Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Masayoshi Kondo
PDF, PPTX
823 views
深層学習(岡本孝之 著)Deep learning Chap.4_2
深層学習(岡本孝之 著)の4章まとめ後半.これから深層学習を学びたい理系B4, M1向けの入門資料.実用目的よりも用語説明含めた基礎知識重視. 本スライドは、主に誤差逆伝搬法についての説明を行う.
Data & Analytics
◦
Related topics:
Deep Learning
•
Read more
3
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 26
2
/ 26
3
/ 26
4
/ 26
5
/ 26
6
/ 26
7
/ 26
8
/ 26
9
/ 26
10
/ 26
11
/ 26
12
/ 26
13
/ 26
14
/ 26
15
/ 26
16
/ 26
17
/ 26
18
/ 26
19
/ 26
20
/ 26
21
/ 26
22
/ 26
23
/ 26
24
/ 26
25
/ 26
26
/ 26
More Related Content
PDF
深層学習(岡本孝之 著)Deep learning chap.4_1
by
Masayoshi Kondo
PDF
深層学習(岡本 孝之 著)Deep learning chap.5_1
by
Masayoshi Kondo
PDF
深層学習(岡本孝之著) Deep learning chap.5_2
by
Masayoshi Kondo
PDF
深層学習(岡本孝之 著) - Deep Learning chap.3_2
by
Masayoshi Kondo
PDF
深層学習(岡本孝之 著) - Deep Learning chap.3_1
by
Masayoshi Kondo
PDF
深層学習(岡本孝之 著) - Deep Learning chap.1 and 2
by
Masayoshi Kondo
PDF
attention_is_all_you_need_nips17_論文紹介
by
Masayoshi Kondo
PPTX
Machine translation
by
Hiroshi Matsumoto
深層学習(岡本孝之 著)Deep learning chap.4_1
by
Masayoshi Kondo
深層学習(岡本 孝之 著)Deep learning chap.5_1
by
Masayoshi Kondo
深層学習(岡本孝之著) Deep learning chap.5_2
by
Masayoshi Kondo
深層学習(岡本孝之 著) - Deep Learning chap.3_2
by
Masayoshi Kondo
深層学習(岡本孝之 著) - Deep Learning chap.3_1
by
Masayoshi Kondo
深層学習(岡本孝之 著) - Deep Learning chap.1 and 2
by
Masayoshi Kondo
attention_is_all_you_need_nips17_論文紹介
by
Masayoshi Kondo
Machine translation
by
Hiroshi Matsumoto
Similar to 深層学習(岡本孝之 著)Deep learning Chap.4_2
PPTX
Deep learning chapter4 ,5
by
ShoKumada
PDF
SGDによるDeepLearningの学習
by
Masashi (Jangsa) Kawaguchi
PDF
Deep learning実装の基礎と実践
by
Seiya Tokui
PPTX
深層学習①
by
ssuser60e2a31
PDF
03_深層学習
by
CHIHIROGO
PDF
深層学習(講談社)のまとめ(1章~2章)
by
okku apot
PDF
20160329.dnn講演
by
Hayaru SHOUNO
PDF
20150310 第1回 ディープラーニング勉強会
by
哲朗 島田
PDF
ディープラーニング入門 ~ 画像処理・自然言語処理について ~
by
Kensuke Otsuki
PPTX
ラビットチャレンジレポート 深層学習 Day1
by
ssuserf4860b
PPTX
深層学習の数理
by
Taiji Suzuki
PDF
深層学習レポート Day1 (小川成)
by
ssuser441cb9
PDF
ディープニューラルネット入門
by
TanUkkii
PDF
lispmeetup#63 Common Lispでゼロから作るDeep Learning
by
Satoshi imai
PPTX
RBMを応用した事前学習とDNN学習
by
Masayuki Tanaka
PPTX
深層学習の基礎と導入
by
Kazuki Motohashi
PPTX
深層学習とTensorFlow入門
by
tak9029
PDF
深層学習 勉強会第1回 ディープラーニングの歴史とFFNNの設計
by
Yuta Sugii
