Download as PDF, PPTX


















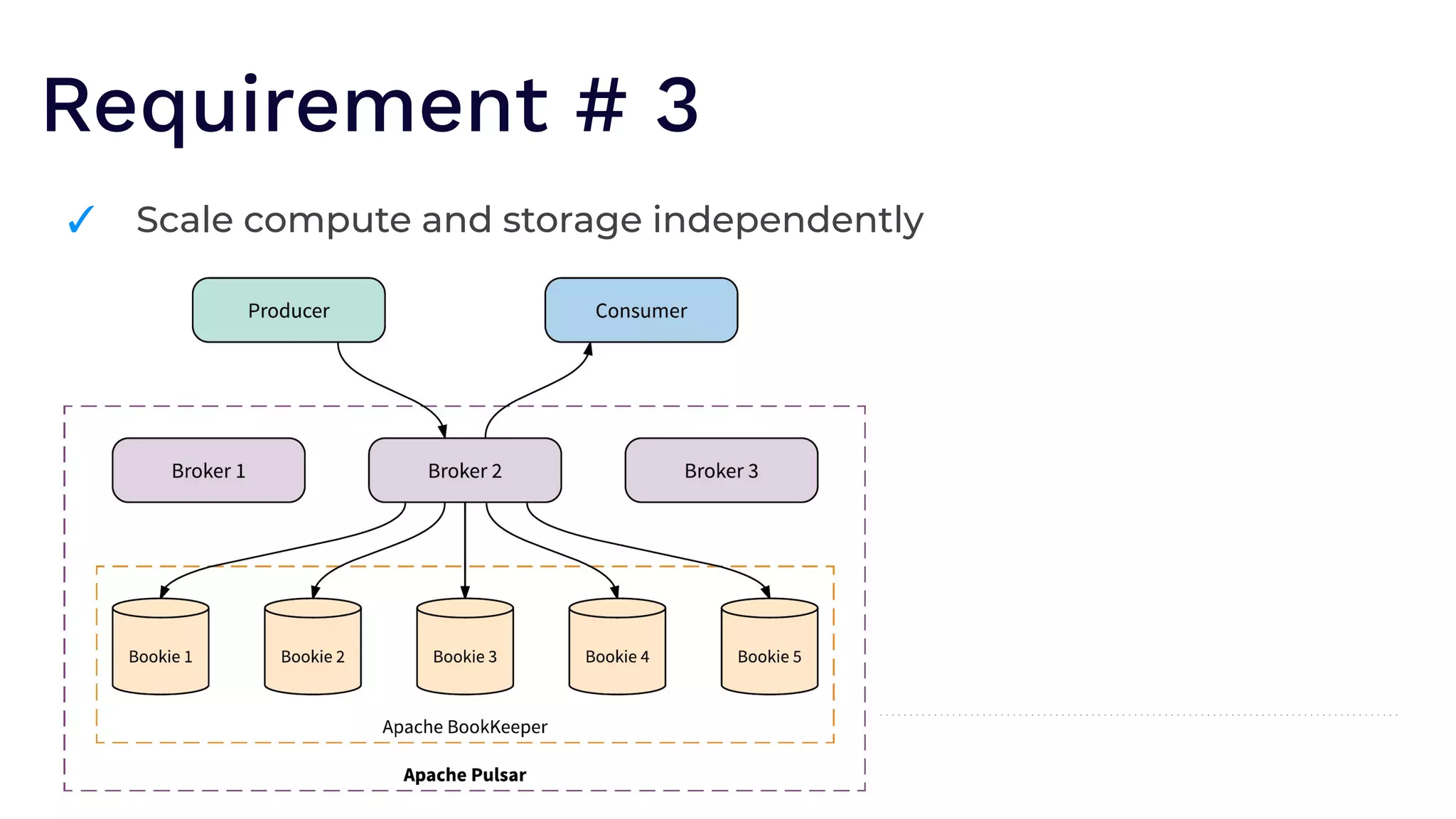
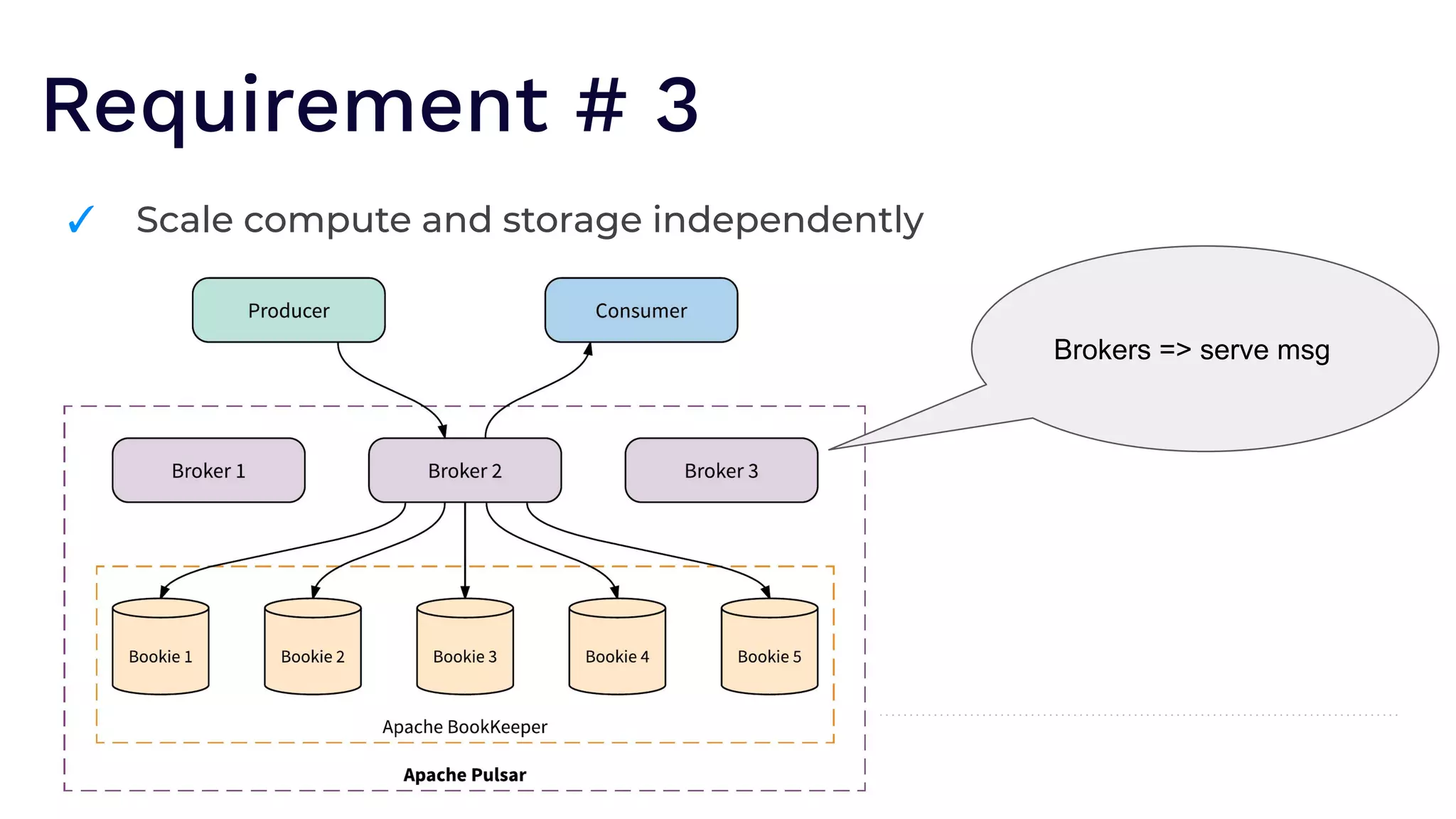
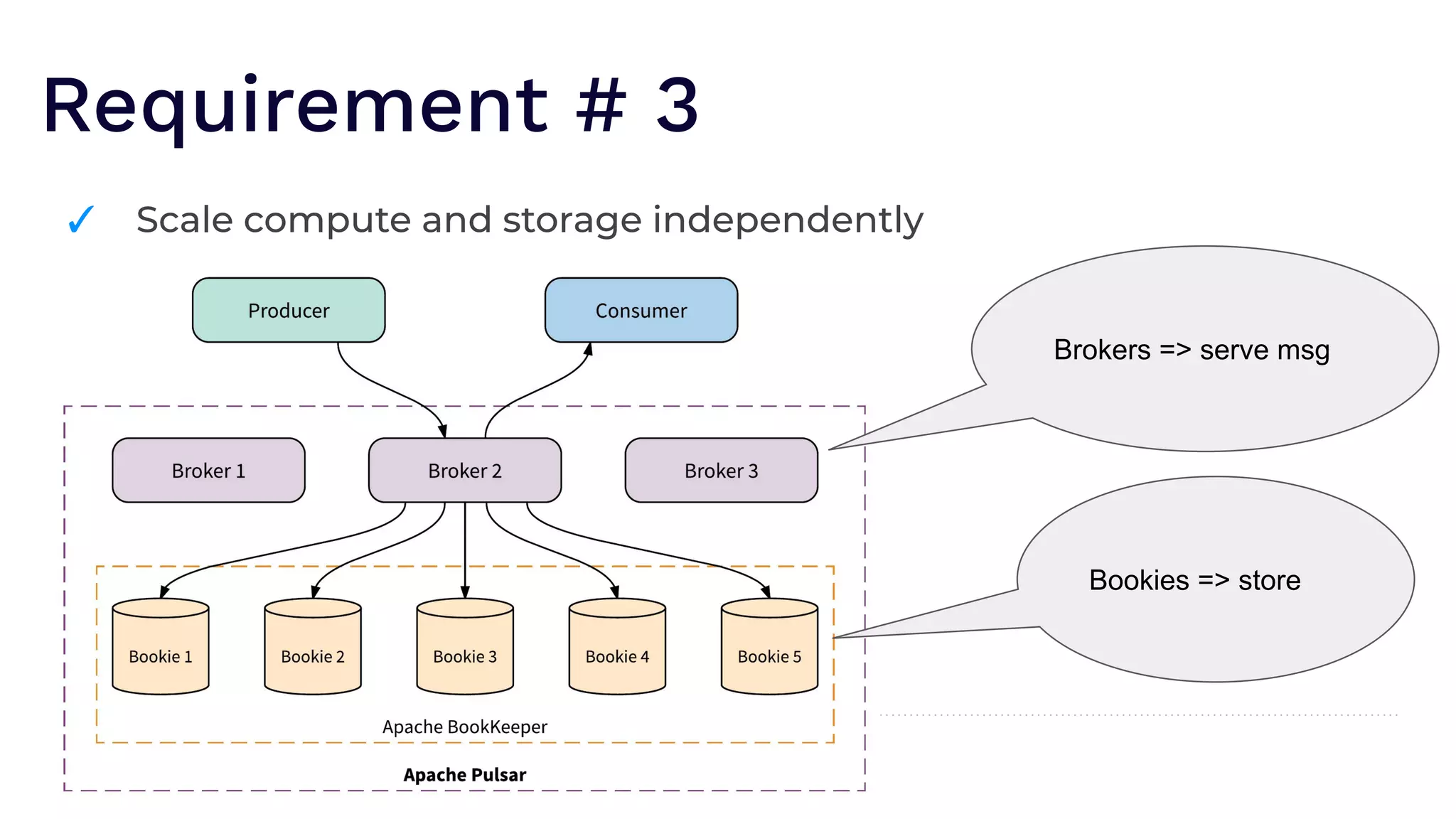
