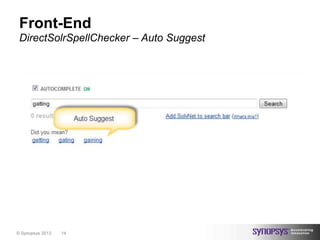
The document discusses the transition from Lucene to Solr 4 by Synopsys, detailing the company's background in electronic design automation and its use of Solr for advanced full-text search capabilities. It covers project inspiration, architecture, front-end development, and back-end tokenization strategies, while also mentioning future plans for further tuning and improvements. The presentation includes a demo and concludes with acknowledgments to contributors and an invitation for questions.