PDF
TensorFlowによるニューラルネットワーク入門
by
Etsuji Nakai
PPT
Deep Learningの技術と未来
by
Seiya Tokui
Deep learning chapter4 ,5
by
ShoKumada
SGDによるDeepLearningの学習
by
Masashi (Jangsa) Kawaguchi
Deep learning実装の基礎と実践
by
Seiya Tokui
深層学習①
by
ssuser60e2a31
03_深層学習
by
CHIHIROGO
深層学習(講談社)のまとめ(1章~2章)
by
okku apot
20160329.dnn講演
by
Hayaru SHOUNO
20150310 第1回 ディープラーニング勉強会
by
哲朗 島田
ディープラーニング入門 ~ 画像処理・自然言語処理について ~
by
Kensuke Otsuki
ラビットチャレンジレポート 深層学習 Day1
by
ssuserf4860b
深層学習の数理
by
Taiji Suzuki
深層学習レポート Day1 (小川成)
by
ssuser441cb9
ディープニューラルネット入門
by
TanUkkii
lispmeetup#63 Common Lispでゼロから作るDeep Learning
by
Satoshi imai
RBMを応用した事前学習とDNN学習
by
Masayuki Tanaka
深層学習の基礎と導入
by
Kazuki Motohashi
深層学習とTensorFlow入門
by
tak9029
深層学習 勉強会第1回 ディープラーニングの歴史とFFNNの設計
by
Yuta Sugii
TensorFlowによるニューラルネットワーク入門
by
Etsuji Nakai
Deep Learningの技術と未来
by
Seiya Tokui
More from Masayoshi Kondo
PDF
Graph-to-Sequence Learning using Gated Graph Neural Networks. [ACL'18] 論文紹介
by
Masayoshi Kondo
PDF
GeneratingWikipedia_ICLR18_論文紹介
by
Masayoshi Kondo
PDF
Deep Learning
by
Masayoshi Kondo
PDF
Semantic_Matching_AAAI16_論文紹介
by
Masayoshi Kondo
PDF
最先端NLP勉強会2017_ACL17
by
Masayoshi Kondo
PDF
Get To The Point: Summarization with Pointer-Generator Networks_acl17_論文紹介
by
Masayoshi Kondo
PDF
Linguistic Knowledge as Memory for Recurrent Neural Networks_論文紹介
by
Masayoshi Kondo
Graph-to-Sequence Learning using Gated Graph Neural Networks. [ACL'18] 論文紹介
by
Masayoshi Kondo
GeneratingWikipedia_ICLR18_論文紹介
by
Masayoshi Kondo
Deep Learning
by
Masayoshi Kondo
Semantic_Matching_AAAI16_論文紹介
by
Masayoshi Kondo
最先端NLP勉強会2017_ACL17
by
Masayoshi Kondo
Get To The Point: Summarization with Pointer-Generator Networks_acl17_論文紹介
by
Masayoshi Kondo
Linguistic Knowledge as Memory for Recurrent Neural Networks_論文紹介
by
Masayoshi Kondo
深層学習(岡本孝之 著)Deep learning Chap.4_2
1.
深層学習 著:岡本 孝之 NAIST Computational Linguistic
Lab D1 Masayoshi Kondo 4章 –後半-‐‑‒
2.
00: はじめに 【⽬目的と狙い】 • Deep
Learningに興味があるけど詳しくは分からない理理系修⼠士学⽣生向け • 実⽤用的なことよりも基礎的知識識を重視 • 今後論論⽂文を読んで⾏行行く上での基礎体⼒力力を滋養し、各学⽣生の理理解速度度の向上が狙い 【ガイドライン】 • 「深層学習(講談社 : 岡本 貴之 著)」の本をまとめる形で発表 • 全8章の165ページから構成 • 本の内容に準拠(本に記載されていない内容・表現を知っている場合でも原則的 には記載を控える。あくまでも本の内容に忠実。) • ただし、適宜、参考⽂文献や関連論論⽂文等はあれば記載していくつもり • 理理系(情報⼯工学系)の⼤大学学部4年年⽣生が理理解できるくらいをイメージしてまとめる 今回 : 第4章
3.