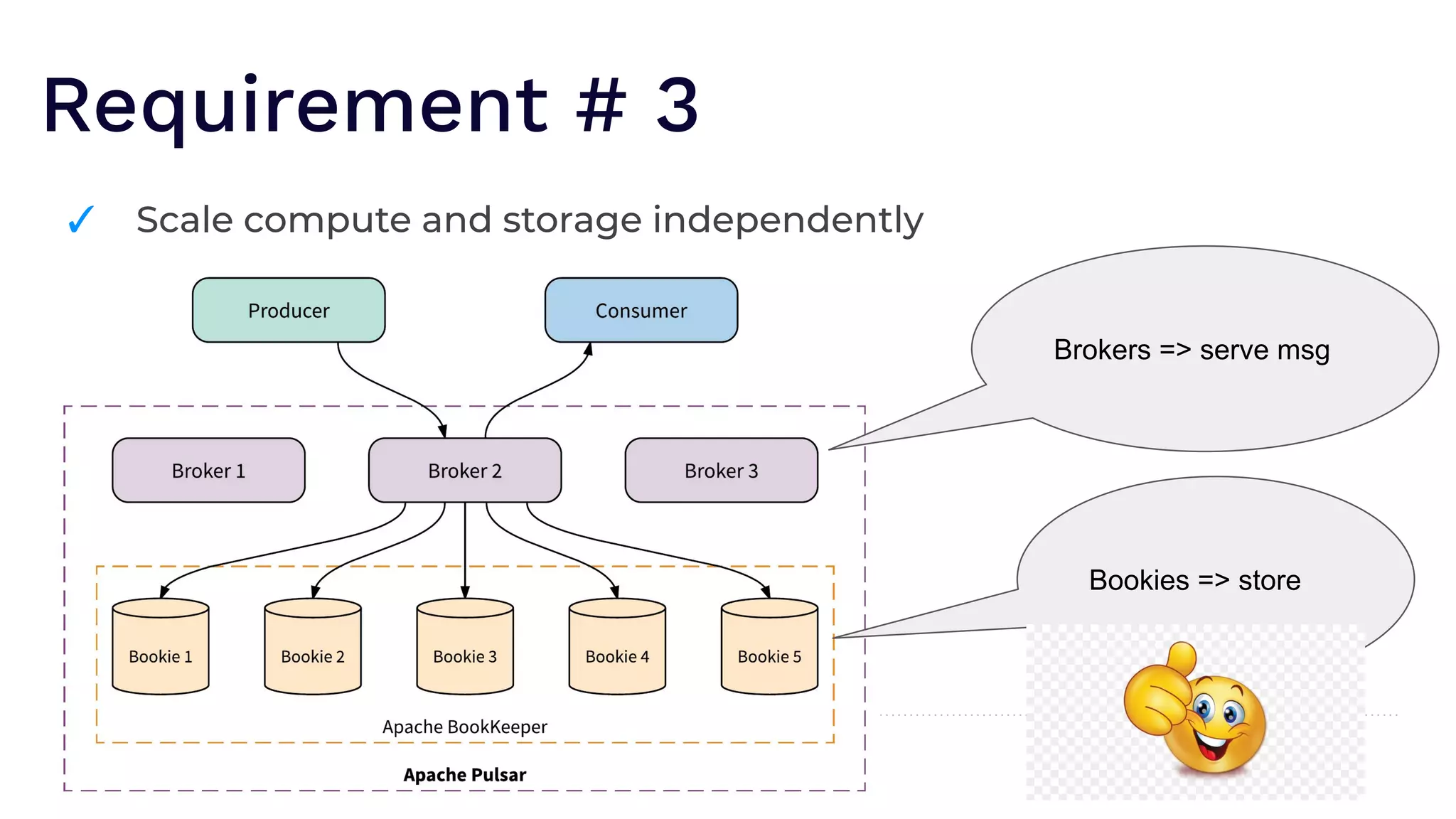

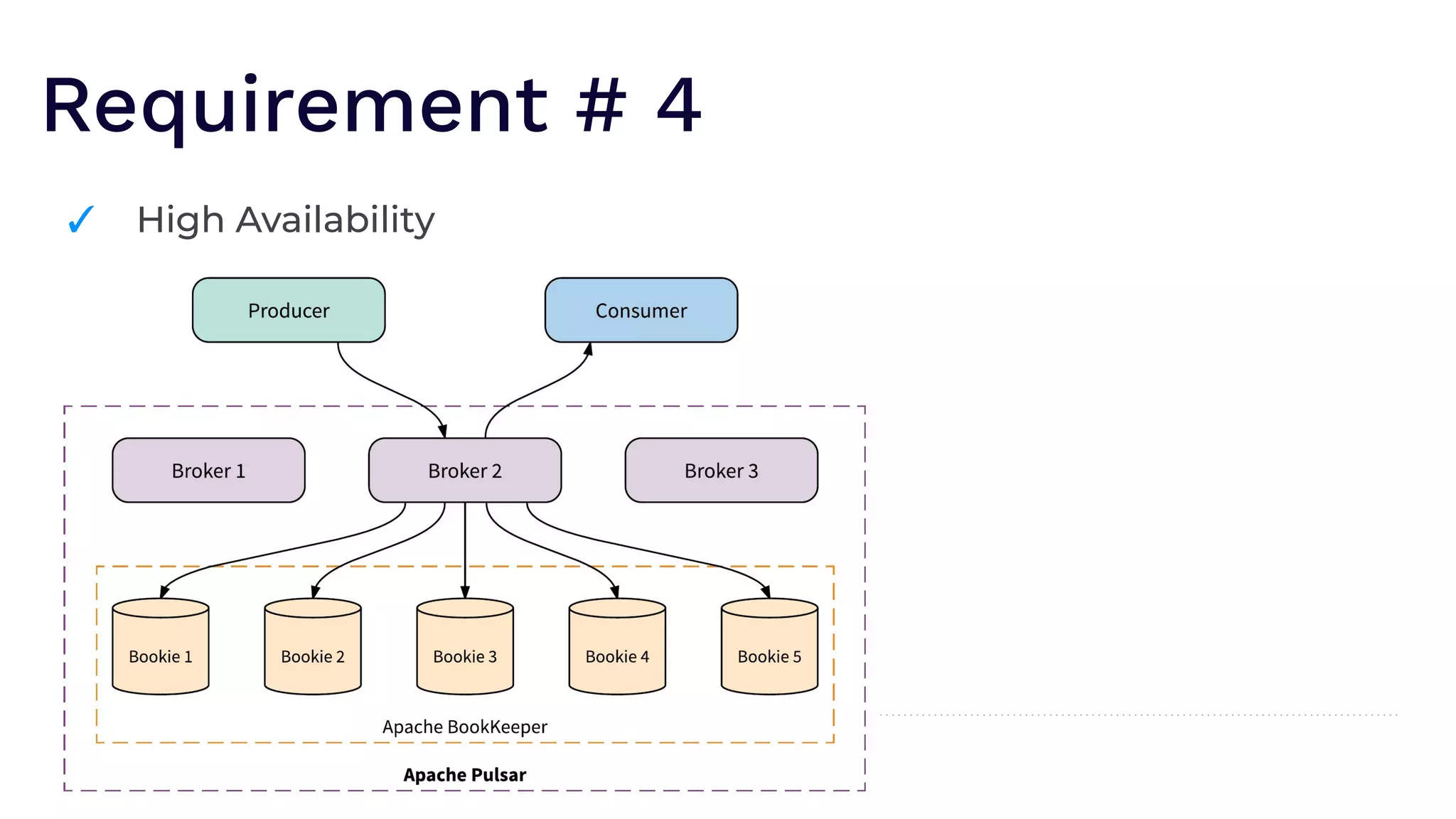
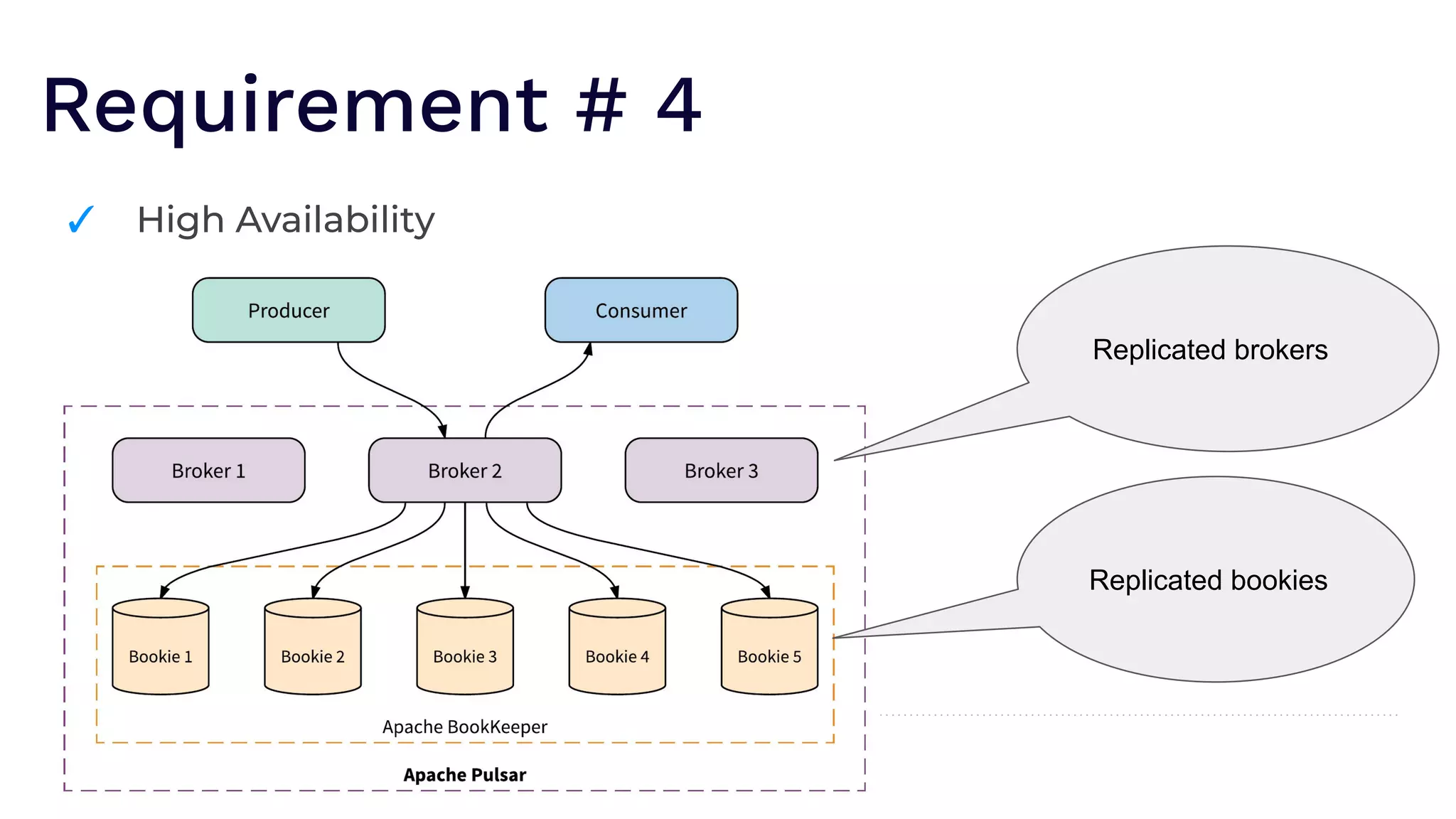
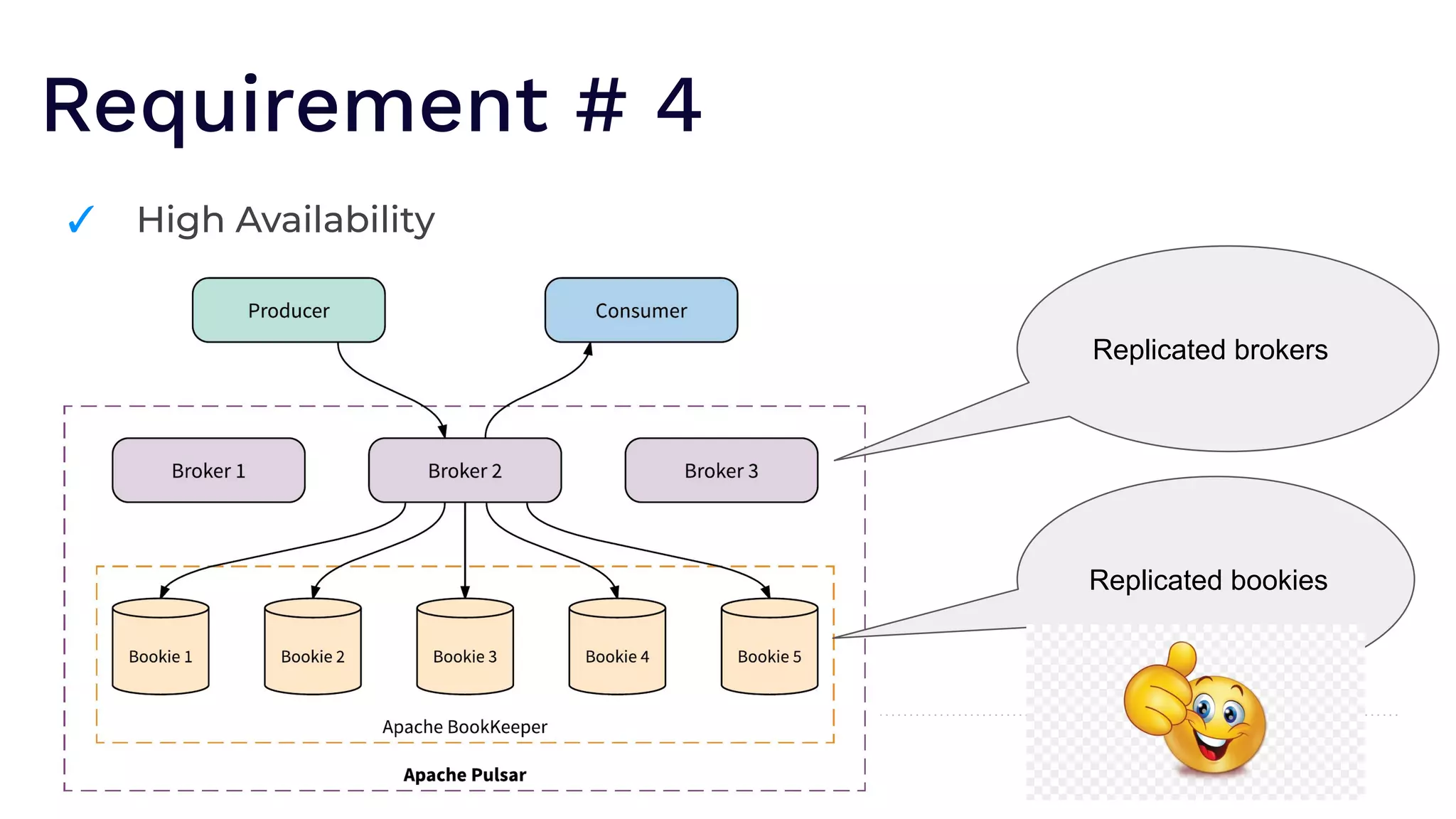



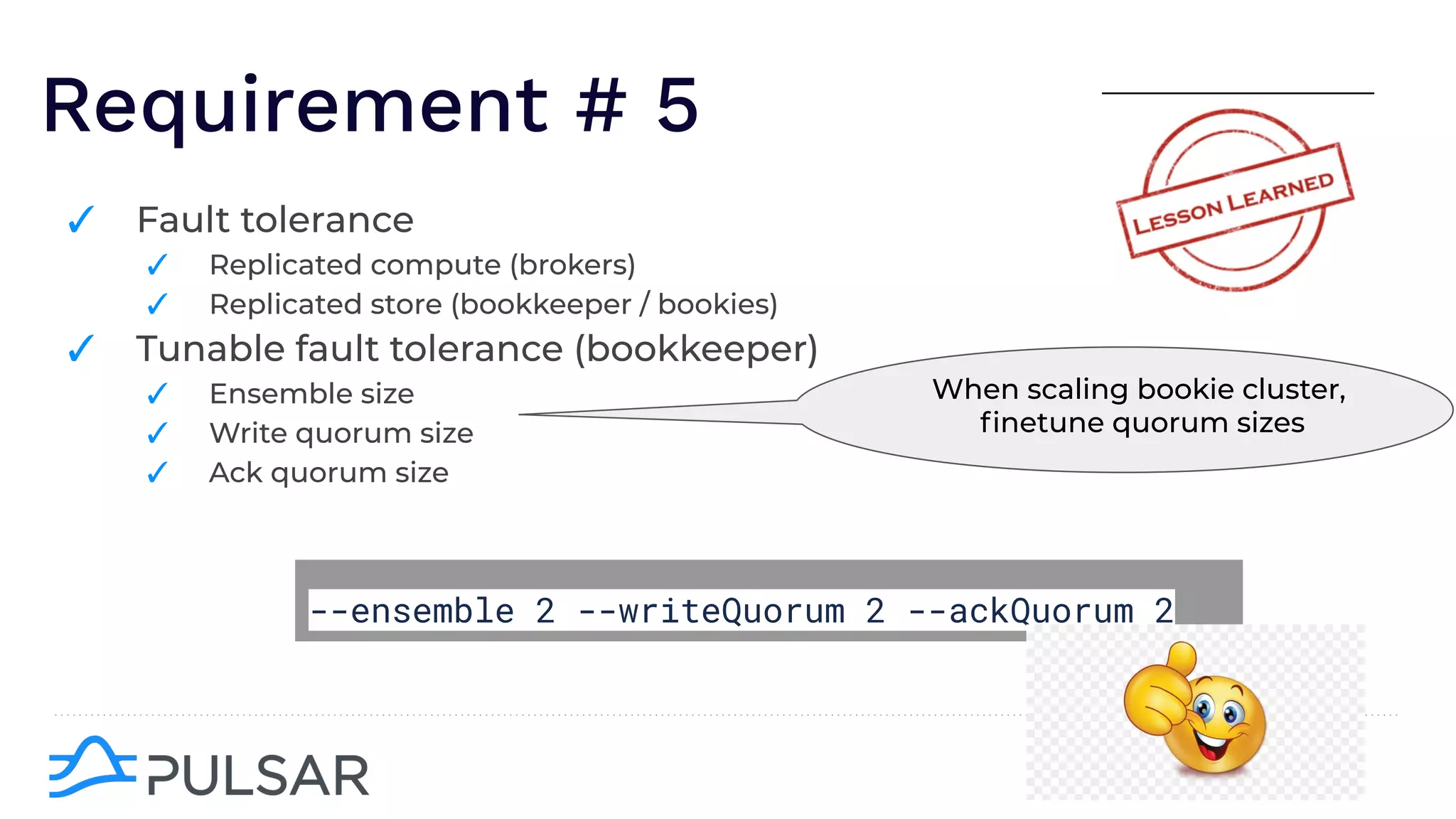










