Download as PDF, PPTX











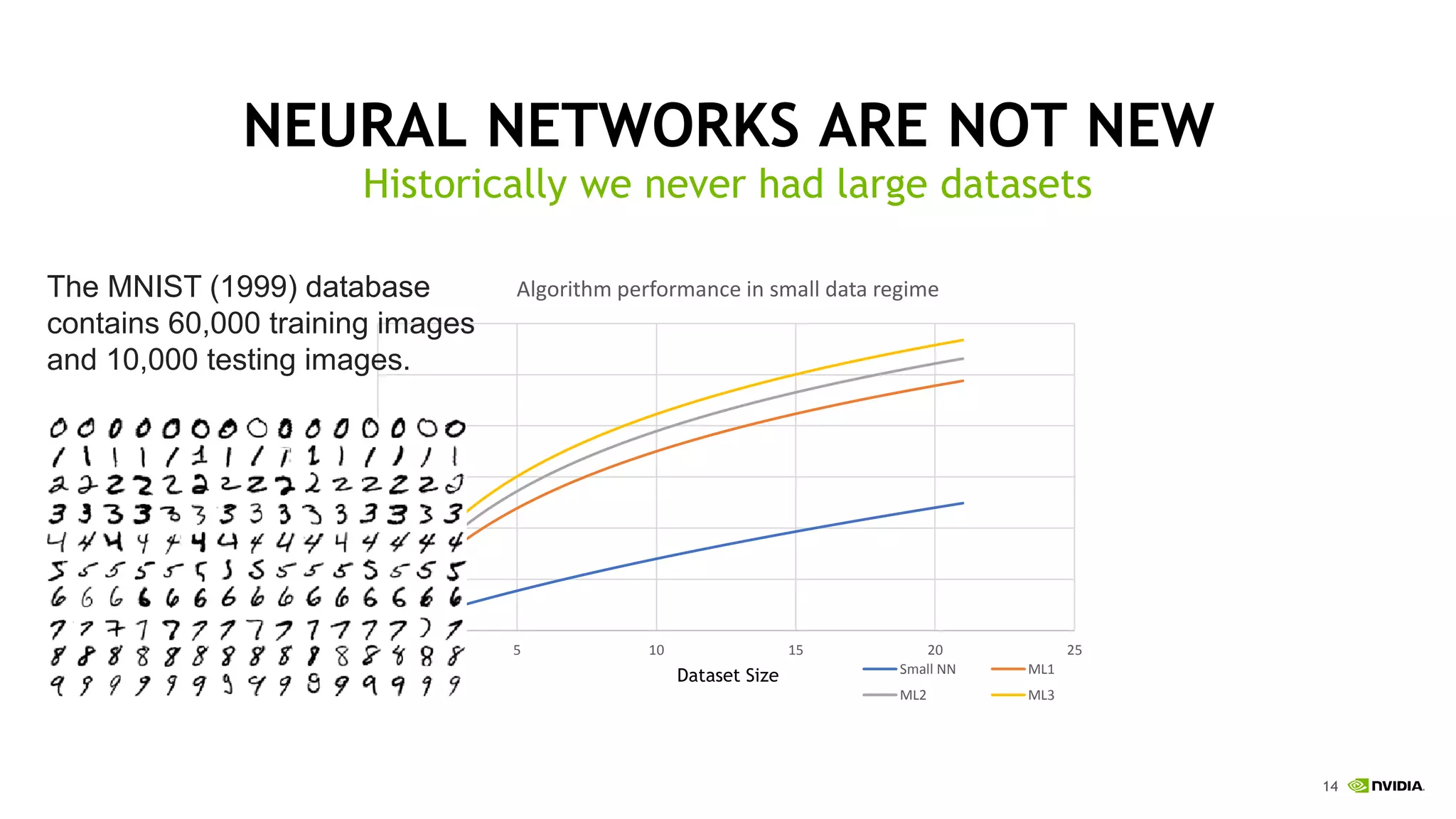
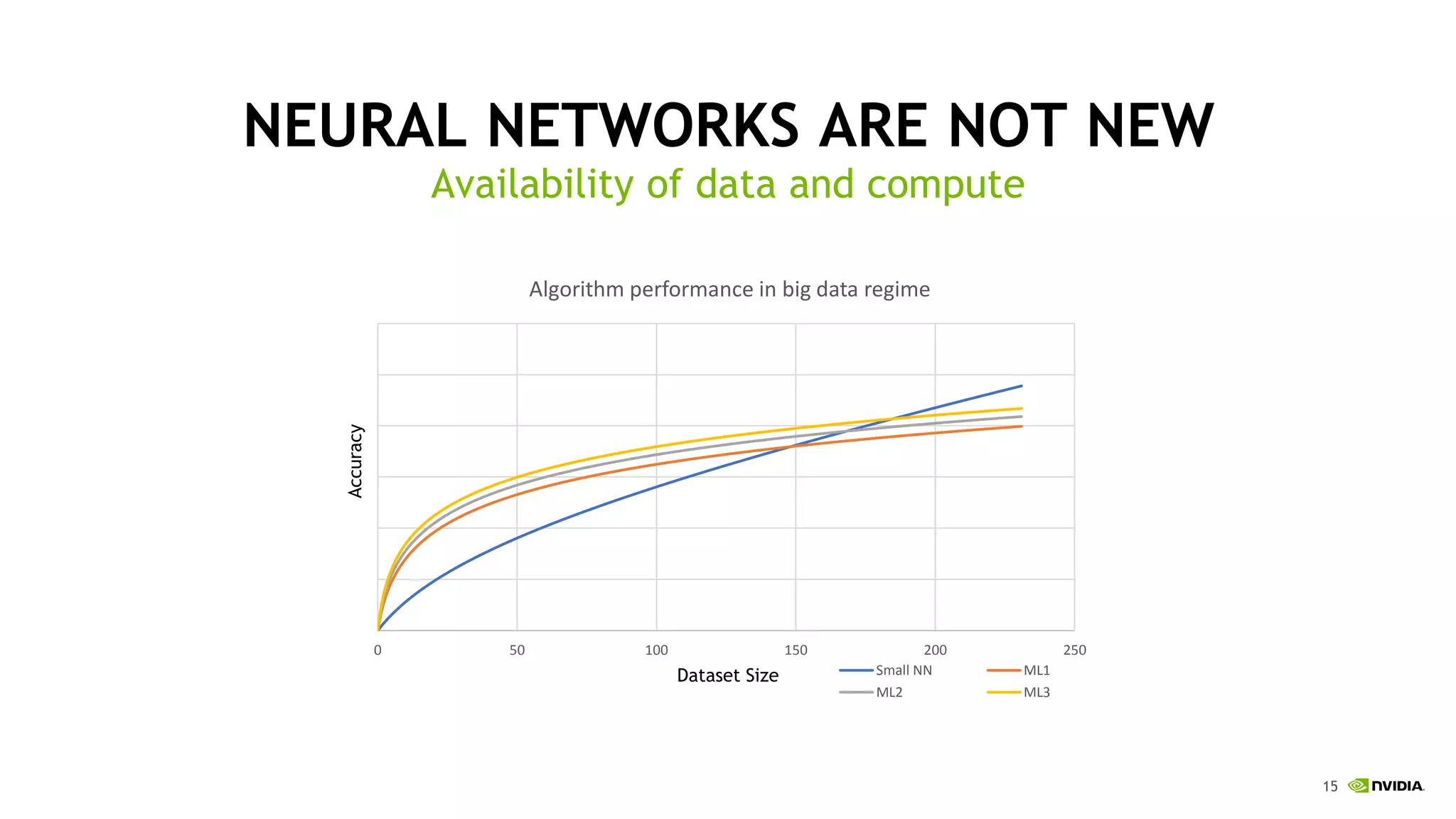
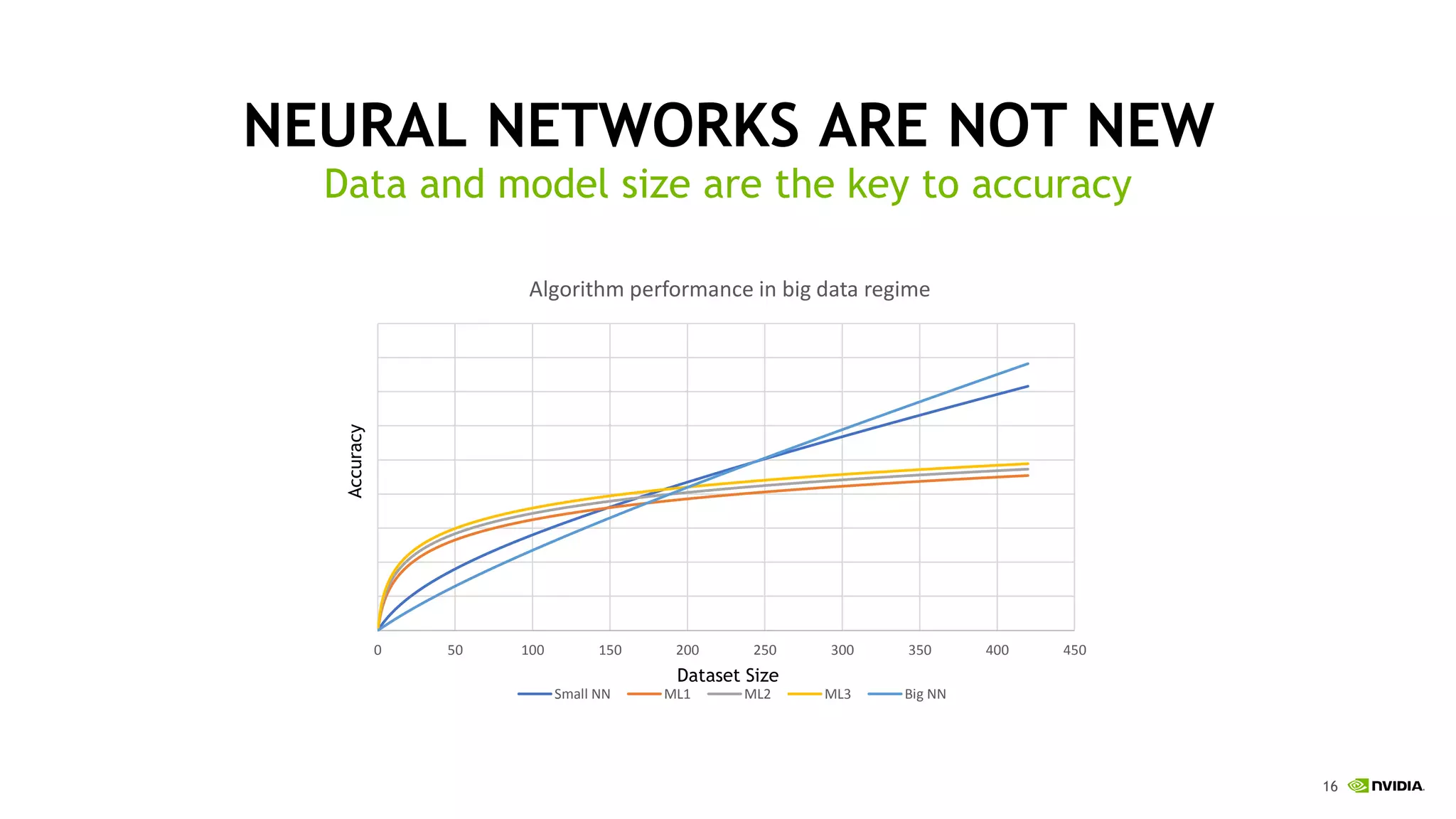