XX: 緑のスライドとは? 書籍(本書)には記載されていないが、必要箇所の説明に際し 補助・追記として個⼈人的に記載が必要と思われた場合には、 緑⾊色のページに適宜載せることとする. •
本には載っていないけど、あえて追加説明したい場合は、 緑スライドに書くことにする. • 緑スライドに書かれる内容は本には記載されていない.
4.
00: はじめに 全8章 • 【第1章】はじめに •
【第2章】順伝搬型ネットワーク • 【第3章】確率率率的勾配降降下法 • 【第4章】誤差逆伝搬法 • 【第5章】⾃自⼰己符号化器 • 【第6章】畳込みニューラルネット(CNN) • 【第7章】再帰型ニューラルネット(RNN) • 【第8章】ボルツマンマシン
5.
00: はじめに –
これまでのまとめ (1・2章) -‐‑‒ 深層学習(Deep Learning) / ニューラルネット を使って分析するとは • ネットワークの構造 を決める • 活性化関数 を決める • 学習⽅方法(誤差関数と最適化法) を決める の3つを⾏行行うことである
6.
00: はじめに –
これまでのまとめ (3章) -‐‑‒ 深層学習・ニューラルネットワークを使⽤用することは、 • 学習時の過適合(overfitting) • 学習にかかる膨⼤大な計算時間 との戦い. 過適合を緩和する⽅方法と計算時間を縮⼩小する⼿手法を組み合わせて 現実的に解決可能な問題へ落落とし込む
7.
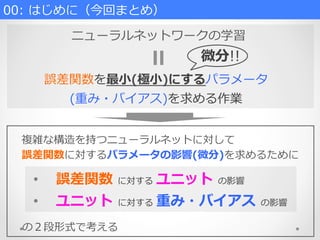
ニューラルネットワークの学習 誤差関数を最⼩小(極⼩小)にするパラメータ (重み・バイアス)を求める作業 • 誤差関数
に対する ユニット の影響 • ユニット に対する 重み・バイアス の影響 複雑な構造を持つニューラルネットに対して 誤差関数に対するパラメータの影響(微分)を求めるために 00: はじめに(今回まとめ) の2段形式で考える 微分!!
8.
第4章 誤差逆伝搬法 4.1 勾配計算の難しさ 4.2 2層ネットワークでの計算 4.3
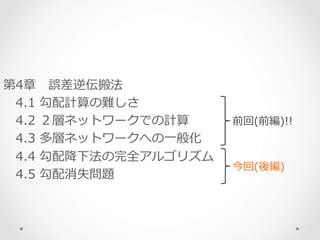
多層ネットワークへの⼀一般化 4.4 勾配降降下法の完全アルゴリズム 4.5 勾配消失問題 前回(前編)!! 今回(後編)
9.
第4章 誤差逆伝搬法 4.1 勾配計算の難しさ 4.2 2層ネットワークでの計算 4.3
多層ネットワークへの⼀一般化 4.4 勾配降降下法の完全アルゴリズム 4.5 勾配消失問題 前回まとめ
10.
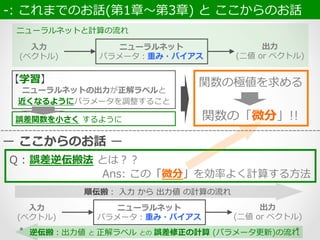
【学習】 ニューラルネットの出⼒力力が正解ラベルと 近くなるようにパラメータを調整すること ニューラルネット パラメータ:重み・バイアス ⼊入⼒力力 (ベクトル) 出⼒力力 (⼆二値 or ベクトル) -‐‑‒:
これまでのお話(第1章〜~第3章) と ここからのお話 ニューラルネットと計算の流流れ 誤差関数を⼩小さく するように 関数の極値を求める 関数の「微分」!! ー ここからのお話 ー Q : 誤差逆伝搬法 とは?? Ans: この「微分」を効率率率よく計算する⽅方法 ニューラルネット パラメータ:重み・バイアス ⼊入⼒力力 (ベクトル) 出⼒力力 (⼆二値 or ベクトル) 順伝搬: ⼊入⼒力力 から 出⼒力力値 の計算の流流れ 逆伝搬:出⼒力力値 と 正解ラベル との 誤差修正の計算 (パラメータ更更新)の流流れ
11.
