Download as PDF, PPTX



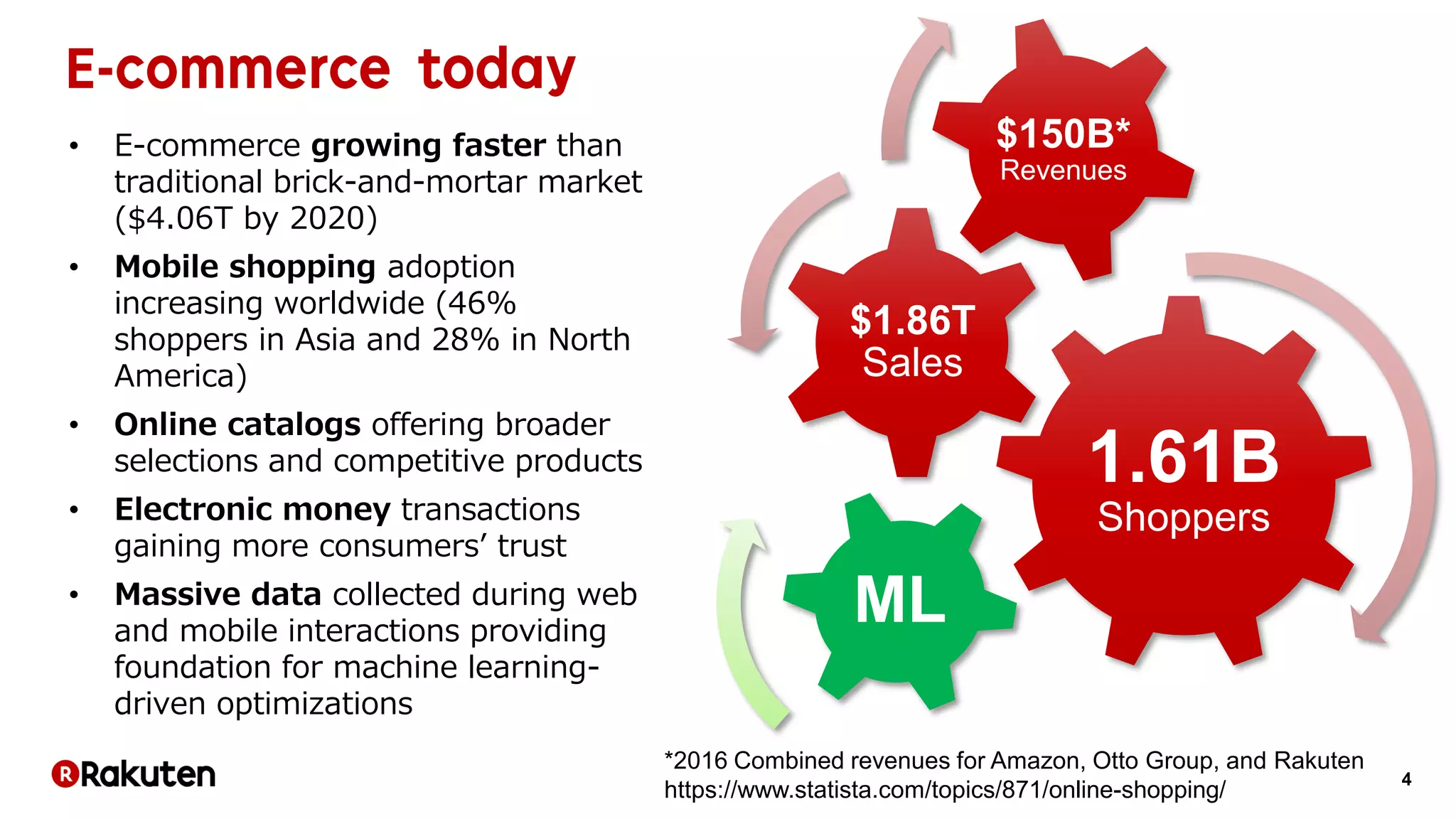