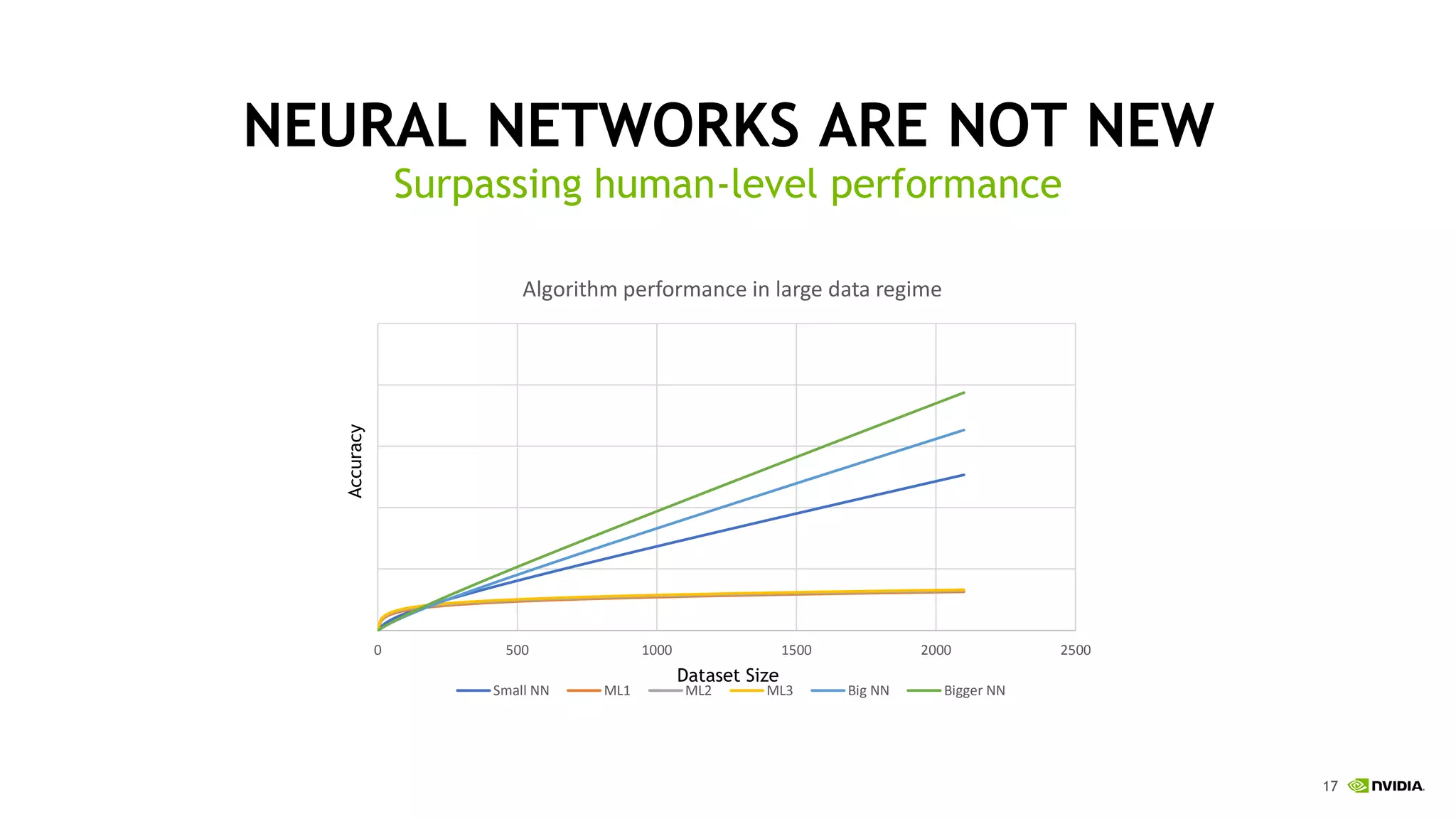


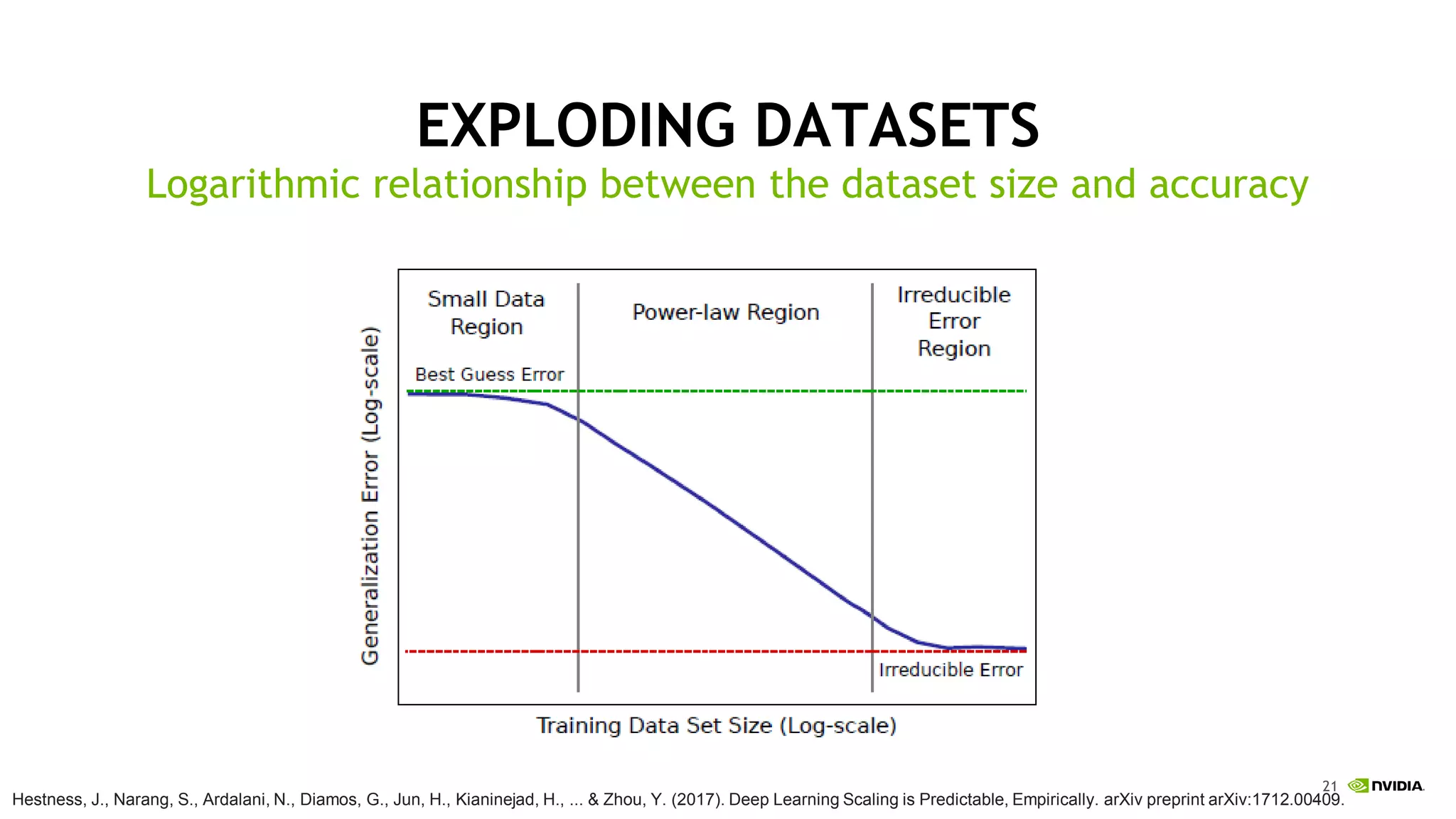
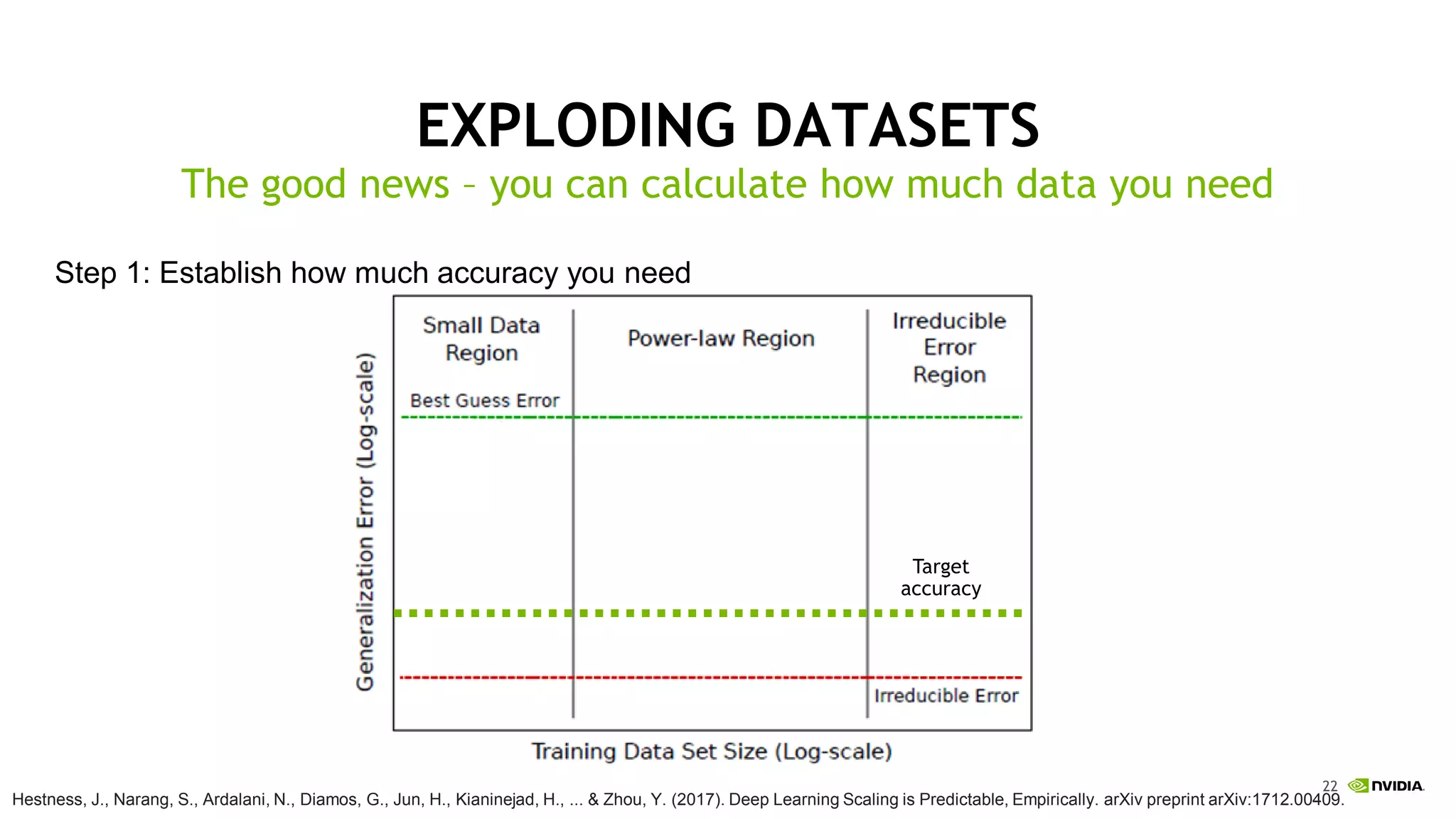
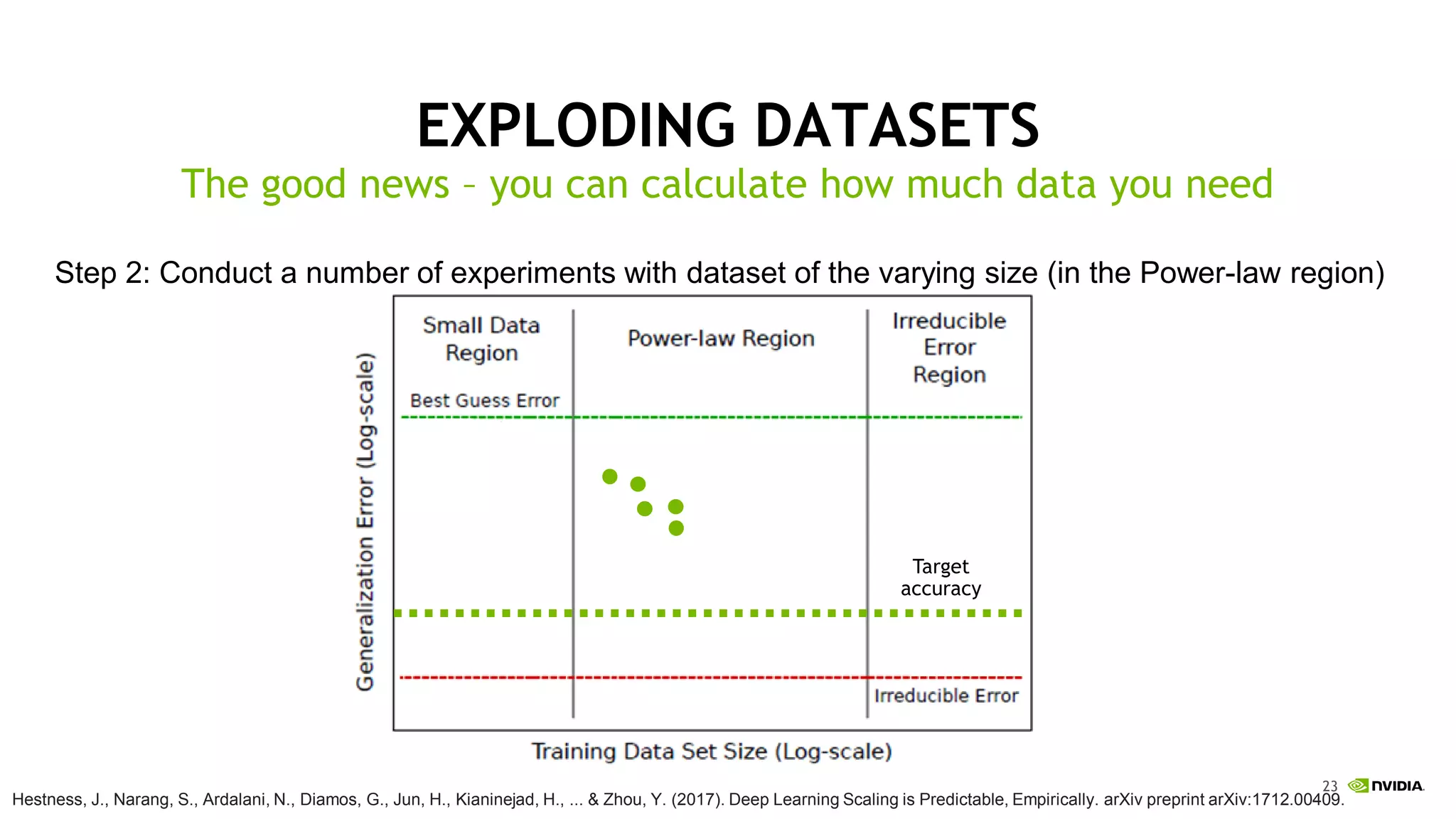
