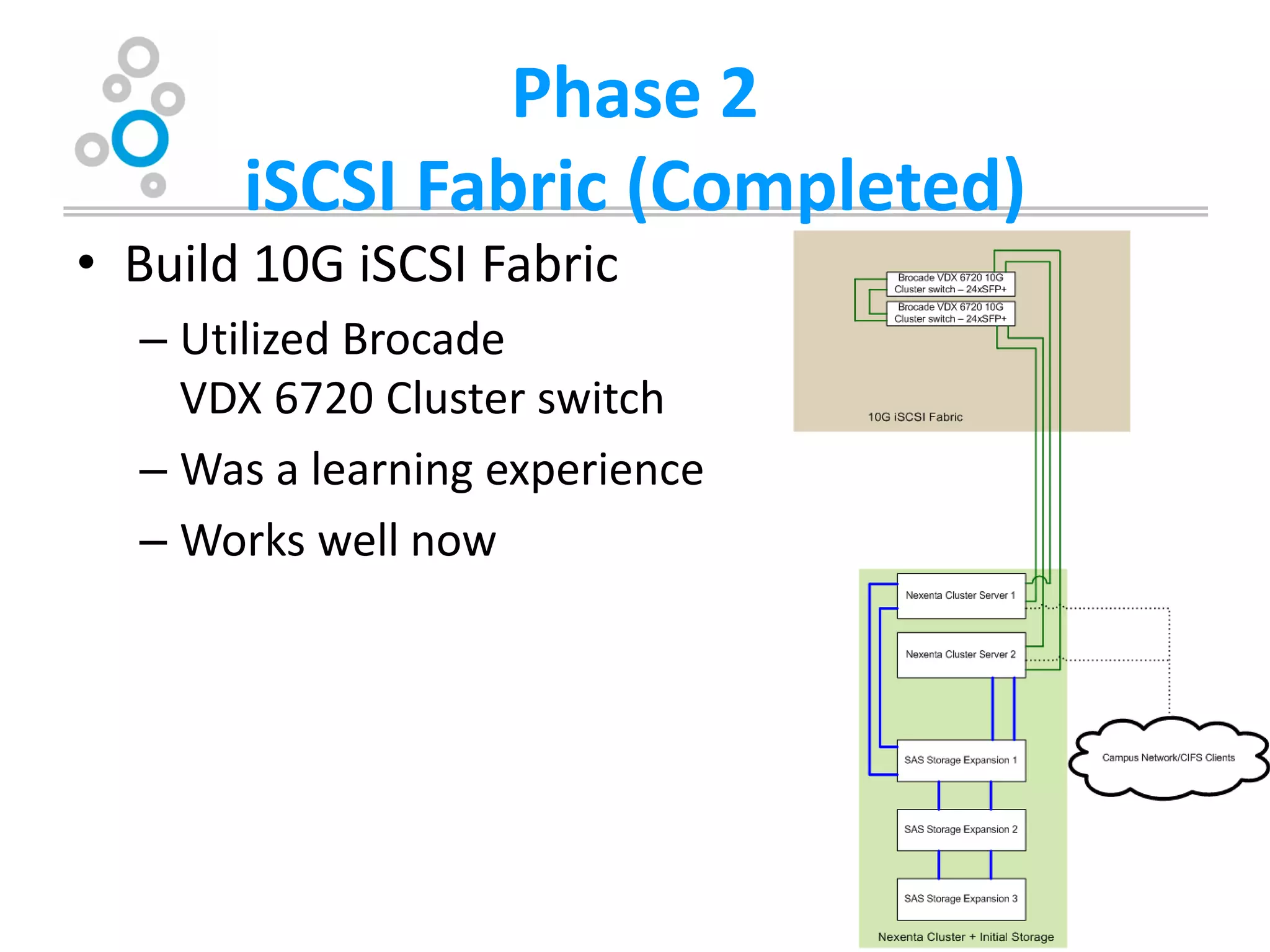
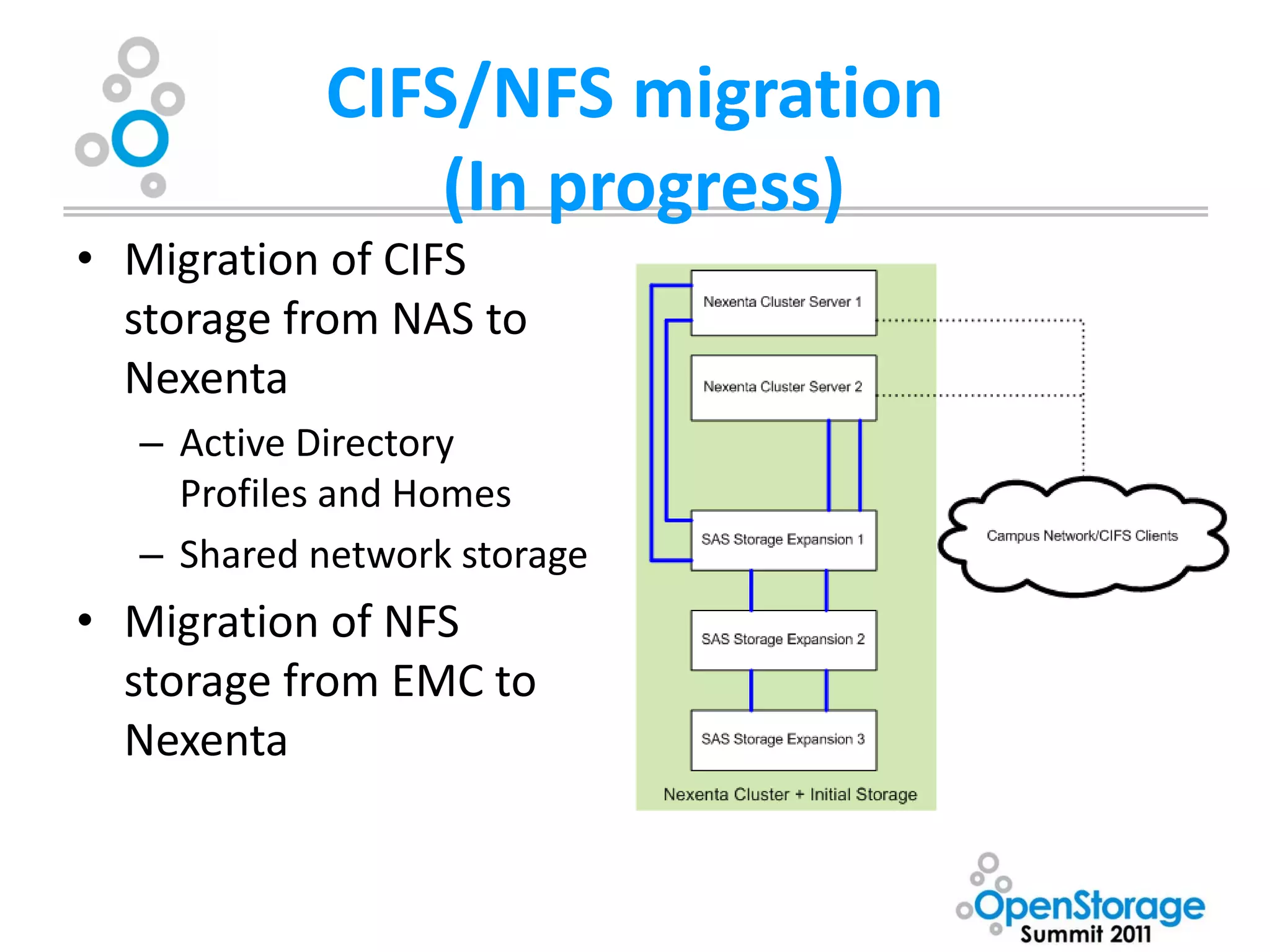
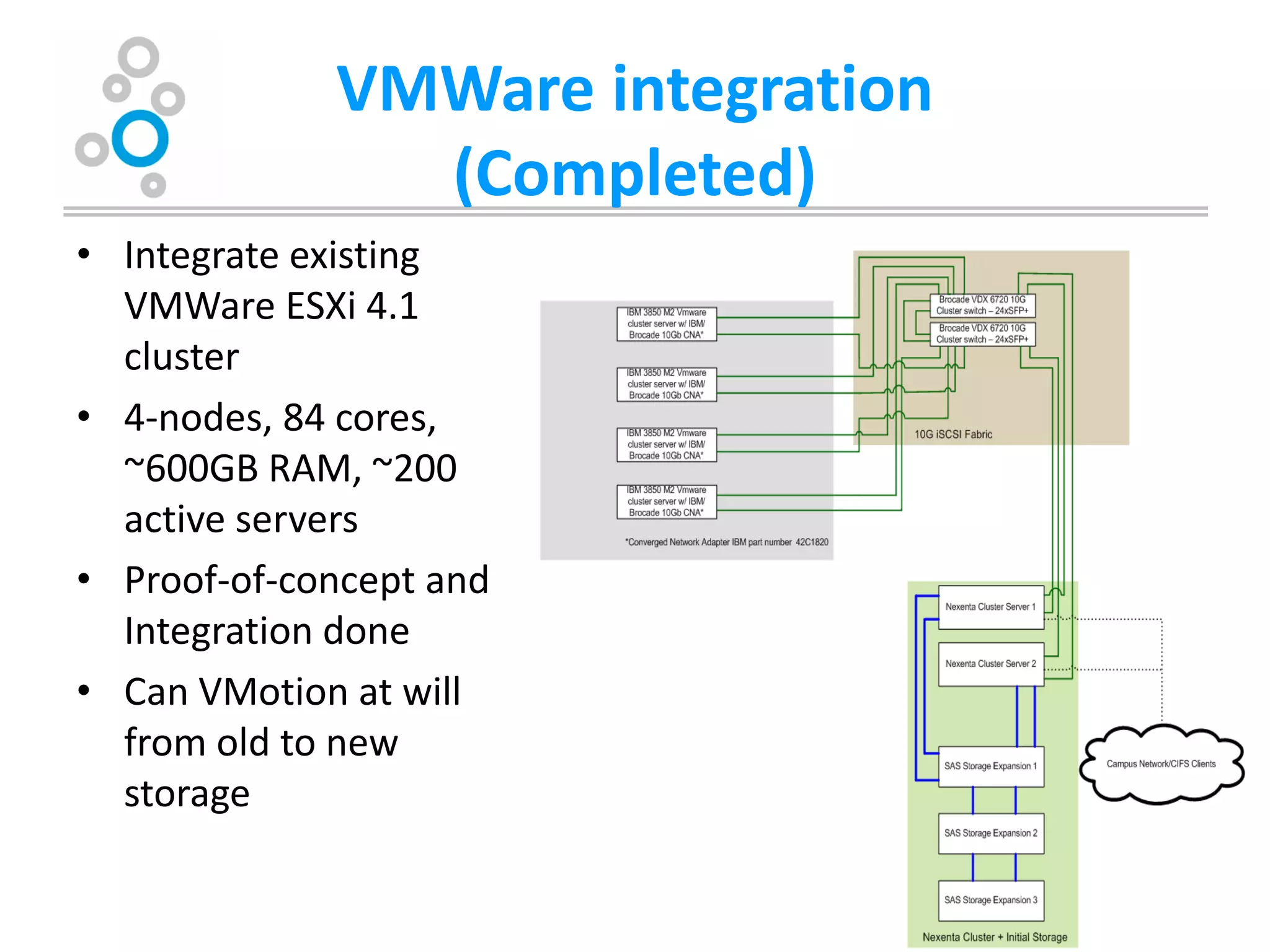
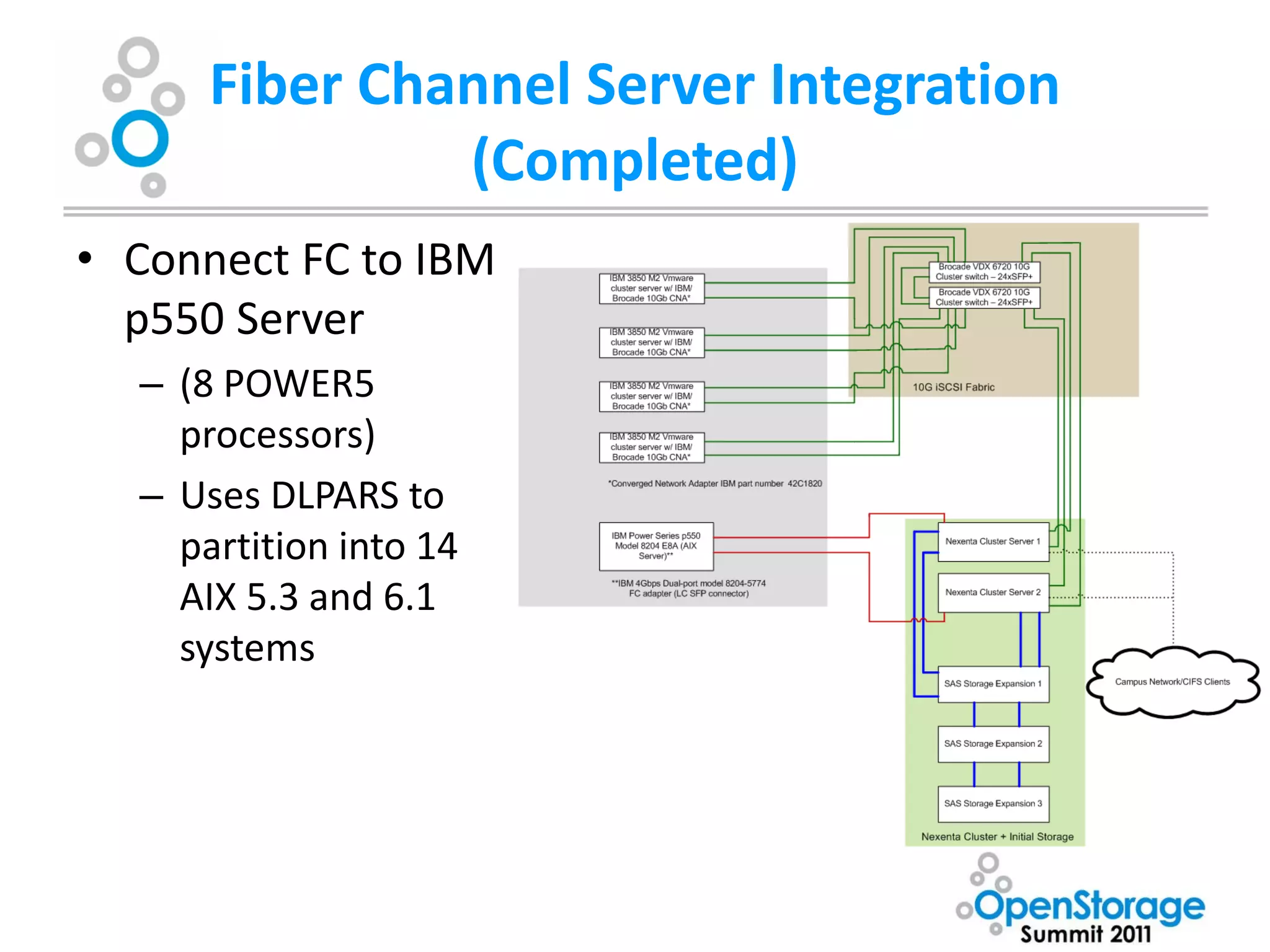
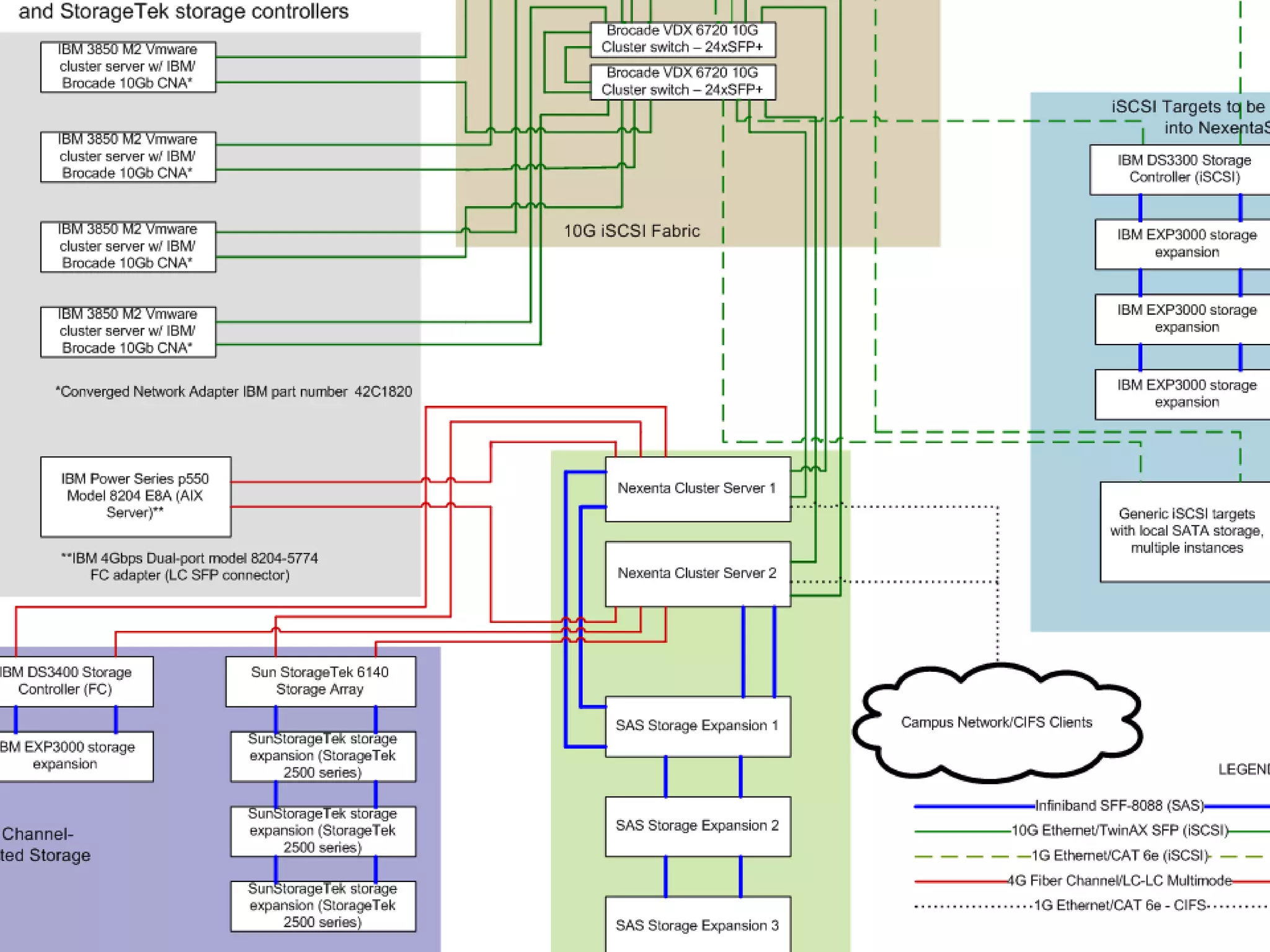
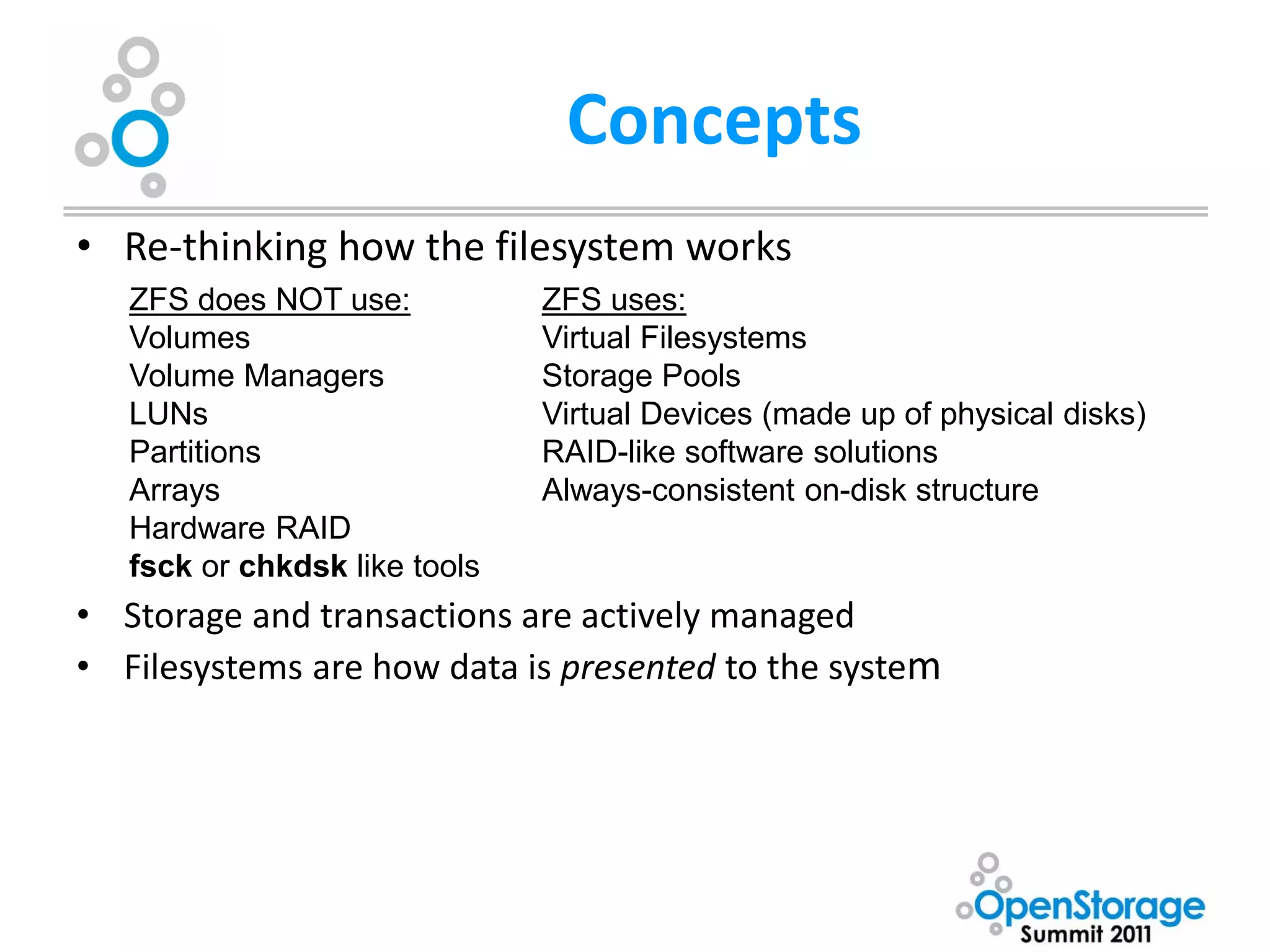
The document summarizes Washburn University's efforts to consolidate its enterprise storage using an open source storage solution called Nexenta. It describes the university's existing fragmented storage