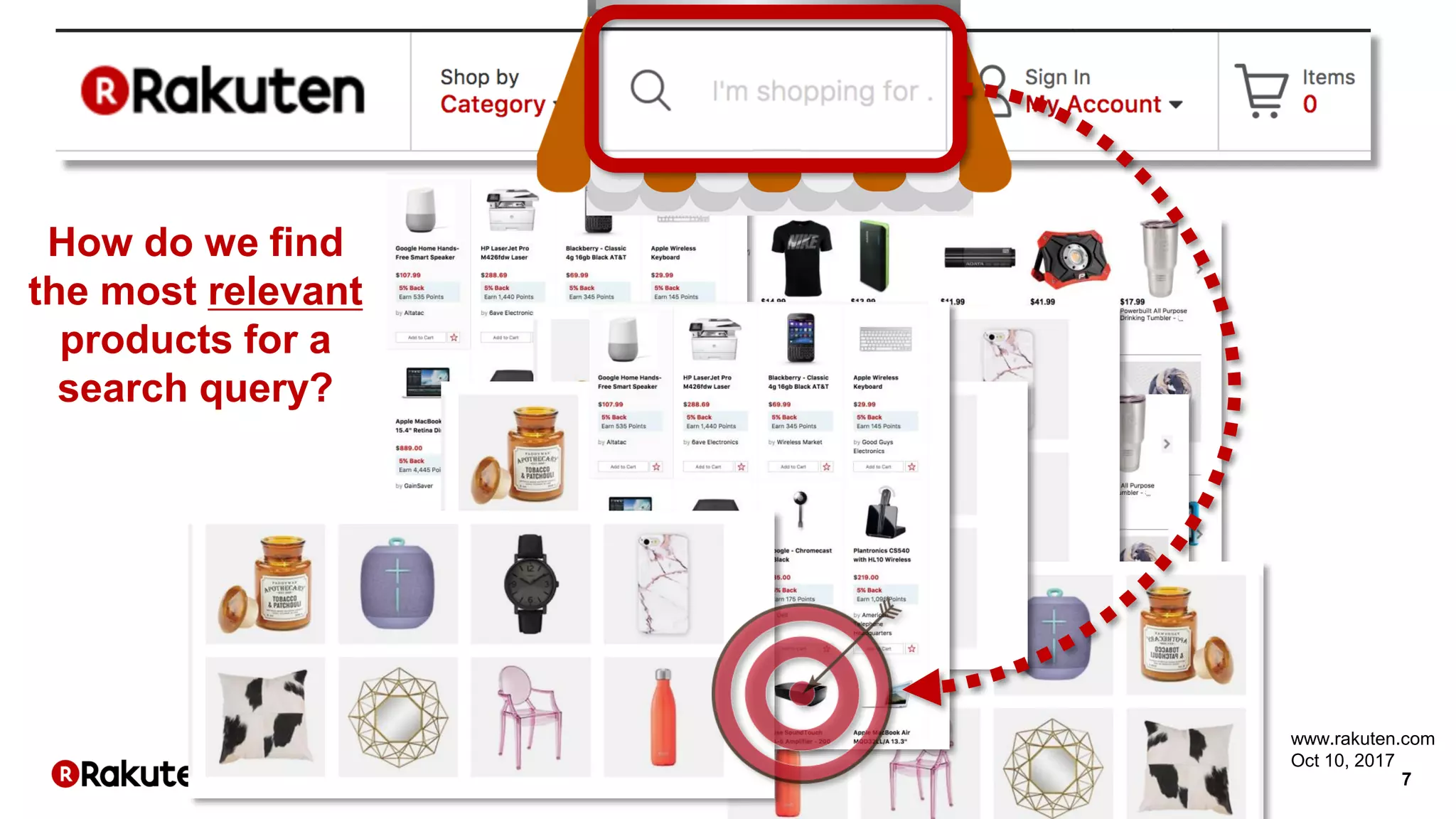