DNNの学習(最適化) ∇E ≡ ∂E ∂w = ∂E ∂w1 !! ∂E ∂wM " # $ % & ' t w(t+1) = w(t) −ε∇E 勾配降降下法(第3章<前半>参照) 重みWに対する を求めれば良良いのね. ∂E ∂w 誤差逆伝搬法
(RNNは、BPTT法) ∂E ∂w ~∼ [誤差] [誤差]t ← h([誤差]t+1) [誤差]は、モデルの出⼒力力値と正解 ラベルの差から求めることが出来 そう. データを最も良良く表現する 重みWを求めること -‐‑‒: DNNの学習 ⼿手続き どうやって 求めんの? が求まれば、重みWを 更更新できる. ∇E どうやって 求めんの?
12.
1. 【順伝搬】z(1)=xnとして、各層lのユニット⼊入出⼒力力u(l)及びz(l)を順に計算. 2. 出⼒力力層でのδj (L)を求める. 3.
【逆伝搬】中間層l(=L-‐‑‒1, L-‐‑‒2, L-‐‑‒3,…,4 ,3, 2)でのδj (L)を、出⼒力力側から 下記の式に従って計算. 4. 各層l(=2, 3, 4,…,L-‐‑‒2 ,L-‐‑‒1 ,L)のパラメータwji (l)に関する微分を下記の式に 従って計算. δj (l) = δk (l+1) wkj (l+1) !f (uj (l) )( ) k ∑ ∂En ∂wji (l) =δj (l) zi (l−1) <誤差逆伝搬による誤差勾配の計算⼿手順> • これを伝搬 • ⼊入れ⼦子を回避 δj (l) ≡ ∂En ∂uj (l) # $ %% & ' (( -‐‑‒: 1分で分かる誤差逆伝搬法 (back propagation) 【3⾏行行まとめ】:誤差逆伝搬法 いちいち更更新パラメータの変化分(誤差)を計算しようとしたら、 ニューラルネットの⼊入⼒力力層に近いパラメータは活性化関数が⼊入れ⼦子になって怠いので、 隣隣接層の変化分(誤差)を利利⽤用して楽に計算できるようにした
13.
ミニバッチ等の複数の訓練サンプルに対する 誤差関数(誤差の総和)の勾配の求め⽅方 -‐‑‒: ミニバッチ等の複数の訓練サンプルの場合(まとめ) ミニバッチの誤差関数
= 各訓練サンプルの誤差関数の総和 E = En n ∑ 前スライドの誤差勾配に関する計算⼿手順を各訓練サンプル毎に平⾏行行に計算し、 得られる各勾配を下記の式が⽰示す和として求める. ∂E ∂wji (l) = ∂En ∂wij (l) n ∑
14.
第4章 誤差逆伝搬法 4.1 勾配計算の難しさ 4.2 2層ネットワークでの計算 4.3
多層ネットワークへの⼀一般化 4.4 勾配降降下法の完全アルゴリズム 4.5 勾配消失問題
15.
01: 勾配下降降法の完全アルゴリズム 4.4.1 出⼒力力層でのデルタ 逆伝搬計算の起点は、出⼒力力層でのδ.
δの計算は、使⽤用する誤差関数と出⼒力力層の活性化関数に依存. 【代表例例】 [ 回帰 ] [ ⼆二値分類 ] • 誤差関数:⼆二乗誤差 ( ) • 出⼒力力層の活性化関数:恒等写像 ( ) En = 1 2 yj − dj( ) j ∑ 2 yj = zj (L) = uj (L) δj (L) = yj − dj • 誤差関数: • 出⼒力力層の活性化関数:ロジスティック関数 ( ) En = d log y +(1− d)log(1− y) y = 1 1+exp(−u) δ(L) = d − y
16.
02: 勾配下降降法の完全アルゴリズム 4.4.1 出⼒力力層でのデルタ 【代表例例】 •
誤差関数:交差エントロピー ( ) • 出⼒力力層の活性化関数:ソフトマックス関数( ) En = − dk log yk k ∑ δj (L) = yj − dj yk = exp(uk (L) ) exp(ui (L) ) i ∑ [ 多クラス分類 ] 回帰・⼆二値分類・多クラス分類 のいずれにおいても、 出⼒力力層のユニットδは、ネットワークの出⼒力力と⽬目標出⼒力力の差で 計算可能
17.