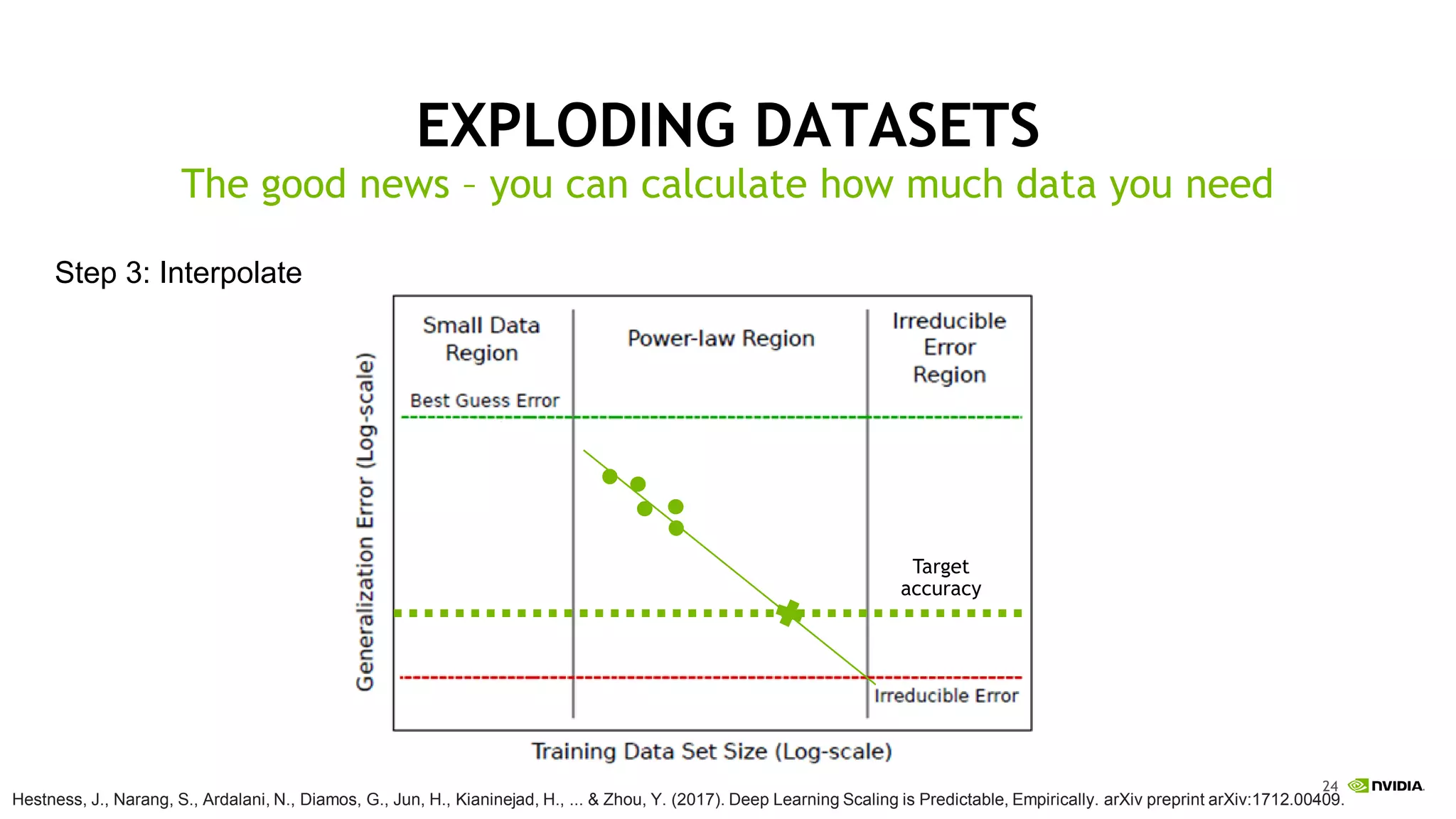





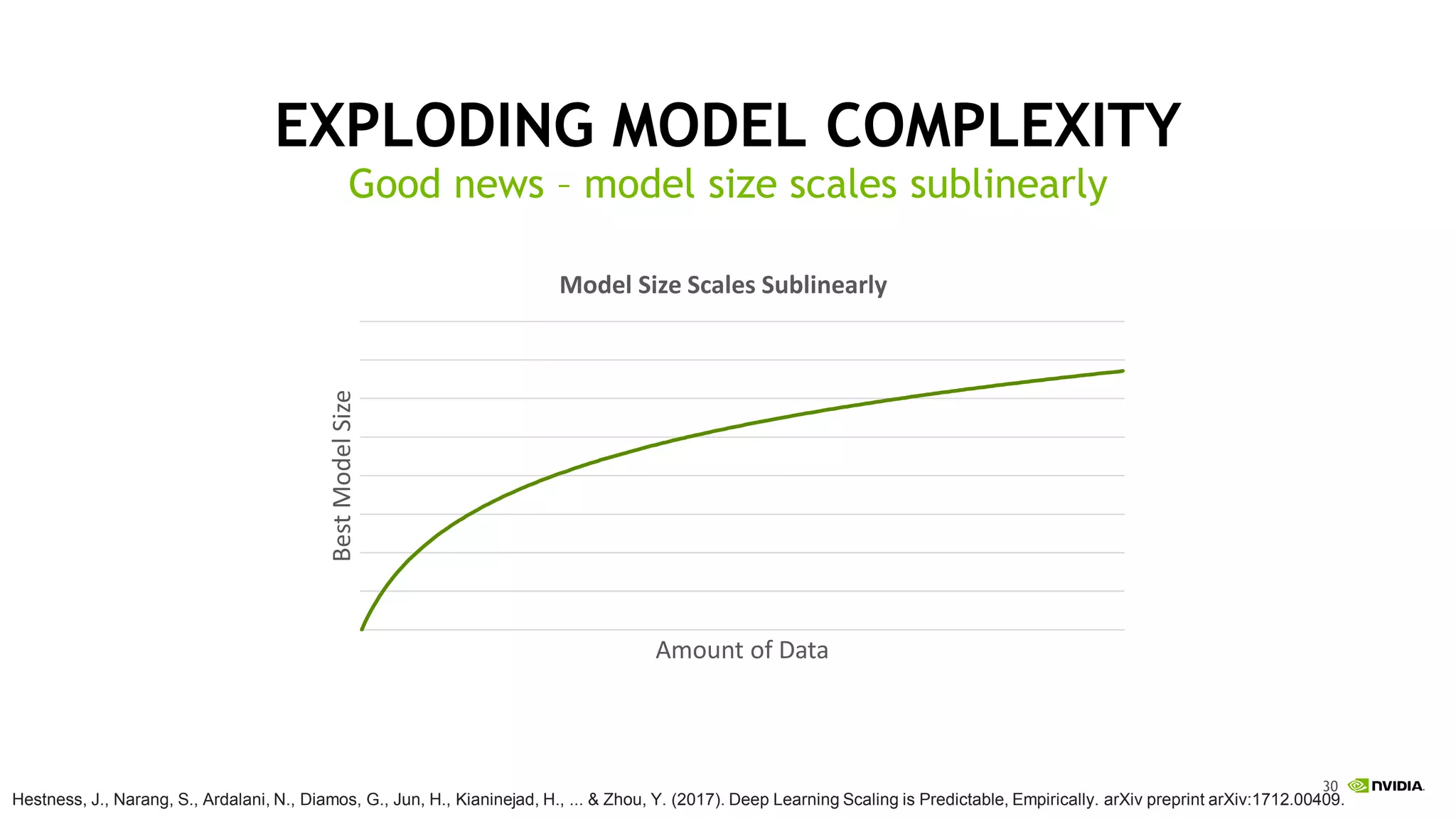
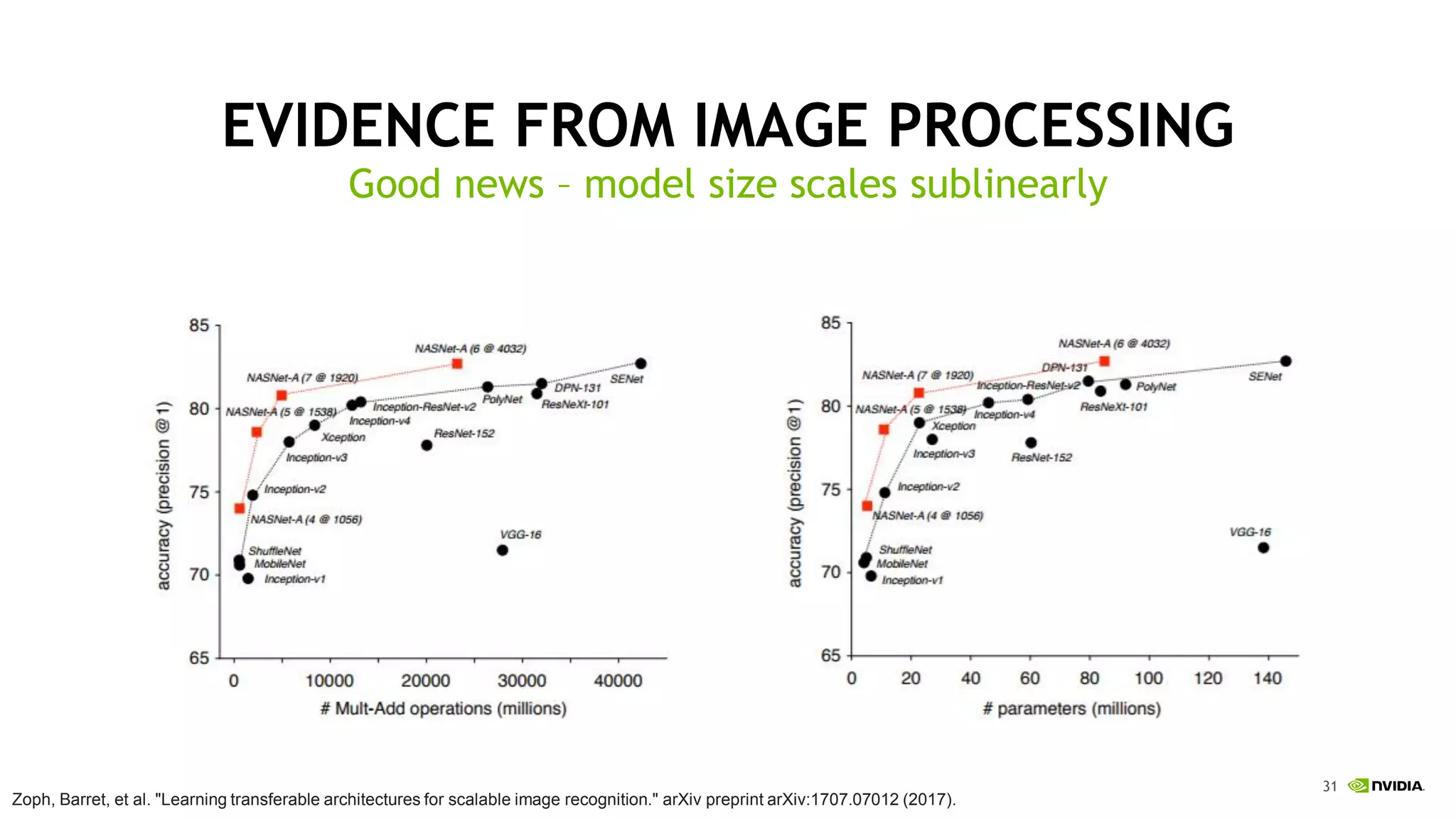

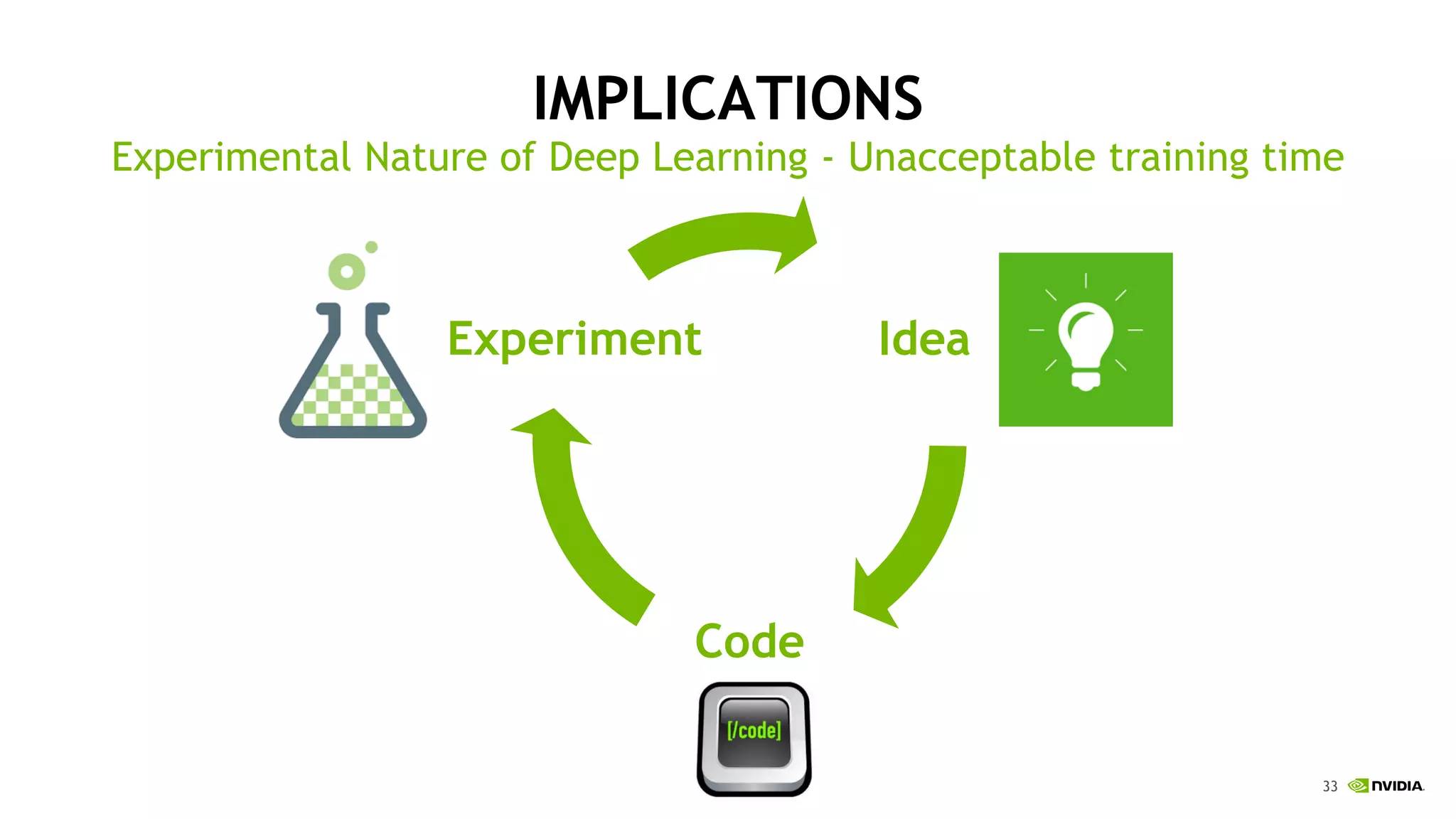