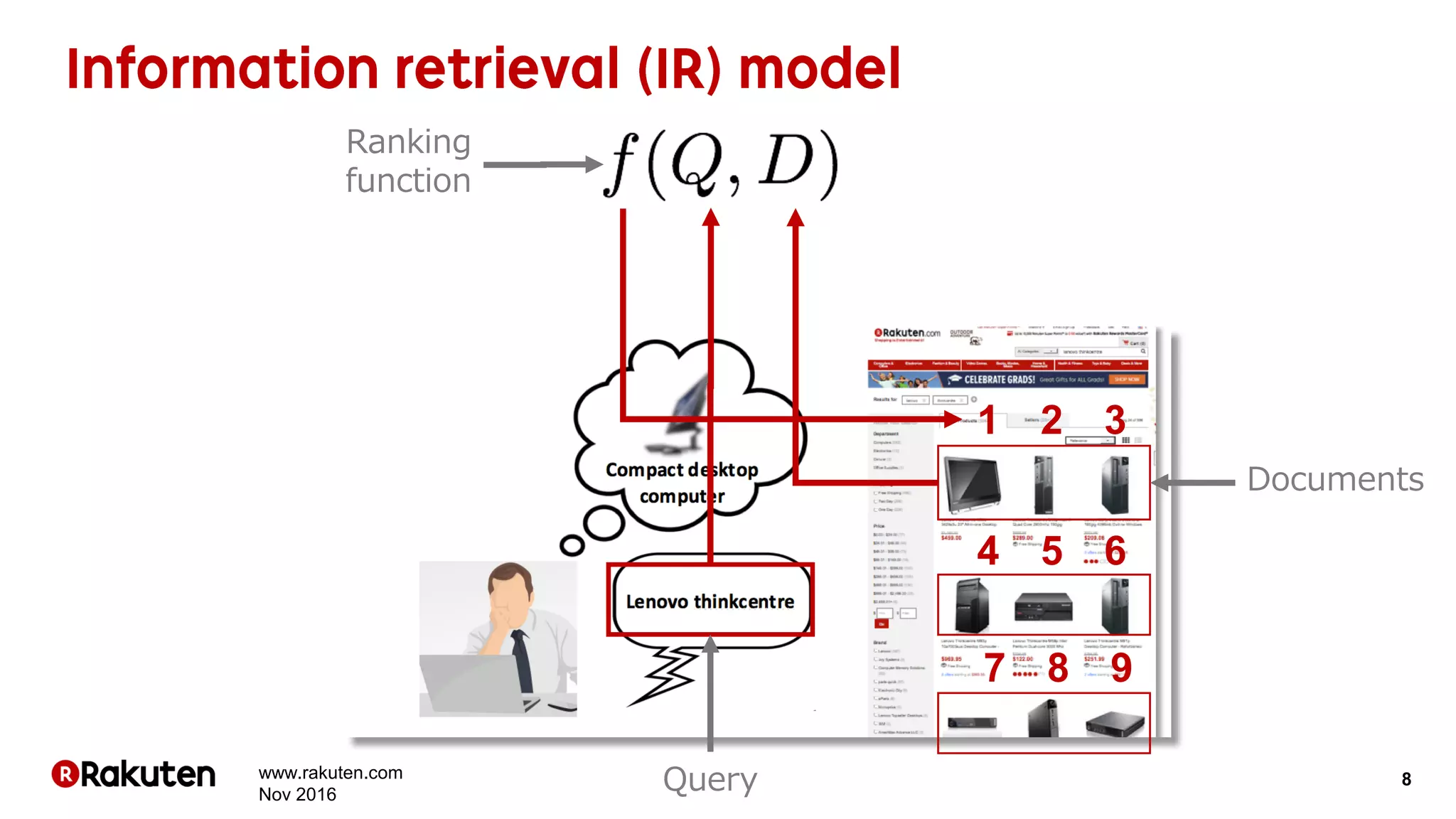