03: 勾配下降降法の完全アルゴリズム 4.4.2 順伝搬と逆伝搬の⾏行行列列計算 ミニバッチを⽤用いた確率率率的勾配降降下法の全計算を⾏行行列列を⽤用いて表記 【記号
⼀一覧】 X = x1,!, xN[ ] b Z(l) = z1 (l) ,!, zN (l)!" #$ D = d1,!,dN[ ] U(l) = u1 (l) ,!,uN (l)!" #$ W Y = y1,!, yN[ ] : サンプルを列列ベクトルに持つ⾏行行列列 : サンプルに対応する⽬目標出⼒力力 : サンプルxnを⼊入⼒力力した時の第l層の各ユニットにおける 総⼊入⼒力力を成分に並べたベクトルun (j)を列列ベクトルとする⾏行行列列 : un (l)に活性化関数を作⽤用させた各ユニットの出⼒力力の成分を 並べたベクトルzn (l)を列列ベクトルとする⾏行行列列 : i≧1の重みwijを(j, i)成分に持つ⾏行行列列 : サンプルに対する出⼒力力 : バイアスのベクトル
18.
04: 勾配下降降法の完全アルゴリズム 4.4.2 順伝搬と逆伝搬の⾏行行列列計算 <順伝搬
計算> U(l) = W(l) Z(l−1) + b(l) 1N t 順伝搬計算は、 として について、 上記の2つの式の計算を反復復することで実現. Z(l) = f (l) (U(l) ) U(1) ≡ X l =1,2,!, L
19.
05: 勾配下降降法の完全アルゴリズム 4.4.2 順伝搬と逆伝搬の⾏行行列列計算 <逆伝搬
計算> Δ(l) Δ(l) = !f (l) (U(l) )• W(l+1)!" #$ t Δ(l+1) ( ) : 第l層の各ユニットのデルタ δj (l) を要素に持つ⾏行行列列 (⾏行行:第l層の各ユニット,列列:ミニバッチのサンプルn=1,2,…,Nに対応) Δ(L) = D −Y (ドット積は、⾏行行列列の各成分毎の積) -‐‑‒ 活性化関数の微分について 活性化関数 f(u) fʼ’(u) ロジスティック関数 双曲線正接関数 正規化線形関数 (出⼒力力層の誤差計算) (中間層の誤差計算) !f (u) = 1 (u ≥ 0) 0 (u < 0) # $ % & % f (u) = tanh(u) f (u) = max(u,0) f (u) = 1 1+e−u !f (u) =1− tanh2 (u) !f (u) = f (u)(1− f (u)) 1. デルタ (誤差)の計算Δ(l)
20.
06: 勾配下降降法の完全アルゴリズム 4.4.2 順伝搬と逆伝搬の⾏行行列列計算 <逆伝搬
計算> Δ(l) 2. を⽤用いて誤差関数の勾配を計算 ∂W(l) = 1 N Δ(l) Z(l−1)$% &' t ∂W(l) ∂b(l) : 重みwji (l)に関する誤差関数の微分を(j,i)成分に持つ⾏行行列列 : バイアスbj (l)についての微分をj成分に持つベクトル ∂b(l) = 1 N Δ(l) 1N t ΔW(l) = −ε∂W(l) Δb(l) = −ε∂b(l) , は、各層l=1,2,…,L について平⾏行行に計算できる. ∂b(l) ∂W(l) 勾配降降下⽅方向に更更新するための更更新量量 を上記のように決定する. (εは定数 / , は前回更更新量量) ΔW(l) = µΔW(l ") −ε(∂W(l) + λW(l) ) Δb(l) = µΔb(l ") −ε∂b(l) [ 重み減衰・モメンタム 有り ] ΔW(l ") Δb(l ")
21.
07: 勾配下降降法の完全アルゴリズム 4.4.2 順伝搬と逆伝搬の⾏行行列列計算 <逆伝搬
計算> 3. パラメータ(重み・バイアス)の更更新を⾏行行う W(l) ← W(l) + ΔW(l) b(l) ← b(l) + Δb(l)
22.