environment consisting of various vendors and protocols. The implementation plan involves acquiring an initial Nexenta cluster and storage expansions, building an iSCSI fabric, migrating CIFS/NFS storage, integrating VMware, and connecting a fiber channel server. The end goal is to manage all storage and backups through a single Nexenta interface using the data integrity and flexibility benefits of the ZFS file system.

















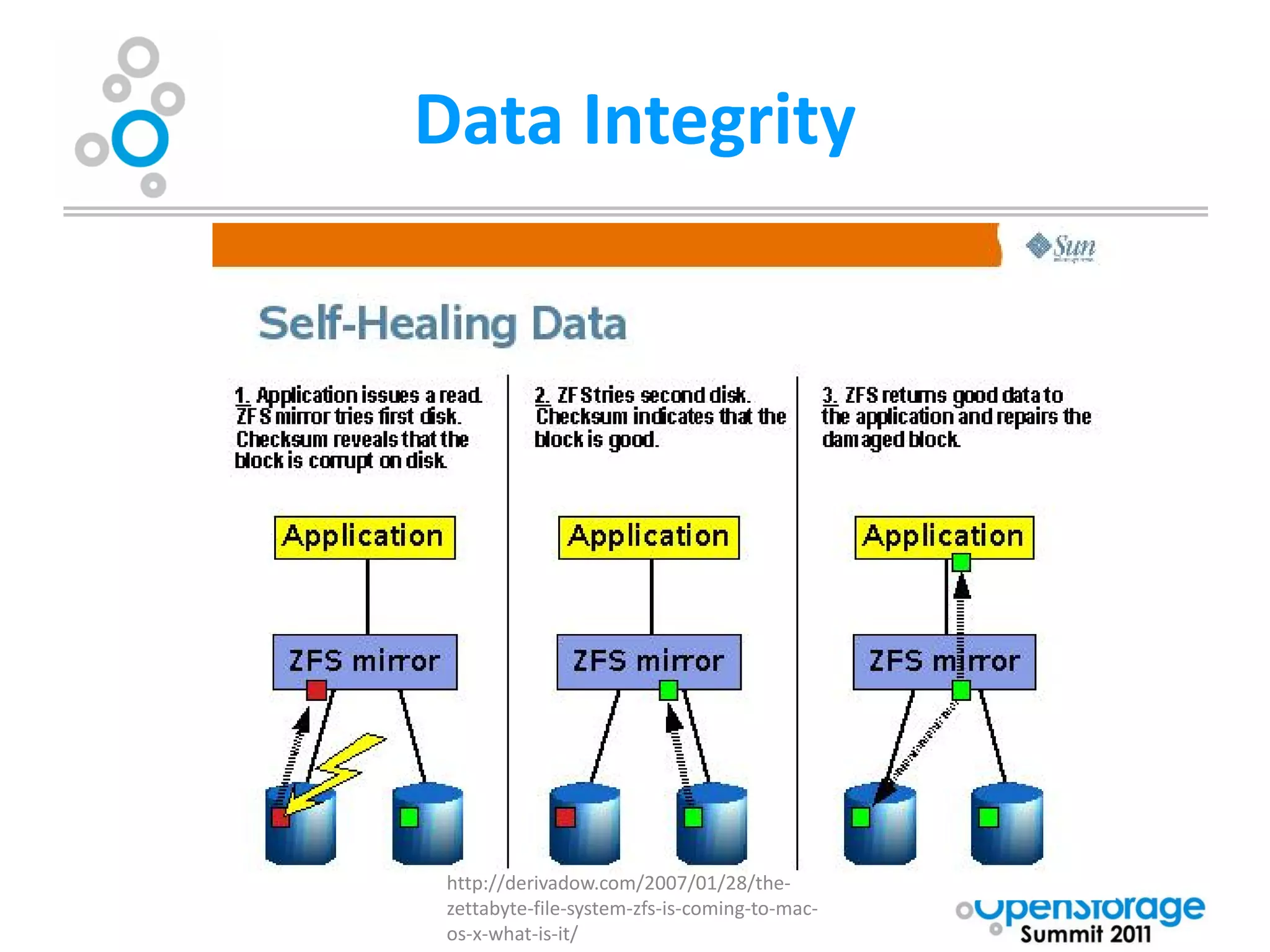
![Data Integrity
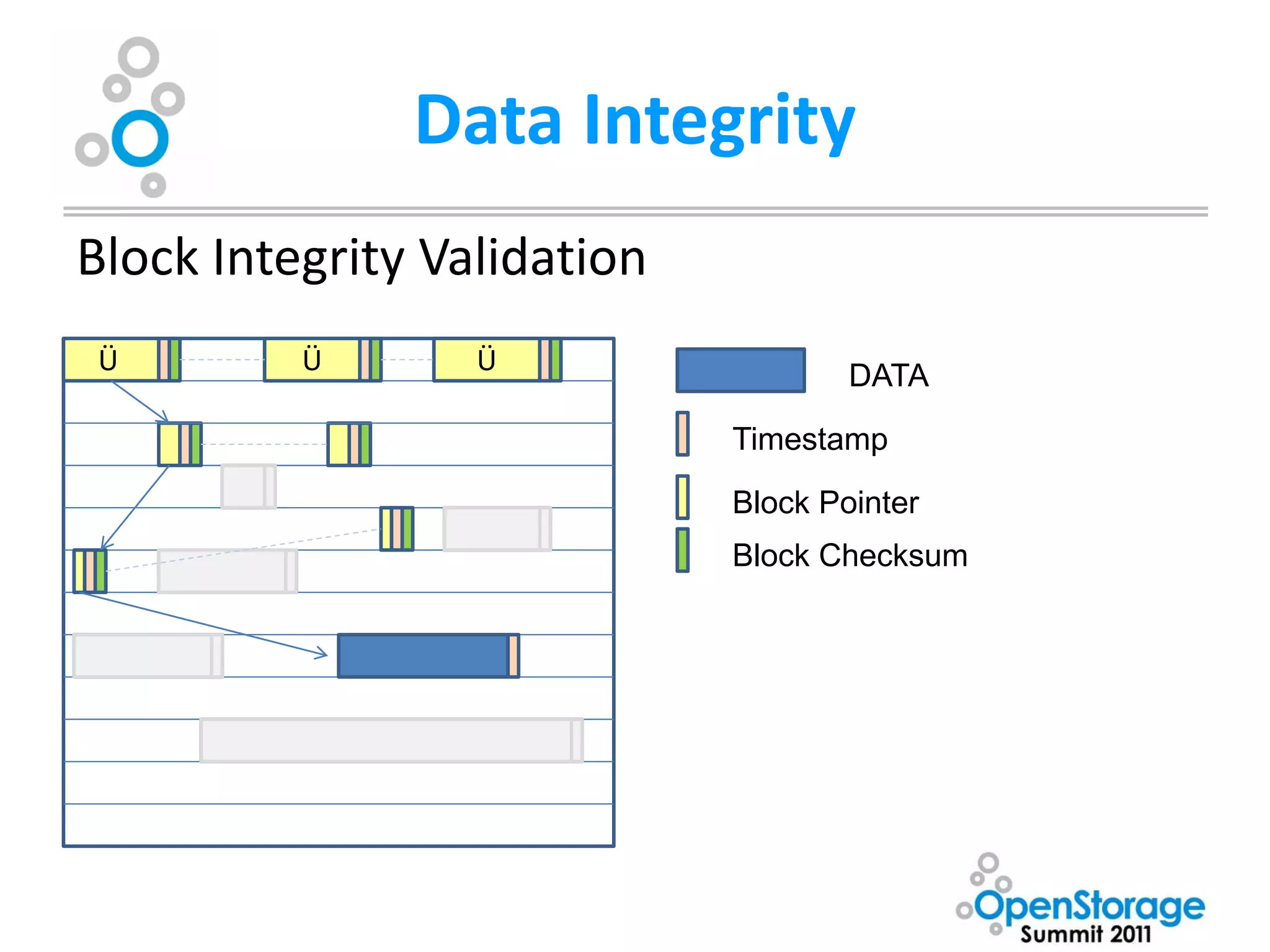
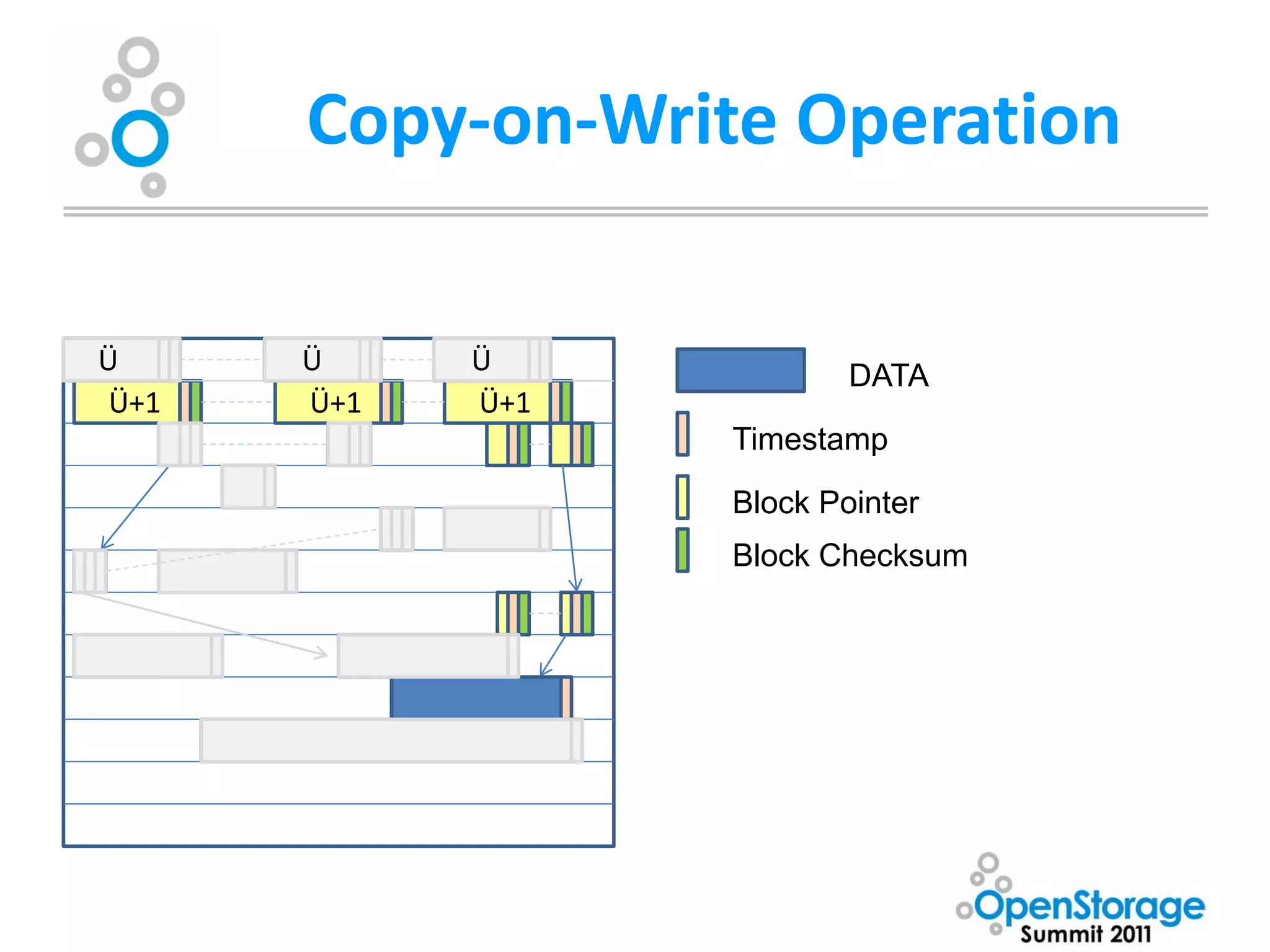
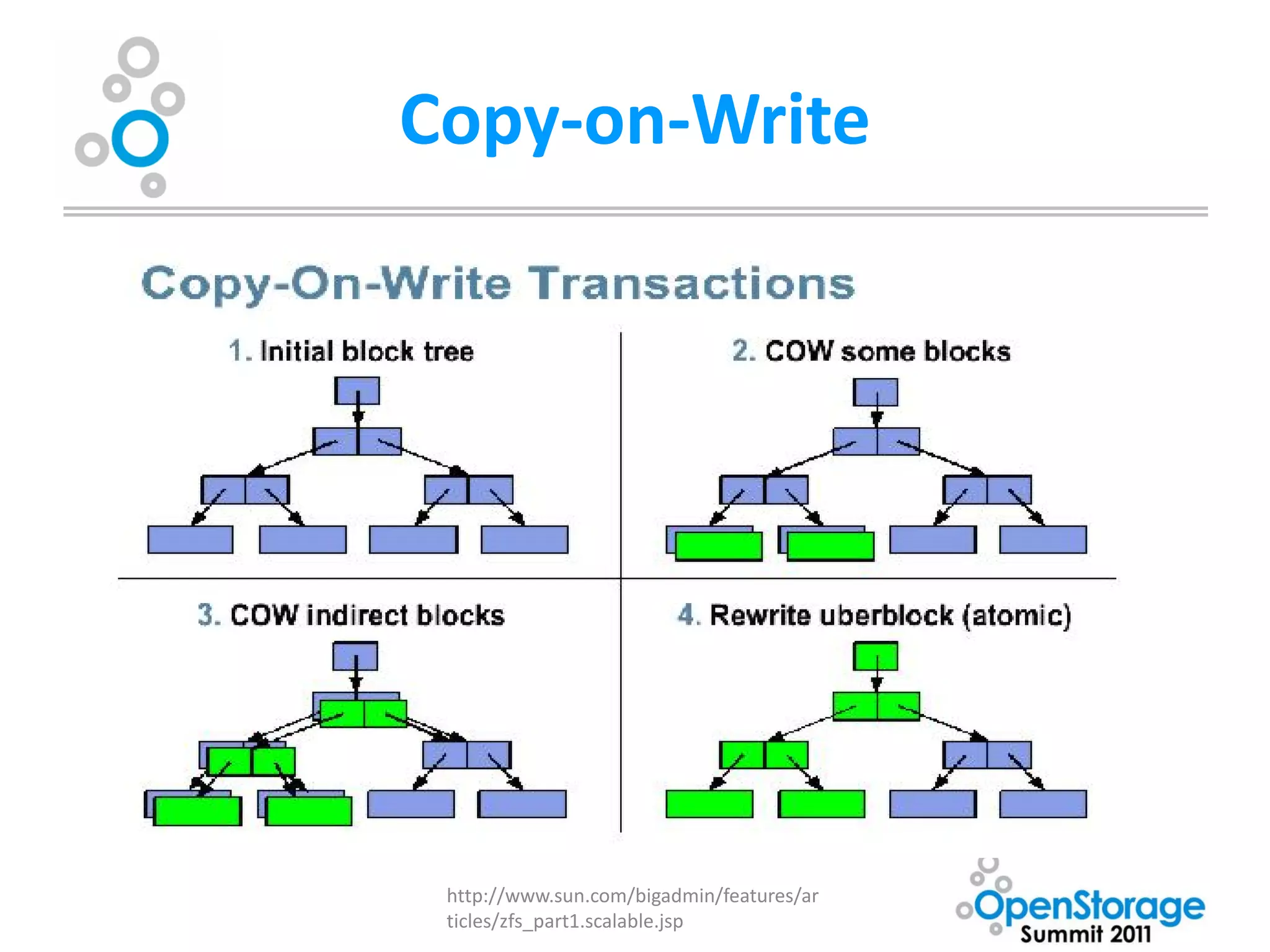
• Copy-on-Write transactional model+End-to-End
checksumming provides unparalleled data integrity
– Blocks are never overwritten in place. A new block is
allocated modified data is written to the new block,
metadata blocks are updated (also using copy-on-write
