Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Masayoshi Kondo
PDF, PPTX
420 views
深層学習(岡本孝之 著) - Deep Learning chap.3_2
深層学習(岡本孝之 著)の3章まとめ後半.これから深層学習を学びたい理系学生B4, M1向け入門資料.実用目的よりも用語説明含む基礎知識重視,
Data & Analytics
◦
Related topics:
Deep Learning
•
Read more
2
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 18
2
/ 18
3
/ 18
4
/ 18
5
/ 18
6
/ 18
7
/ 18
8
/ 18
9
/ 18
10
/ 18
11
/ 18
12
/ 18
13
/ 18
14
/ 18
15
/ 18
16
/ 18
17
/ 18
18
/ 18
More Related Content
PDF
深層学習(岡本孝之著) Deep learning chap.5_2
by
Masayoshi Kondo
PDF
深層学習(岡本孝之 著)Deep learning chap.4_1
by
Masayoshi Kondo
PDF
深層学習(岡本 孝之 著)Deep learning chap.5_1
by
Masayoshi Kondo
PDF
深層学習(岡本孝之 著)Deep learning Chap.4_2
by
Masayoshi Kondo
PDF
深層学習(岡本孝之 著) - Deep Learning chap.1 and 2
by
Masayoshi Kondo
PDF
深層学習(岡本孝之 著) - Deep Learning chap.3_1
by
Masayoshi Kondo
PDF
attention_is_all_you_need_nips17_論文紹介
by
Masayoshi Kondo
PPTX
Machine translation
by
Hiroshi Matsumoto
深層学習(岡本孝之著) Deep learning chap.5_2
by
Masayoshi Kondo
深層学習(岡本孝之 著)Deep learning chap.4_1
by
Masayoshi Kondo
深層学習(岡本 孝之 著)Deep learning chap.5_1
by
Masayoshi Kondo
深層学習(岡本孝之 著)Deep learning Chap.4_2
by
Masayoshi Kondo
深層学習(岡本孝之 著) - Deep Learning chap.1 and 2
by
Masayoshi Kondo
深層学習(岡本孝之 著) - Deep Learning chap.3_1
by
Masayoshi Kondo
attention_is_all_you_need_nips17_論文紹介
by
Masayoshi Kondo
Machine translation
by
Hiroshi Matsumoto
Similar to 深層学習(岡本孝之 著) - Deep Learning chap.3_2
PPTX
Hello deeplearning!
by
T2C_
PDF
数学で解き明かす深層学習の原理
by
Taiji Suzuki
PPTX
「機械学習とは?」から始める Deep learning実践入門
by
Hideto Masuoka
PDF
深層学習(講談社)のまとめ(1章~2章)
by
okku apot
PDF
Gakusei lt
by
TomoyukiHirose2
PDF
Generative deeplearning #02
by
逸人 米田
PDF
強化学習とは (MIJS 分科会資料 2016/10/11)
by
Akihiro HATANAKA
PDF
Recurrent Neural Networks
by
Seiya Tokui
PDF
深層学習 勉強会 第1回資料(作成途中)
by
Shuuji Mihara
PDF
20160329.dnn講演
by
Hayaru SHOUNO
PDF
ディープニューラルネット入門
by
TanUkkii
PDF
[DL輪読会]Shaping Belief States with Generative Environment Models for RL
by
Deep Learning JP
PDF
ラビットチャレンジ Day3 day4レポート
by
KazuyukiMasada
PDF
dl-with-python01_handout
by
Shin Asakawa
PDF
Deep Learningの基礎と応用
by
Seiya Tokui
PPTX
[DL輪読会]Learning to Adapt: Meta-Learning for Model-Based Control
by
Deep Learning JP
PDF
03_深層学習
by
CHIHIROGO
PDF
20150310 第1回 ディープラーニング勉強会
by
哲朗 島田
PDF
Deep learningの軽い紹介
by
Yoshihisa Maruya
PPTX
深層学習よもやま話
by
Hiroshi Maruyama
Hello deeplearning!