勾配を数値微分で計算・両者を⽐比較 誤差関数Eの勾配の差分近似(difference approximation) • ε→0の極限をとると、偏微分 の定義に⼀一致. •
εの値は近似の精度度が良良くなるように⼗十分⼩小さな値を選択する必要がある. • εの値があまり⼩小さすぎても、打ち切切り誤差や丸め誤差が⽣生じ、逆に誤差 が⼤大きくなる. ∂E ∂wji (l) = E(!,wij (l) +ε,!)− E(!,wij (l) ,!) ε 08: 勾配下降降法の完全アルゴリズム 4.4.2 勾配の差分近似計算 ネットワークの構造や活性化関数によってはプログラムがかなり複雑になる 誤差関数の勾配が正しく計算されているかを検証したい ∂E(w) ∂wji (l) E(!,wij (l) +ε,!) という表記は、変数 wのうち だけに εを加算するという 意味. wji (l)
23.
誤差関数Eの勾配の差分近似(difference approximation) ⼀一般的にεの値は、 ε ≡
ε0 wji と選ぶことが多い. (ε0は計算機イプシロン.計算機イプシロンとは、「計算機の浮動⼩小数点数で表現しうる 1より⼤大きい最⼩小の数と1との差のこと.) 上記の式の右辺を評価した際にε=0となる場合は、 ε ≡ ε0 09: 勾配下降降法の完全アルゴリズム 4.4.2 勾配の差分近似計算 と設定し直す.
24.
第4章 誤差逆伝搬法 4.1 勾配計算の難しさ 4.2 2層ネットワークでの計算 4.3
多層ネットワークへの⼀一般化 4.4 勾配降降下法の完全アルゴリズム 4.5 勾配消失問題
25.
多層ネットワークでは特に深刻な問題となり、学習する上で最⼤大の障害 • 各層の重みが⼤大きいとΔは各層を伝搬する過程で急速に⼤大きくなる(発散). • 逆に、重みが⼩小さいとΔは急速に消失し0になる. Δ(l) =
!f (l) (U(l) )• W(l+1)!" #$ t Δ(l+1) ( ) 10: 勾配消失問題(Vanishing gradient problem) 順伝搬と逆伝搬の違い 順伝搬: ⾮非線形計算 逆伝搬: 線形計算 Δの計算は出⼒力力層から⼊入⼒力力層に向かって全体が線形の計算となる. 重みの更更新が上⼿手く⾏行行えなくなり、学習が困難 【解決】:事前学習(pretraining)
26.
終わり
Download








![DNNの学習(最適化)
∇E ≡
∂E
∂w
=
∂E
∂w1
!!
∂E
∂wM
"
#
$
%
&
'
t
w(t+1)
= w(t)
−ε∇E
勾配降降下法(第3章<前半>参照)
重みWに対する
を求めれば良良いのね.
∂E
∂w
誤差逆伝搬法 (RNNは、BPTT法)
∂E
∂w
~∼ [誤差]
[誤差]t ← h([誤差]t+1)
[誤差]は、モデルの出⼒力力値と正解
ラベルの差から求めることが出来
そう.
データを最も良良く表現する
重みWを求めること
-‐‑‒: DNNの学習 ⼿手続き
どうやって
求めんの?
が求まれば、重みWを
更更新できる.
∇E
どうやって
求めんの?](https://image.slidesharecdn.com/deeplearning4after-170428090915/85/Deep-learning-Chap-4_2-11-320.jpg)



![01: 勾配下降降法の完全アルゴリズム
4.4.1 出⼒力力層でのデルタ
逆伝搬計算の起点は、出⼒力力層でのδ.
δの計算は、使⽤用する誤差関数と出⼒力力層の活性化関数に依存.