model) with new pointers. Blocks are only freed once all
Uberblock pointers have been updated. [Merkle tree]
– Multiple updates are grouped into transaction groups in
memory, ZFS Intent Log (ZIL) can be used for synchronous
writes (POSIX demands confirmation that data is on media
before telling the OS the operation was successful)
– Eliminates the need for journaling or logging filesystem,
utilities such as fsck/chkdsk](https://image.slidesharecdn.com/oss-kevinhalgrenwashburnuniv-111206150910-phpapp01/75/OSS-Presentation-by-Kevin-Halgren-31-2048.jpg)

![RAIDZ (continued)
• RAID-Z uses all drives for data and/or parity. Parity bits are assigned to
data blocks, blocks are spanned across multiple drives
• RAID-Z may span blocks across fewer than the total available drives. At
minimum, all blocks will spread across a number of disks equal to parity.
In a catastrophic failure of greater than [parity] number of disks, data may
still be recoverable.
• Resilvering (rebuilding a zDev when a drive is lost) is only performed
against actual data in use. Empty blocks are not processed.
• Blocks are checked against checksums to verify integrity of the data when
resilvering, there is no blind XOR as with standard RAID. Data errors are
corrected when resilvering.
• Interrupting the resilvering process does not require a restart from the
beginning.](https://image.slidesharecdn.com/oss-kevinhalgrenwashburnuniv-111206150910-phpapp01/75/OSS-Presentation-by-Kevin-Halgren-33-2048.jpg)




![Performance
• IOPS = 1000[ms/s] / (average read seek time [ms]) + (maximum rotational
latency [ms]/2))
– Basic physics, any higher numbers are a result of cache
– Rough numbers:
• 5400 RPM – 30-50 IOPS
• 7200 RPM – 60-80 IOPS
• 10000 RPM – 100-140 IOPS
• 15000 RPM – 150-190 IOPS
• SSD – Varies!
• Disk Throughput
– Highly variable, often little correlation to rotational speed. Typically 50-
100 MB/sec
– Significantly affected by block size (defaults 4K in NTFS, 128K in ZFS)](https://image.slidesharecdn.com/oss-kevinhalgrenwashburnuniv-111206150910-phpapp01/75/OSS-Presentation-by-Kevin-Halgren-39-2048.jpg)











































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)


![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)