by
T2C_
数学で解き明かす深層学習の原理
by
Taiji Suzuki
「機械学習とは?」から始める Deep learning実践入門
by
Hideto Masuoka
深層学習(講談社)のまとめ(1章~2章)
by
okku apot
Gakusei lt
by
TomoyukiHirose2
Generative deeplearning #02
by
逸人 米田
強化学習とは (MIJS 分科会資料 2016/10/11)
by
Akihiro HATANAKA
Recurrent Neural Networks
by
Seiya Tokui
深層学習 勉強会 第1回資料(作成途中)
by
Shuuji Mihara
20160329.dnn講演
by
Hayaru SHOUNO
ディープニューラルネット入門
by
TanUkkii
[DL輪読会]Shaping Belief States with Generative Environment Models for RL
by
Deep Learning JP
ラビットチャレンジ Day3 day4レポート
by
KazuyukiMasada
dl-with-python01_handout
by
Shin Asakawa
Deep Learningの基礎と応用
by
Seiya Tokui
[DL輪読会]Learning to Adapt: Meta-Learning for Model-Based Control
by
Deep Learning JP
03_深層学習
by
CHIHIROGO
20150310 第1回 ディープラーニング勉強会
by
哲朗 島田
Deep learningの軽い紹介
by
Yoshihisa Maruya
深層学習よもやま話
by
Hiroshi Maruyama
More from Masayoshi Kondo
PDF
Graph-to-Sequence Learning using Gated Graph Neural Networks. [ACL'18] 論文紹介
by
Masayoshi Kondo
PDF
GeneratingWikipedia_ICLR18_論文紹介
by
Masayoshi Kondo
PDF
Deep Learning
by
Masayoshi Kondo
PDF
Semantic_Matching_AAAI16_論文紹介
by
Masayoshi Kondo
PDF
最先端NLP勉強会2017_ACL17
by
Masayoshi Kondo
PDF
Get To The Point: Summarization with Pointer-Generator Networks_acl17_論文紹介
by
Masayoshi Kondo
PDF
Linguistic Knowledge as Memory for Recurrent Neural Networks_論文紹介
by
Masayoshi Kondo
Graph-to-Sequence Learning using Gated Graph Neural Networks. [ACL'18] 論文紹介
by
Masayoshi Kondo
GeneratingWikipedia_ICLR18_論文紹介
by
Masayoshi Kondo
Deep Learning
by
Masayoshi Kondo
Semantic_Matching_AAAI16_論文紹介
by
Masayoshi Kondo
最先端NLP勉強会2017_ACL17
by
Masayoshi Kondo
Get To The Point: Summarization with Pointer-Generator Networks_acl17_論文紹介
by
Masayoshi Kondo
Linguistic Knowledge as Memory for Recurrent Neural Networks_論文紹介
by
Masayoshi Kondo
深層学習(岡本孝之 著) - Deep Learning chap.3_2
1.
深層学習 著:岡本 孝之 NAIST Computational Linguistic
Lab D1 Masayoshi Kondo 3章 –後半-‐‑‒
2.
00: はじめに 【⽬目的と狙い】 • Deep
Learningに興味があるけど詳しくは分からない理理系修⼠士学⽣生向け • 実⽤用的なことよりも基礎的知識識を重視 • 今後論論⽂文を読んで⾏行行く上での基礎体⼒力力を滋養し、各学⽣生の理理解速度度の向上が狙い 【ガイドライン】 • 「深層学習(講談社 : 岡本 貴之 著)」の本をまとめる形で発表 • 全8章の165ページから構成 • 本の内容に準拠(本に記載されていない内容・表現を知っている場合でも原則的 には記載を控える。あくまでも本の内容に忠実。) • ただし、適宜、参考⽂文献や関連論論⽂文等はあれば記載していくつもり • 理理系(情報⼯工学系)の⼤大学学部4年年⽣生が理理解できるくらいをイメージしてまとめる 今回 : 第3章
3.
XX: 緑のスライドとは? 書籍(本書)には記載されていないが、必要箇所の説明に際し 補助・追記として個⼈人的に記載が必要と思われた場合には、 緑⾊色のページに適宜載せることとする. •
本には載っていないけど、あえて追加説明したい場合は、 緑スライドに書くことにする. • 緑スライドに書かれる内容は本には記載されていない.
4.
