Downloaded 14 times


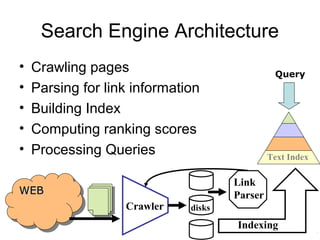

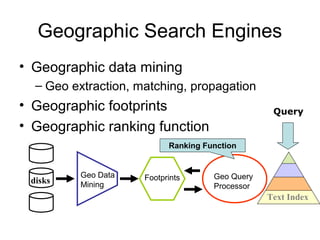



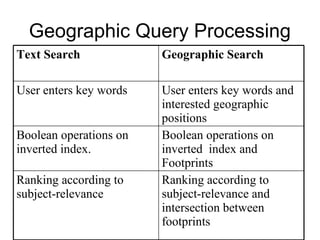


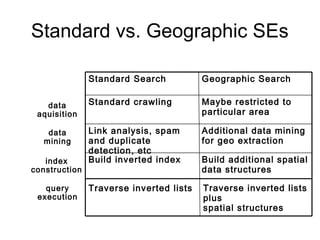
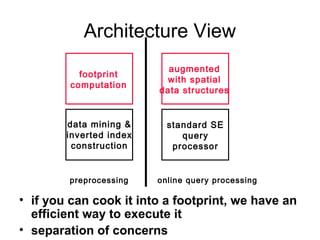









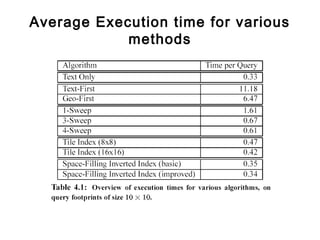

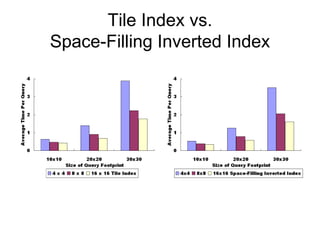
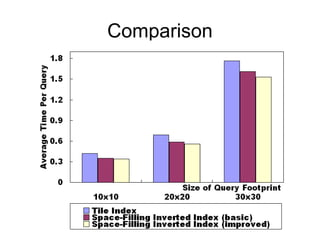



The document discusses efficient query processing in geographic web search engines, outlining the challenges and innovations necessary for integrating geographic data into traditional search engines. It presents methods for representing geographic footprints of documents, the architecture for geographic query processing, and compares various algorithms for improving performance. The authors claim that geographic query processing can achieve similar efficiency levels as text-only queries while suggesting directions for future work in this field.
























![Challenges Distributed Information Retrieval [RBY] (ICDE 2007 Turkey)](https://cdn.slidesharecdn.com/ss_thumbnails/challenges-distributed-information-retrieval-rby-icde-2007-turkey4586-thumbnail.jpg?width=640&height=640&fit=bounds)









