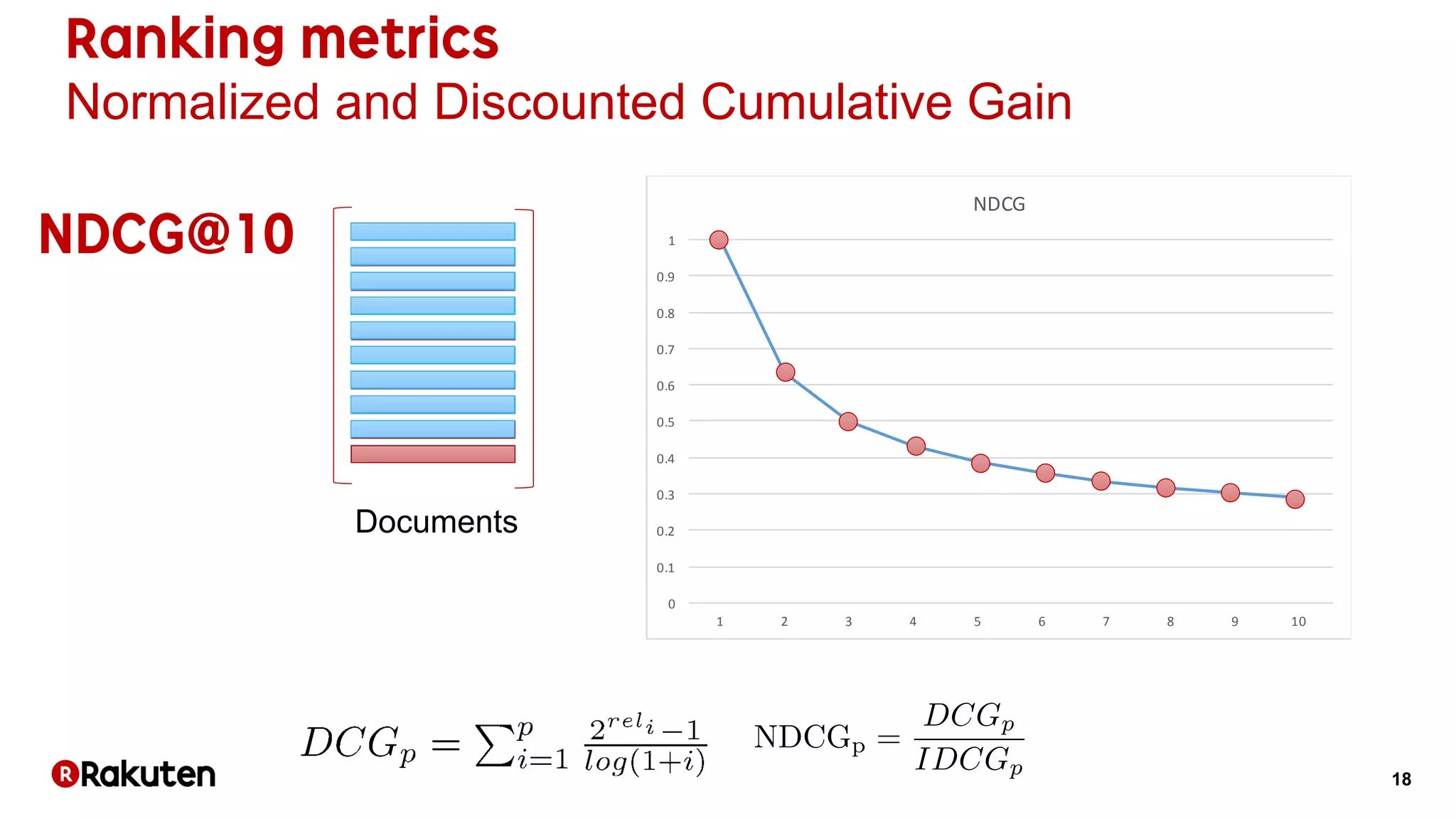