00: はじめに 全8章 • 【第1章】はじめに •
【第2章】順伝搬型ネットワーク • 【第3章】確率率率的勾配降降下法 • 【第4章】誤差逆伝搬法 • 【第5章】⾃自⼰己符号化器 • 【第6章】畳込みニューラルネット(CNN) • 【第7章】再帰型ニューラルネット(RNN) • 【第8章】ボルツマンマシン
5.
00: はじめに 全8章 • 【第1章】はじめに •
【第2章】順伝搬型ネットワーク • 【第3章】確率率率的勾配降降下法 • 【第4章】誤差逆伝搬法 • 【第5章】⾃自⼰己符号化器 • 【第6章】畳込みニューラルネット(CNN) • 【第7章】再帰型ニューラルネット(RNN) • 【第8章】ボルツマンマシン
6.
00: はじめに –
これまでのまとめ (1・2章) -‐‑‒ 深層学習(Deep Learning) / ニューラルネット を使って分析するとは • ネットワークの構造 を決める • 活性化関数 を決める • 学習⽅方法(誤差関数と最適化法) を決める の3つを⾏行行うことである
7.
00: はじめに(今回まとめ) 深層学習・ニューラルネットワークを使⽤用することは、 • 学習時の過適合(overfitting) •
学習にかかる膨⼤大な計算時間 との戦い. 過適合を緩和する⽅方法と計算時間を縮⼩小する⼿手法を組み合わせて 現実的に解決可能な問題へ落落とし込む
8.
第3章 確率率率的勾配降降下法 3.1
勾配降降下法 3.2 確率率率的勾配降降下法 3.3 「ミニバッチ」の利利⽤用 3.4 汎化性能と過適合 3.5 過適合の緩和 3.6 学習のトリック <前編> 前回 <後編> 今回
9.
第3章 確率率率的勾配降降下法 3.1
勾配降降下法 3.2 確率率率的勾配降降下法 3.3 「ミニバッチ」の利利⽤用 3.4 汎化性能と過適合 3.5 過適合の緩和 3.6 学習のトリック
10.
訓練データに対して偏りがなくなるような変換を前処理理で⾏行行う 【解消】 xni new ≡ xni observed − xi σi σi = 1 N xni observed −
xi( ) 2 n=1 N ∑ 訓練データに偏りがあると、学習の妨げとなる場合がある 01: 3.6.1 データの正規化 学習時に実⾏行行することで汎化性能を向上させる・学習を早める⽅方法をいくつか紹介 【データの正規化 or データの標準化】 (normalization of data) (standardization of data) 各サンプルに線形変換を施し、その成分毎の平均や分散を揃える操作のこと. xi = xni observed n=1 N ∑ N 【課題】
11.
02: 3.6.2
データ拡張 過適合を起こす最⼤大の原因は、訓練データの量量が⾜足りないこと ⼤大量量のサンプルを集める:通常かなりのコストを要す or そもそも不不可能 じゃあ、データ集めるか 【課題】 【データ拡張(data augmentation)】 -‐‑‒ ⼿手持ちのサンプルデータに何らかの加⼯工を施し、量量を「⽔水増し」する⽅方法. -‐‑‒ サンプルxに何らかの変更更を加えて新しいサンプルとして扱うxʼ’を作る. サンプル x ノイズ 新しい サンプル xʼ’ <具体例例>:画像 平⾏行行移動 鏡像反転 回転変動 濃淡の変更更 など • 教師あり学習 では、通常 (x, d) から (xʼ’, d) を作成 • サンプルのばらつき⽅方が予想できる場合は特に有効 • ガウス分布に従うランダムノイズを⼀一律律に加えることも有効 • 古くから使われてきたテクニックの⼀一つ
12.