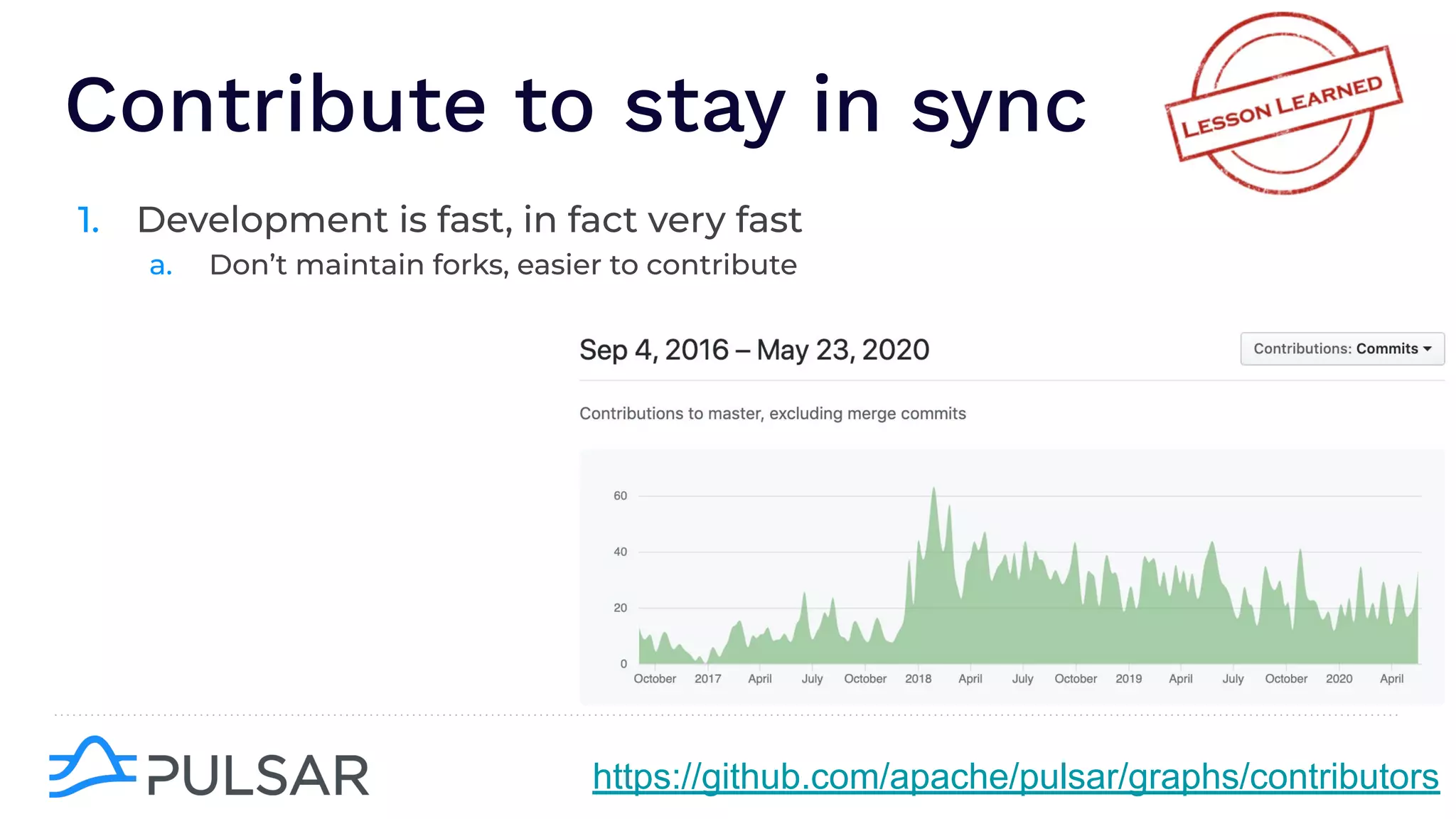



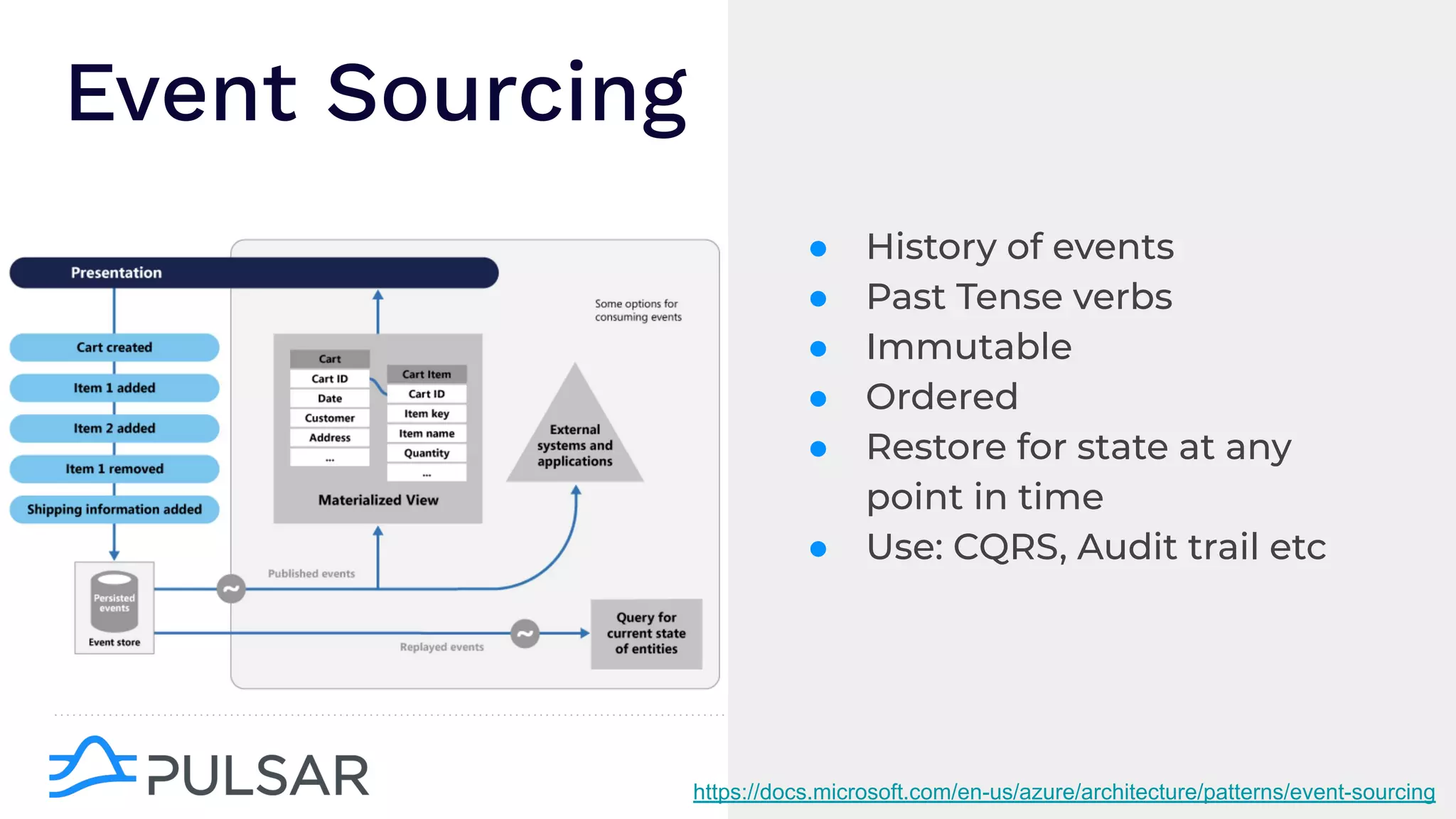

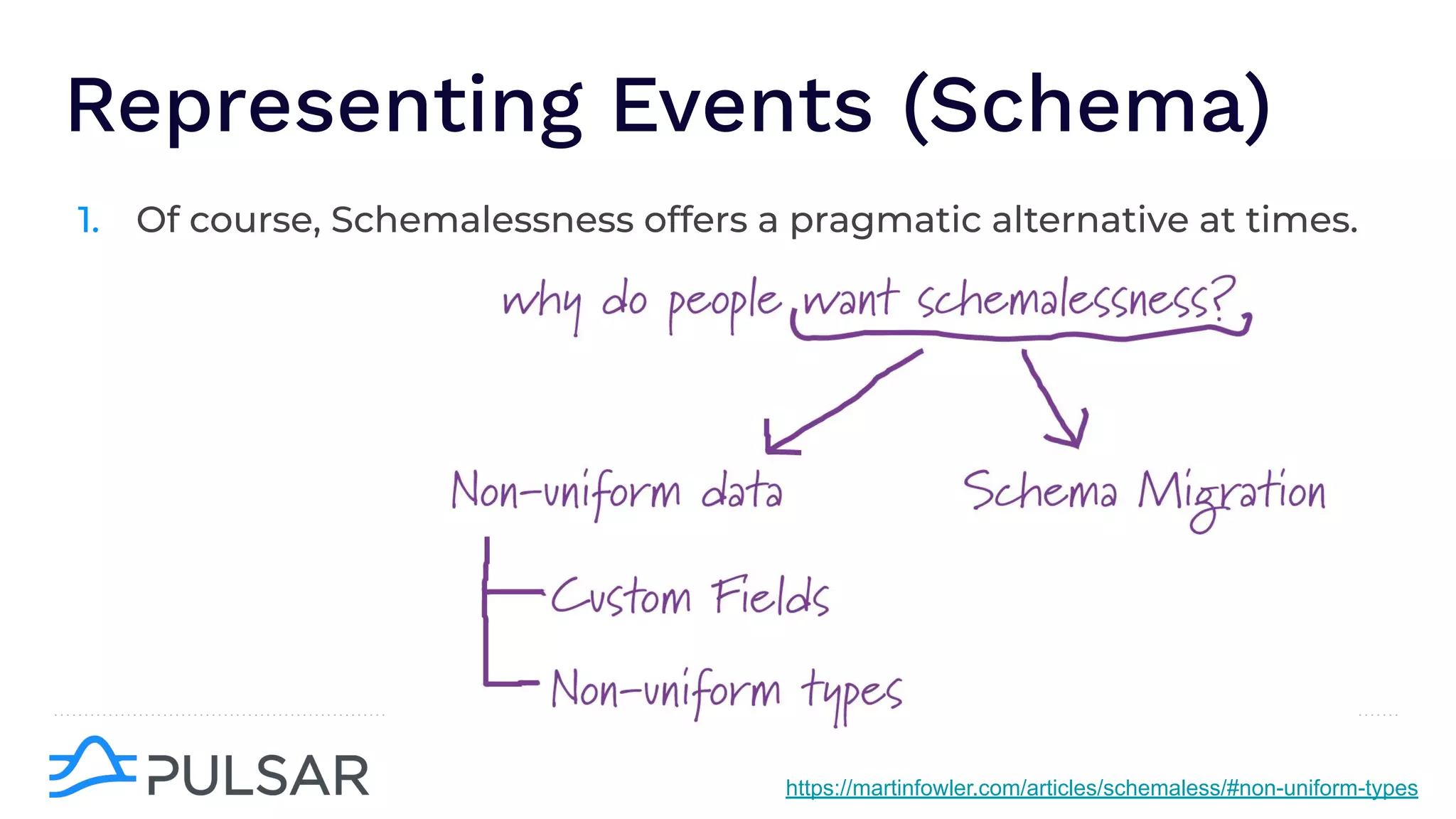
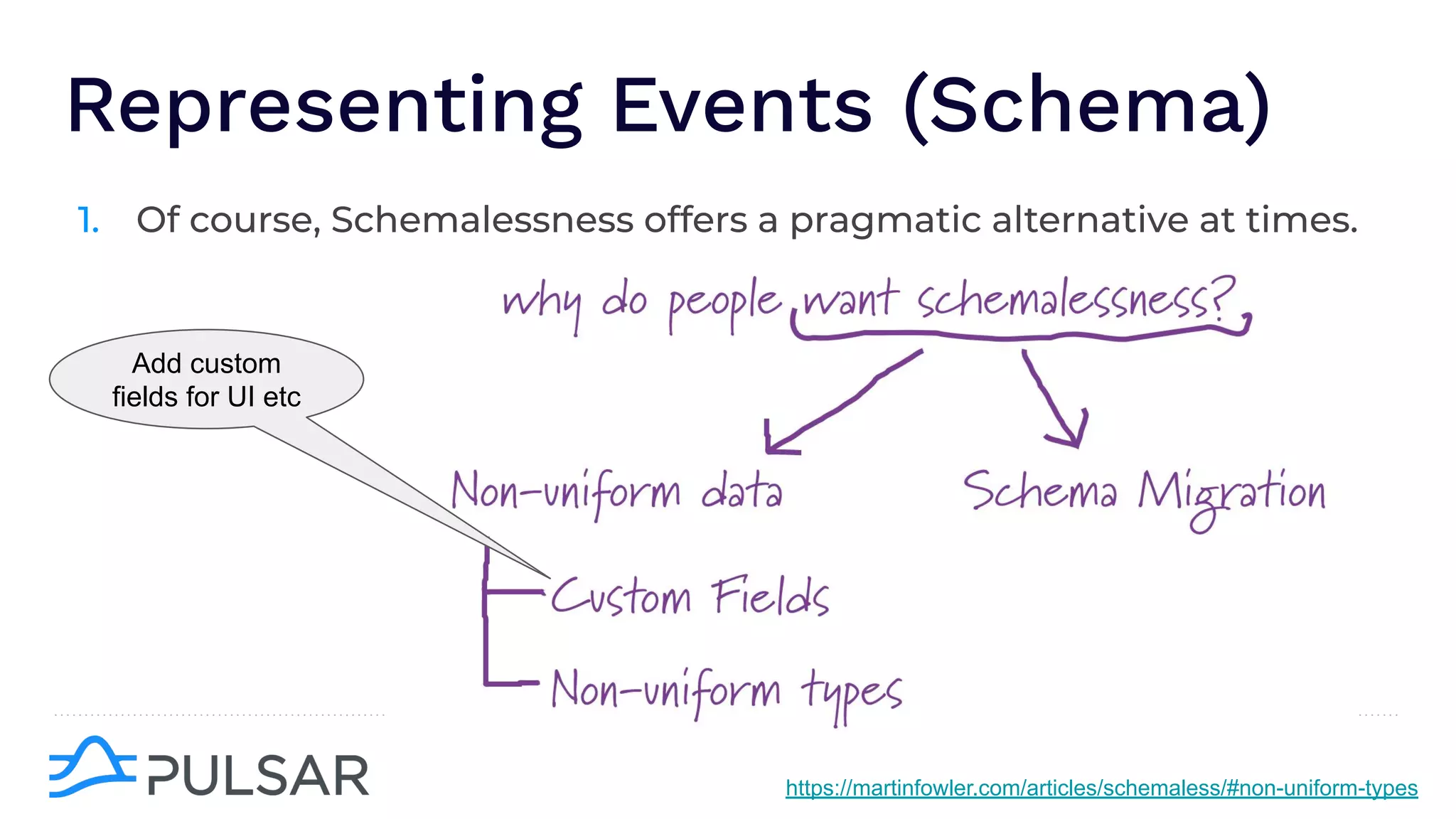