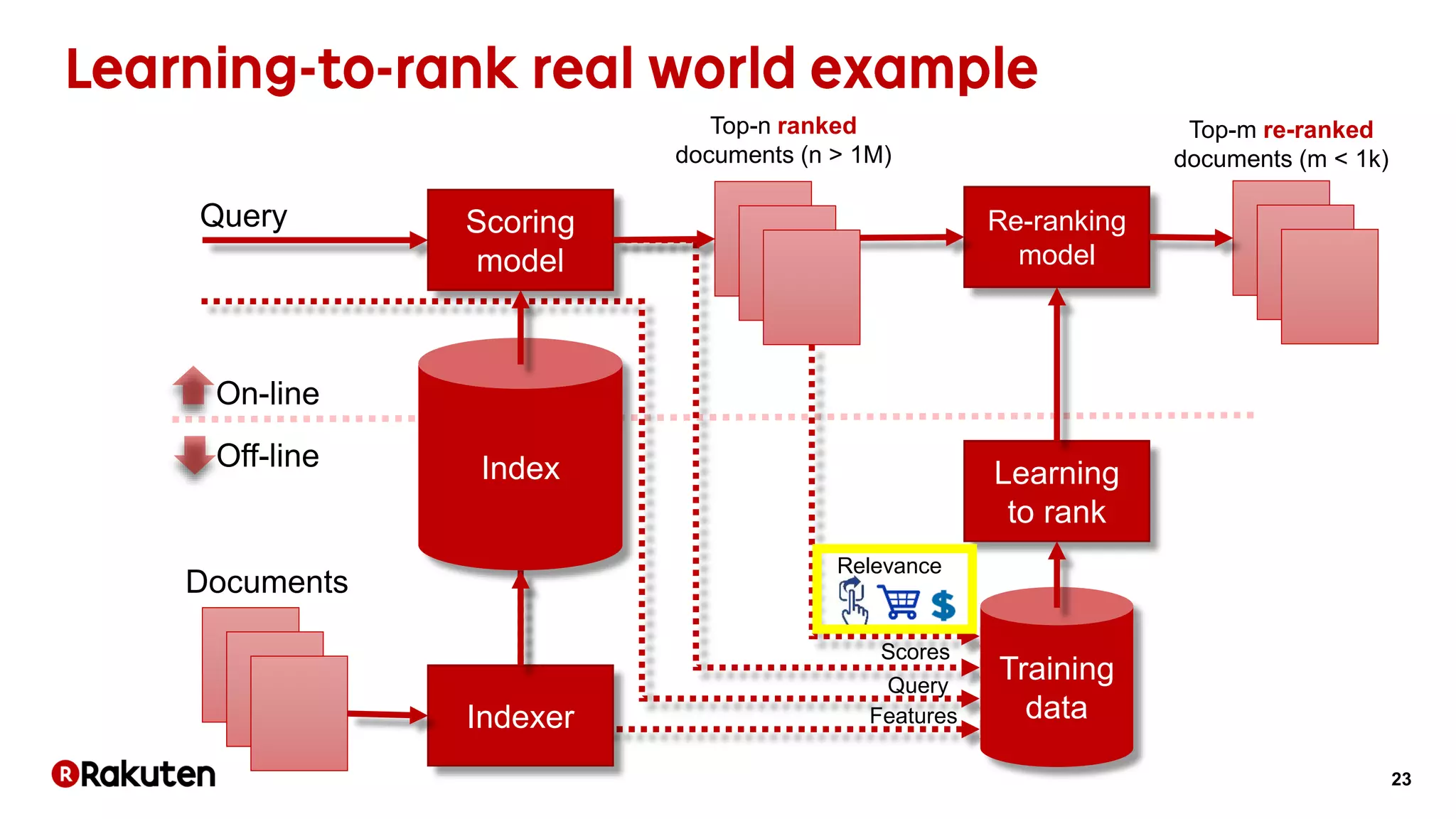