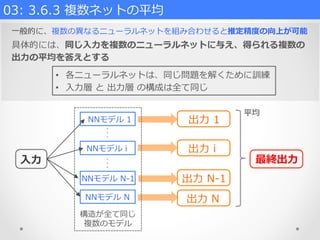
⼀一般的に、複数の異異なるニューラルネットを組み合わせると推定精度度の向上が可能 具体的には、同じ⼊入⼒力力を複数のニューラルネットに与え、得られる複数の 出⼒力力の平均を答えとする 03: 3.6.3 複数ネットの平均
• 各ニューラルネットは、同じ問題を解くために訓練 • ⼊入⼒力力層 と 出⼒力力層 の構成は全て同じ ⼊入⼒力力 NNモデル 1 NNモデル i NNモデル N-‐‑‒1 NNモデル N ・ ・ ・ ・ ・ ・ 構造が全て同じ 複数のモデル 出⼒力力 1 出⼒力力 i 出⼒力力 N-‐‑‒1 出⼒力力 N 平均 最終出⼒力力
13.
⼀一般的に、複数の異異なるニューラルネットを組み合わせると推定精度度の向上が可能 具体的には、同じ⼊入⼒力力を複数のニューラルネットに与え、得られる複数の 出⼒力力の平均を答えとする 03: 3.6.3 複数ネットの平均
• 各ニューラルネットは、同じ問題を解くために訓練 • ⼊入⼒力力層 と 出⼒力力層 の構成は全て同じ 【モデル平均(model averaging)】 同じ⼊入⼒力力を複数のニューラルネットに与えて複数の出⼒力力の平均を答えとする学習⽅方式 1. 構造が異異なるネットワークを同じ訓練データを⽤用いて訓練したもの 2. 同じ構造のネットワークであっても学習開始時の初期値を変えて同じ 訓練データで訓練したもの 3. ⼊入⼒力力に複数の変換を施しておいて、それぞれを異異なる決まったネット ワークに⼊入⼒力力し、その結果を平均するもの 経験的に推定精度度が向上することが分かっている ※ “ドロップアウト”は、単⼀一のネットワークで実質的に複数のネットワークの モデル平均を実⾏行行する効果があると考えられている
14.
[1]: Adaptive subgradient
methods for online learning and stochastic optimization [JMLRʼ’11 J.Duchi+] w(t+1) = w(t) −ε∇E -‐‑‒誤差関数の勾配-‐‑‒ パラメータ(重み) の更更新式 [AdaGrad]: (勾配のベクトル成分: ) −εgt,i − ε gt',t 2 t'=1 t ∑ gt,i gt,i • 頻出する勾配成分より、 稀に現れる成分を重視 • 有効性⾼高く⼀一般的な⽅方法 になりつつある [普通の勾配降降下法]: 【学習係数を定める定番⽅方法 2選】 1. 学習の初期ほど⼤大きな値を選び、学習の進捗と共に学習係数を⼩小さくする⽅方法 2. ネットワークの全ての層で同じ学習係数を⽤用いず、層毎に異異なる値を使う⽅方法 各層の重みの更更新速度度がなるべく揃うように各層の重みを設定する のが良良いと⼀一般的に⾔言われている 04: 3.6.4 学習係数の決め⽅方 勾配降降下法では、パラメータの更更新量量の⼤大きさは学習係数によって変わる ʻ‘学習係数をどう決めるかʼ’は学習の正否を左右し、極めて重要 【学習係数を⾃自動的に定める⽅方法】: AdaGrad[1]
15.
w(t+1) = w(t) −ε∇Et +µΔw(t−1) Δw(t−1) ≡
w(t−1) − w(t−2) 05: 3.6.5 モメンタム • 勾配降降下法の収束性能を向上させる⽅方法のひとつ. • 重みの修正量量に前回の重みの修正量量を適当に加算して計算. 【モメンタム(momentum)】 μは加算の割合を制御するパラメータで、0.5から0.9程度度 の範囲から選択する 修正項
16.
【解決】ユニットへの総⼊入⼒力力( )がちょうど良良い分散を持つよう に σ を決定 uj
= wji xii ∑ 【具体例例】 ⼊入⼒力力xiの変動を事前に正規化( )しているデータを考える. 今、 総⼊入⼒力力の分散を にしたい時、 V(uj ) =σu 2 σ =σu M−2 と設定すればよい. V(xi ) =1 (M:考えているユニットの⼊入⼒力力側結合の数) 最も⼀一般的な⽅方法:ガウス分布から⽣生成したランダム値を初期値とする⽅方法 ⼀一般的に、ガウスの標準偏差σの選び⽅方 に学習の結果が影響される 標準偏差 σ:⼤大きく設定 → 重みのばらつき:⼤大きくなる 【利利点】 初期の学習が早く進む 【⽋欠点】 誤差関数の減少が早く停⽌止してしまう傾向 06: 3.6.6 重みの初期化
17.