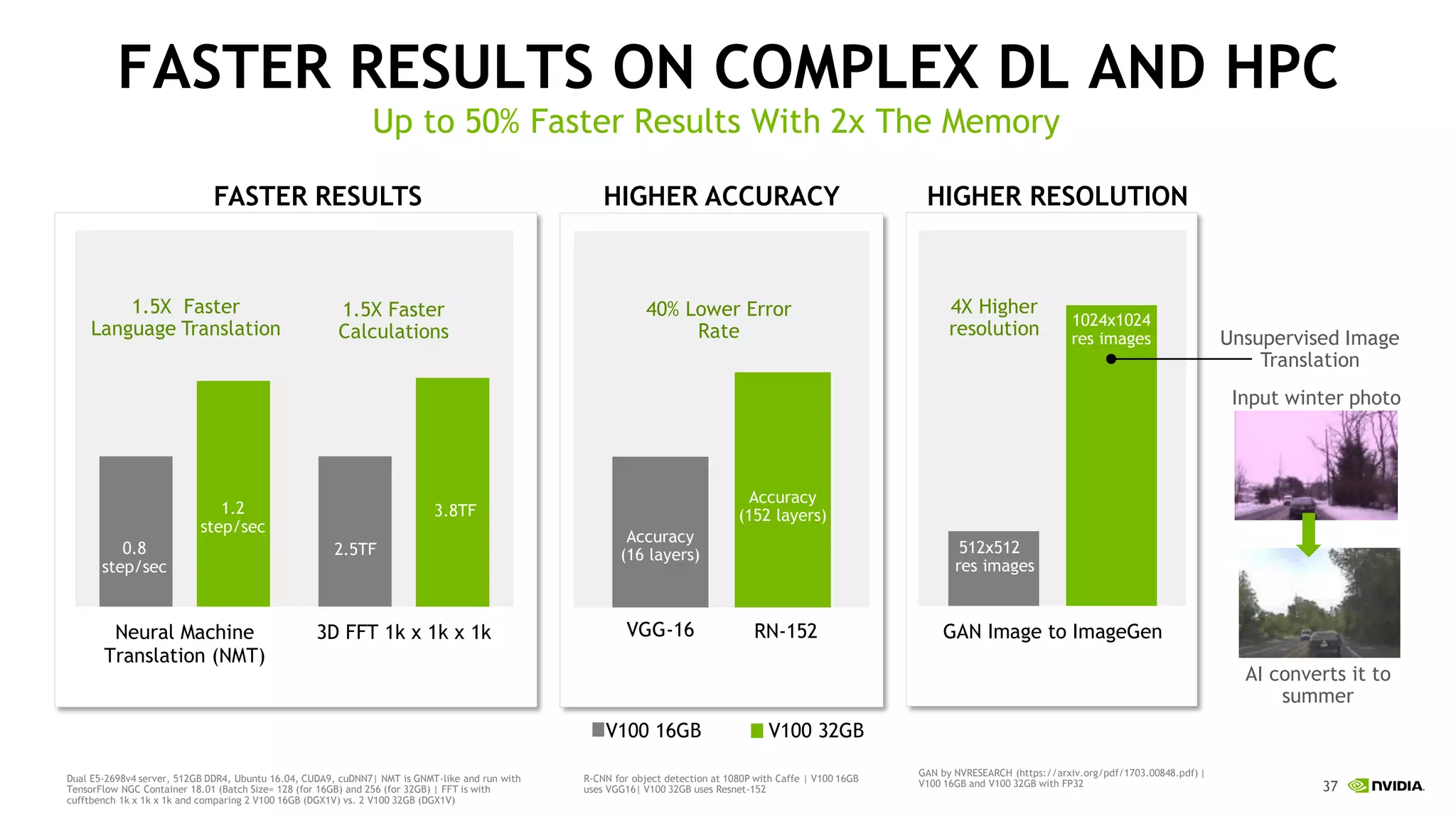






This document discusses the challenges of deep learning including data, models, infrastructure, software, algorithms and people. It notes that neural networks are not new but their performance has improved due to larger datasets and compute capabilities like GPUs. Deep learning requires exponentially larger datasets and models to achieve higher accuracy levels. The model sizes and computational requirements are predictable but can be very large, requiring significant data collection and computing power. It also discusses how to design balanced deep learning systems to efficiently train large models on massive datasets at scale.









































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)