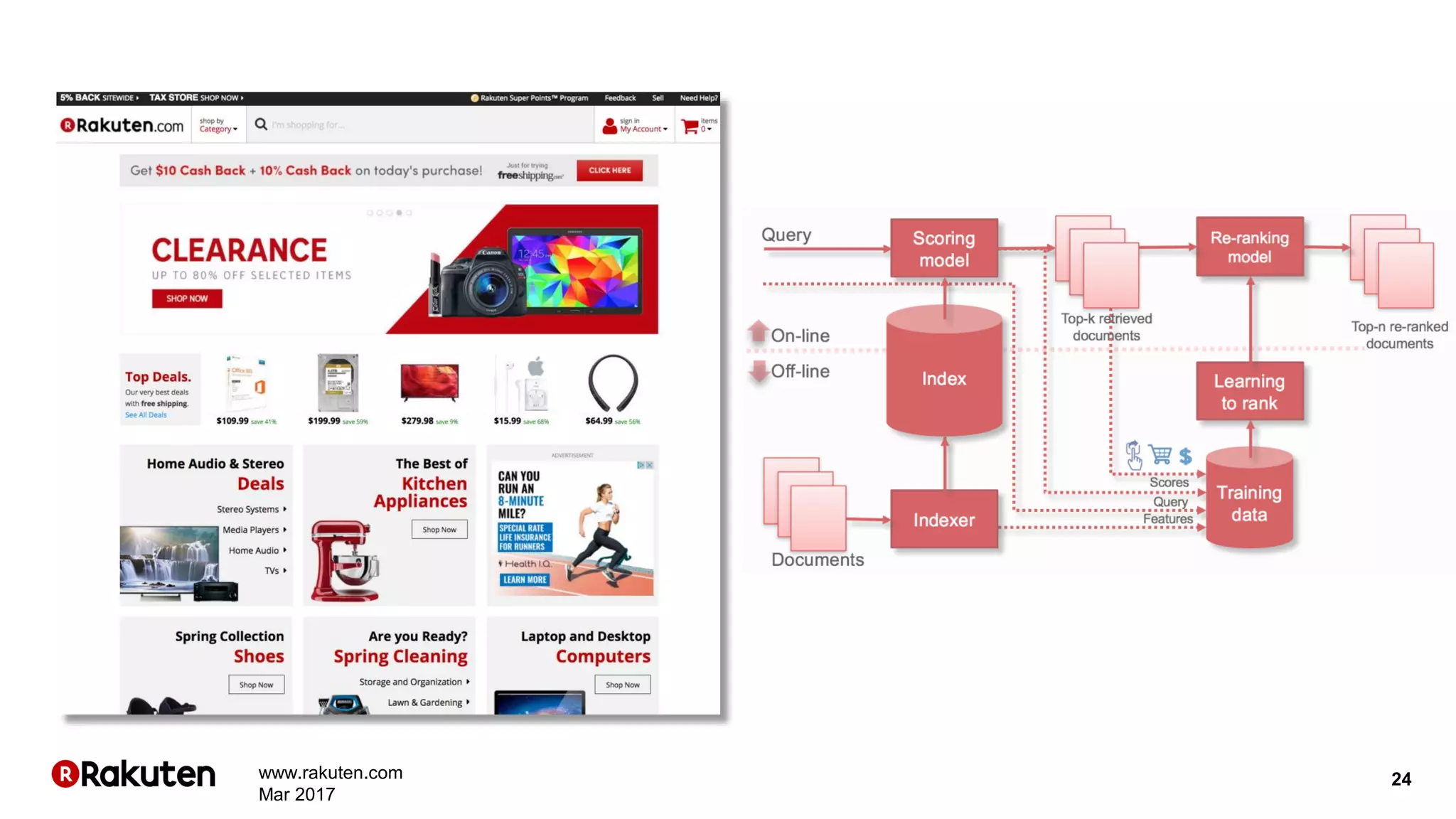

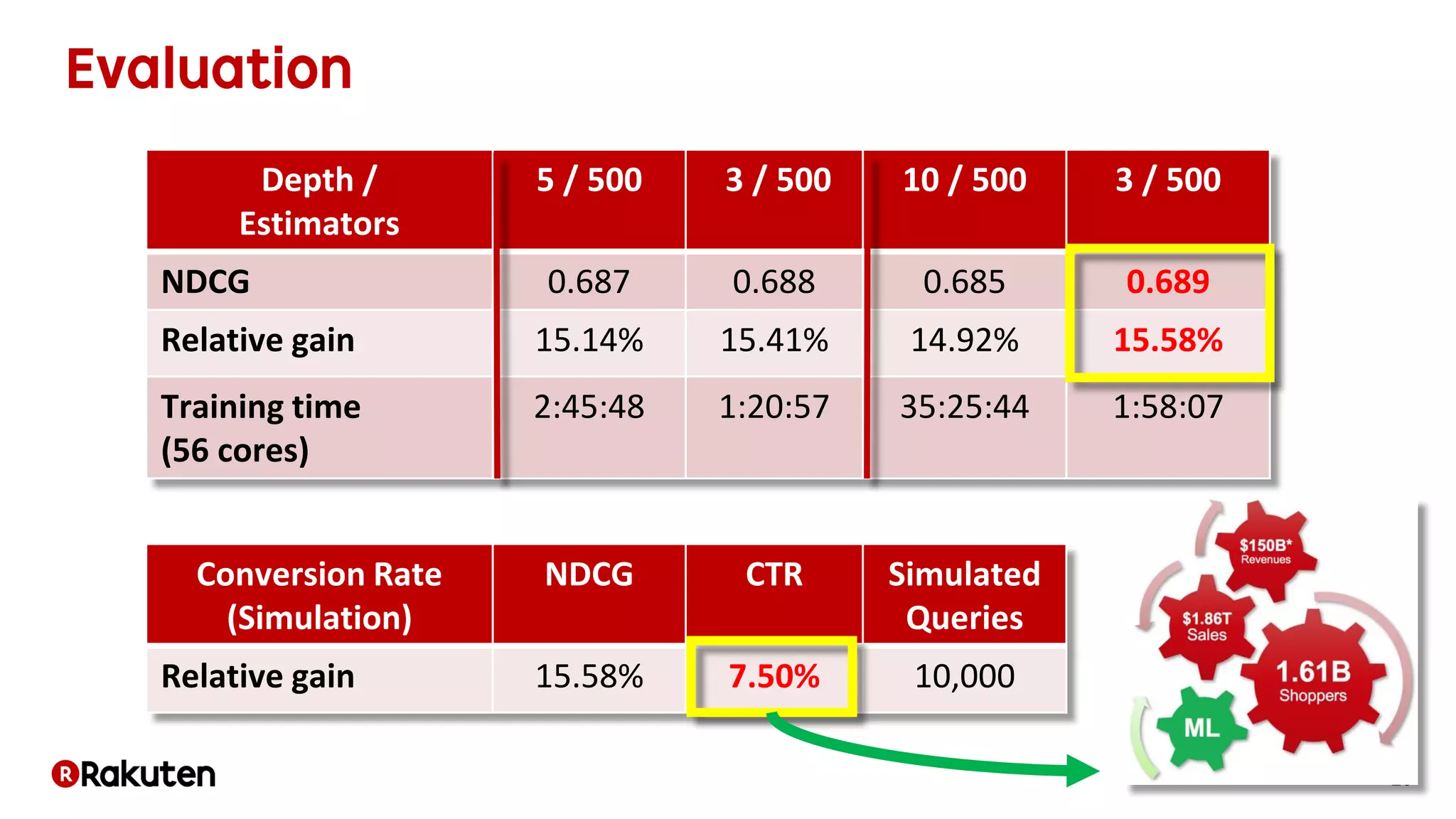