1. クラスが偏らないようにシャッフルしたサンプルを機械 的に組み合わせてミニバッチを⽣生成. 2. 作ったミニバッチを決まった順序で、繰り返しネット ワークに与えて学習. 07: 3.6.7 サンプルの順序
⼀一般的に、ネットワークが「⾒見見慣れない」サンプルを先に提⽰示する と学習が最も早く進む 学習がよくなされていないサンプルをから順に提⽰示する⽅方法 Efficient backprop. In Neural Networks: Tricks of the trade. [Y.LeCun, 1988] 【ディープネットワークの場合】 ⼤大規模ネットワークと⼤大量量の訓練サンプルを如何に効率率率良良く捌くかに重点 が置かれている
18.
終わり
Download













![[1]: Adaptive subgradient methods for online learning and stochastic optimization [JMLRʼ’11 J.Duchi+]
w(t+1)
= w(t)
−ε∇E -‐‑‒誤差関数の勾配-‐‑‒
パラメータ(重み)
の更更新式
[AdaGrad]:
(勾配のベクトル成分: )
−εgt,i
−
ε
gt',t
2
t'=1
t
∑
gt,i
gt,i
• 頻出する勾配成分より、
稀に現れる成分を重視
• 有効性⾼高く⼀一般的な⽅方法
になりつつある
[普通の勾配降降下法]:
【学習係数を定める定番⽅方法 2選】
1. 学習の初期ほど⼤大きな値を選び、学習の進捗と共に学習係数を⼩小さくする⽅方法
2. ネットワークの全ての層で同じ学習係数を⽤用いず、層毎に異異なる値を使う⽅方法
各層の重みの更更新速度度がなるべく揃うように各層の重みを設定する
のが良良いと⼀一般的に⾔言われている
04: 3.6.4 学習係数の決め⽅方
勾配降降下法では、パラメータの更更新量量の⼤大きさは学習係数によって変わる
ʻ‘学習係数をどう決めるかʼ’は学習の正否を左右し、極めて重要
【学習係数を⾃自動的に定める⽅方法】: AdaGrad[1]](https://image.slidesharecdn.com/deeplearning3after-170404114159/85/Deep-Learning-chap-3_2-14-320.jpg)


![1. クラスが偏らないようにシャッフルしたサンプルを機械
的に組み合わせてミニバッチを⽣生成.
2. 作ったミニバッチを決まった順序で、繰り返しネット
ワークに与えて学習.
07: 3.6.7 サンプルの順序
⼀一般的に、ネットワークが「⾒見見慣れない」サンプルを先に提⽰示する
と学習が最も早く進む
学習がよくなされていないサンプルをから順に提⽰示する⽅方法
Efficient backprop. In Neural Networks: Tricks of the trade. [Y.LeCun, 1988]
【ディープネットワークの場合】
⼤大規模ネットワークと⼤大量量の訓練サンプルを如何に効率率率良良く捌くかに重点
が置かれている](https://image.slidesharecdn.com/deeplearning3after-170404114159/85/Deep-Learning-chap-3_2-17-320.jpg)





















![[DL輪読会]Shaping Belief States with Generative Environment Models for RL](https://cdn.slidesharecdn.com/ss_thumbnails/20190705suzuki-191204061058-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Learning to Adapt: Meta-Learning for Model-Based Control](https://cdn.slidesharecdn.com/ss_thumbnails/20180511dl-180511004107-thumbnail.jpg?width=640&height=640&fit=bounds)




![Graph-to-Sequence Learning using Gated Graph Neural Networks. [ACL'18] 論文紹介](https://cdn.slidesharecdn.com/ss_thumbnails/graph2sequencelearningusinggatedgraphneuralnetworkacl18-190507010338-thumbnail.jpg?width=640&height=640&fit=bounds)