【代表例例】
[ 回帰 ]
[ ⼆二値分類 ]
• 誤差関数:⼆二乗誤差 ( )
• 出⼒力力層の活性化関数:恒等写像 ( )
En =
1
2
yj − dj( )
j
∑
2
yj = zj
(L)
= uj
(L)
δj
(L)
= yj − dj
• 誤差関数:
• 出⼒力力層の活性化関数:ロジスティック関数 ( )
En = d log y +(1− d)log(1− y)
y =
1
1+exp(−u)
δ(L)
= d − y](https://image.slidesharecdn.com/deeplearning4after-170428090915/85/Deep-learning-Chap-4_2-15-320.jpg)
![02: 勾配下降降法の完全アルゴリズム
4.4.1 出⼒力力層でのデルタ
【代表例例】
• 誤差関数:交差エントロピー ( )
• 出⼒力力層の活性化関数:ソフトマックス関数( )
En = − dk log yk
k
∑
δj
(L)
= yj − dj
yk =
exp(uk
(L)
)
exp(ui
(L)
)
i
∑
[ 多クラス分類 ]
回帰・⼆二値分類・多クラス分類 のいずれにおいても、
出⼒力力層のユニットδは、ネットワークの出⼒力力と⽬目標出⼒力力の差で
計算可能](https://image.slidesharecdn.com/deeplearning4after-170428090915/85/Deep-learning-Chap-4_2-16-320.jpg)
![03: 勾配下降降法の完全アルゴリズム
4.4.2 順伝搬と逆伝搬の⾏行行列列計算
ミニバッチを⽤用いた確率率率的勾配降降下法の全計算を⾏行行列列を⽤用いて表記
【記号 ⼀一覧】
X = x1,!, xN[ ]
b
Z(l)
= z1
(l)
,!, zN
(l)!" #$
D = d1,!,dN[ ]
U(l)
= u1
(l)
,!,uN
(l)!" #$
W
Y = y1,!, yN[ ]
: サンプルを列列ベクトルに持つ⾏行行列列
: サンプルに対応する⽬目標出⼒力力
: サンプルxnを⼊入⼒力力した時の第l層の各ユニットにおける
総⼊入⼒力力を成分に並べたベクトルun
(j)を列列ベクトルとする⾏行行列列
: un
(l)に活性化関数を作⽤用させた各ユニットの出⼒力力の成分を
並べたベクトルzn
(l)を列列ベクトルとする⾏行行列列
: i≧1の重みwijを(j, i)成分に持つ⾏行行列列
: サンプルに対する出⼒力力
: バイアスのベクトル](https://image.slidesharecdn.com/deeplearning4after-170428090915/85/Deep-learning-Chap-4_2-17-320.jpg)


![06: 勾配下降降法の完全アルゴリズム
4.4.2 順伝搬と逆伝搬の⾏行行列列計算
<逆伝搬 計算>
Δ(l)
2. を⽤用いて誤差関数の勾配を計算
∂W(l)
=
1
N
Δ(l)
Z(l−1)$% &'
t
∂W(l)
∂b(l)
: 重みwji
(l)に関する誤差関数の微分を(j,i)成分に持つ⾏行行列列
: バイアスbj
(l)についての微分をj成分に持つベクトル
∂b(l)
=
1
N
Δ(l)
1N
t
ΔW(l)
= −ε∂W(l)
Δb(l)
= −ε∂b(l)
, は、各層l=1,2,…,L
について平⾏行行に計算できる.
∂b(l)
∂W(l) 勾配降降下⽅方向に更更新するための更更新量量
を上記のように決定する.
(εは定数 / , は前回更更新量量)
ΔW(l)
= µΔW(l ")
−ε(∂W(l)
+ λW(l)
)
Δb(l)
= µΔb(l ")
−ε∂b(l)
[ 重み減衰・モメンタム 有り ]
ΔW(l ")
Δb(l ")](https://image.slidesharecdn.com/deeplearning4after-170428090915/85/Deep-learning-Chap-4_2-20-320.jpg)



































![Graph-to-Sequence Learning using Gated Graph Neural Networks. [ACL'18] 論文紹介](https://cdn.slidesharecdn.com/ss_thumbnails/graph2sequencelearningusinggatedgraphneuralnetworkacl18-190507010338-thumbnail.jpg?width=640&height=640&fit=bounds)





