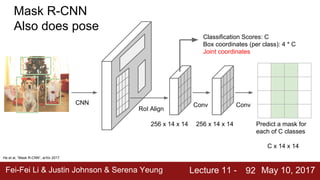
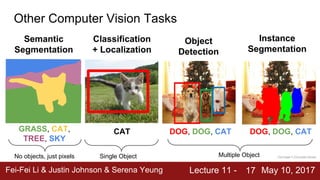
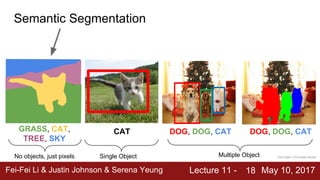
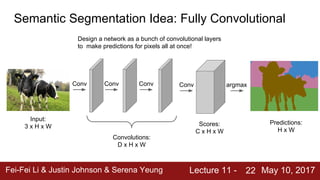
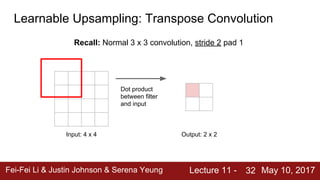
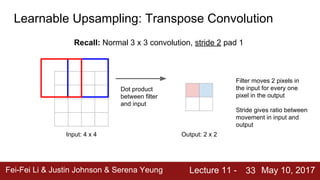
The document discusses semantic segmentation, object detection, and instance segmentation in computer vision. It introduces semantic segmentation as assigning a category label to each pixel in an image without differentiating object instances. Fully convolutional networks are described as an effective approach for semantic segmentation, where a network of convolutional layers with downsampling and learnable upsampling such as transpose convolutions is used to make dense per-pixel predictions while efficiently reusing computations.





























































![Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 11 - May 10, 2017
69
R-CNN: Problems
• Ad hoc training objectives
• Fine-tune network with softmax classifier (log loss)
• Train post-hoc linear SVMs (hinge loss)
• Train post-hoc bounding-box regressions (least squares)
• Training is slow (84h), takes a lot of disk space
• Inference (detection) is slow
• 47s / image with VGG16 [Simonyan & Zisserman. ICLR15]
• Fixed by SPP-net [He et al. ECCV14]
Girshick et al, “Rich feature hierarchies for accurate object detection and
semantic segmentation”, CVPR 2014.
Slide copyright Ross Girshick, 2015; source. Reproduced with permission.](https://image.slidesharecdn.com/objectdetectionstanford-210625090630/85/Object-detection-stanford-69-320.jpg)