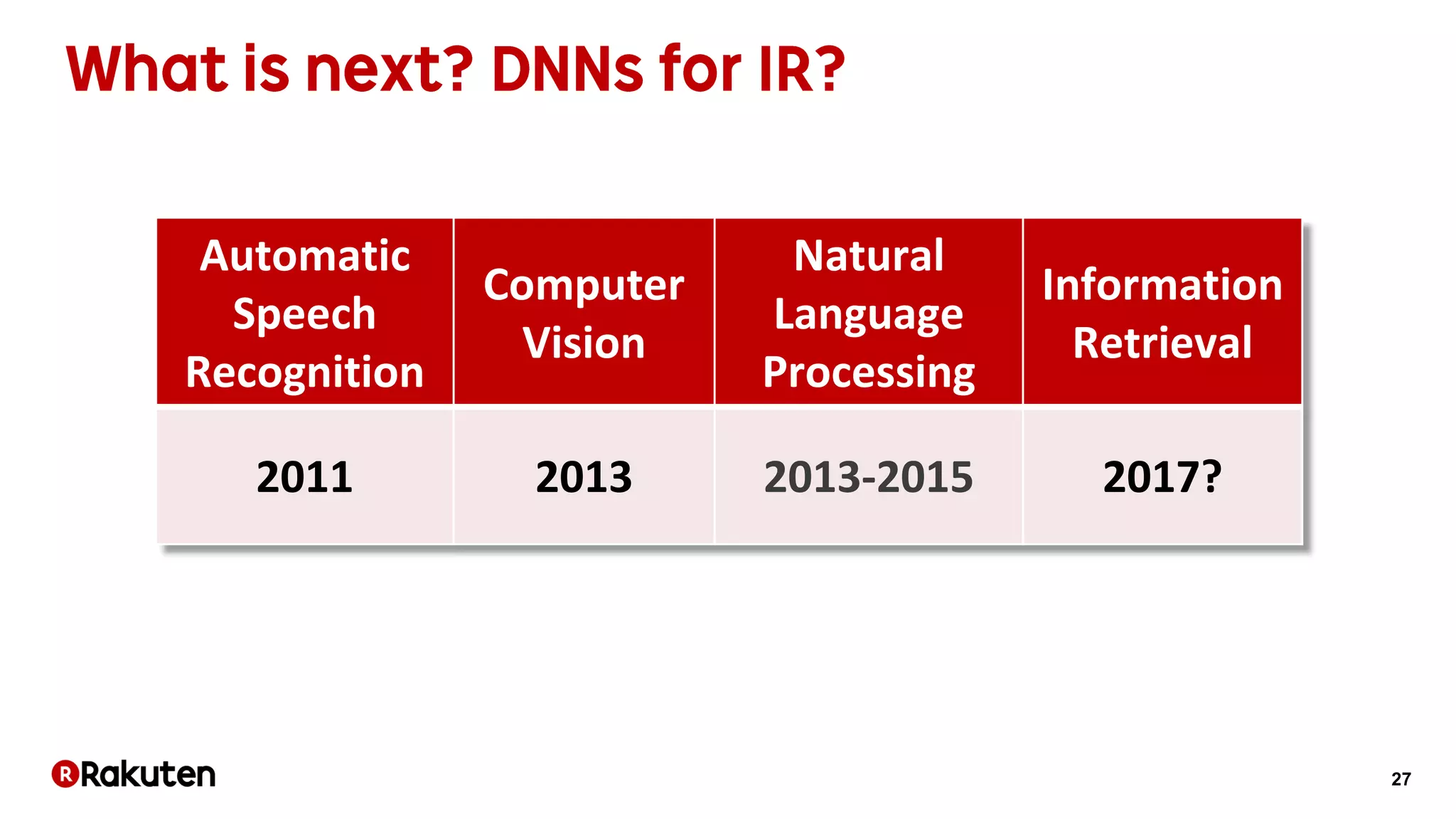