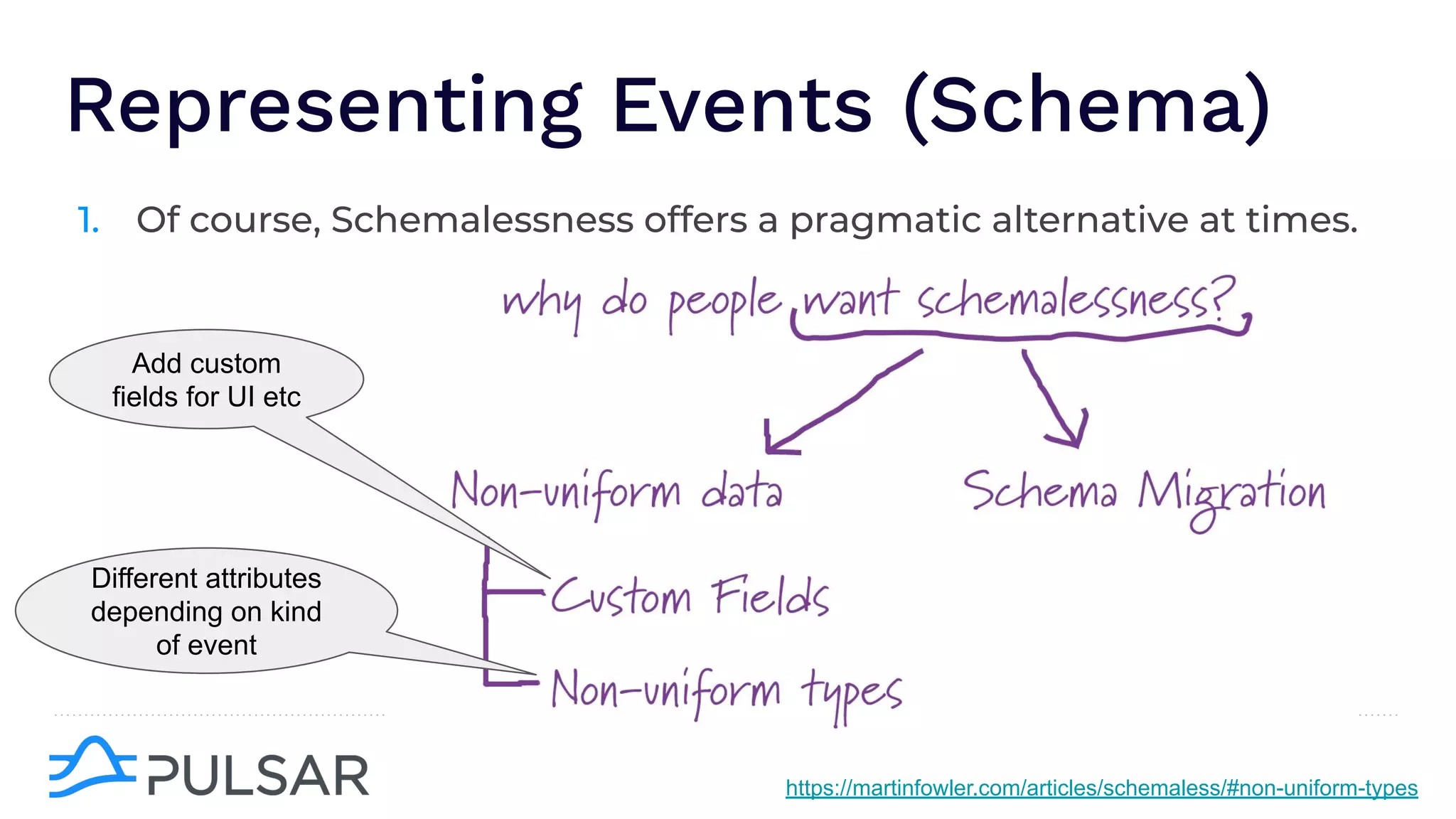
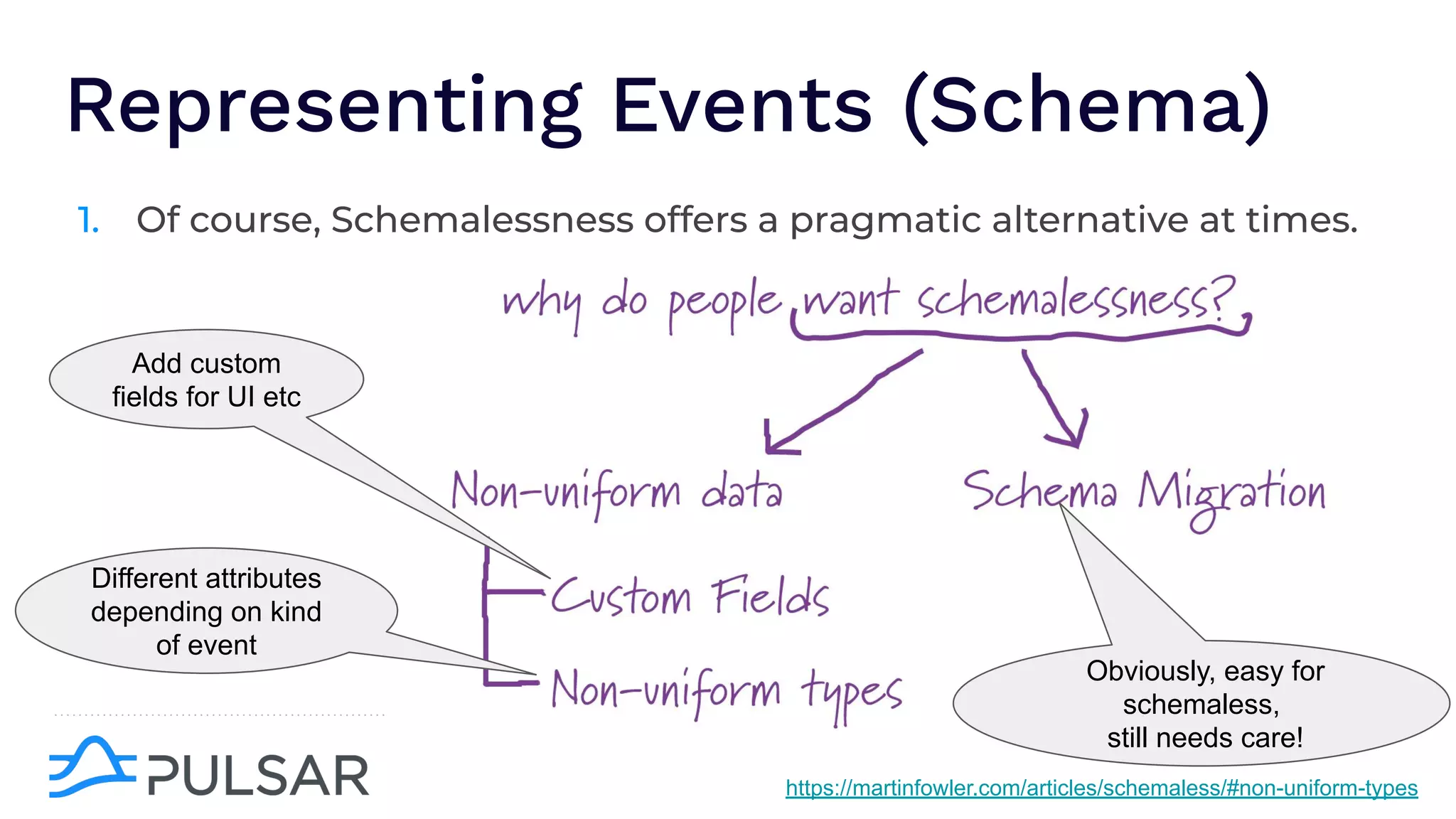







The document outlines the responsibilities of a senior developer at Nutanix, focusing on Apache Pulsar as a solution for managing data in hybrid cloud environments. It highlights key features, requirements, and tuning configurations for Pulsar, emphasizing its capabilities in efficient event storage, processing, and schema handling. The author also provides insights on best practices for utilizing Pulsar, including the use of schemas, performance tuning, and ensuring fault tolerance.




































































![Automating ISP Networks Using Ansible and IPAM as a Source of Truth [SoT]](https://cdn.slidesharecdn.com/ss_thumbnails/automatingispnetworksusingansibleandipamasasourceoftruthsot-v25-1-251124105117-d7d4ca24-thumbnail.jpg?width=640&height=640&fit=bounds)