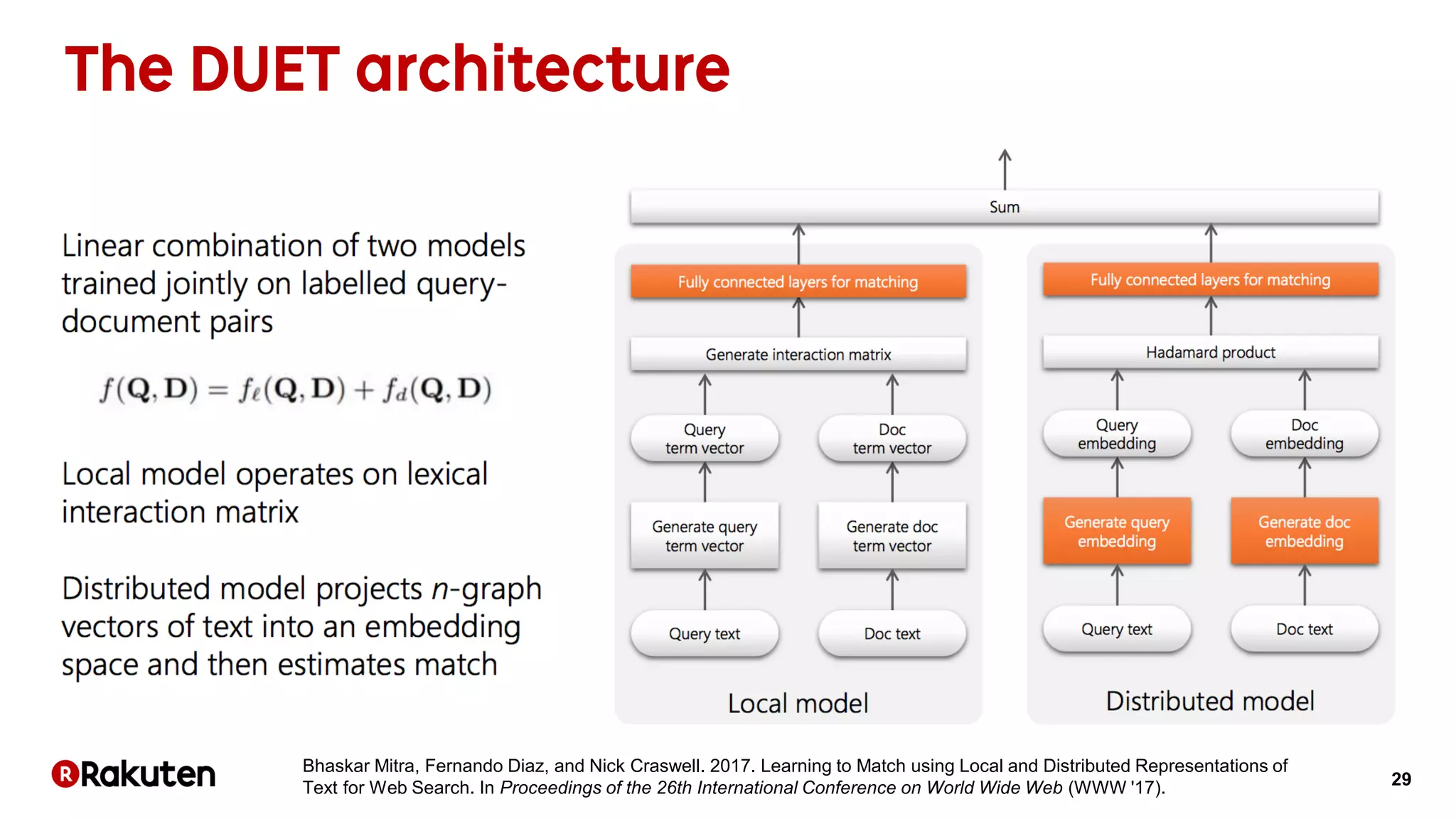
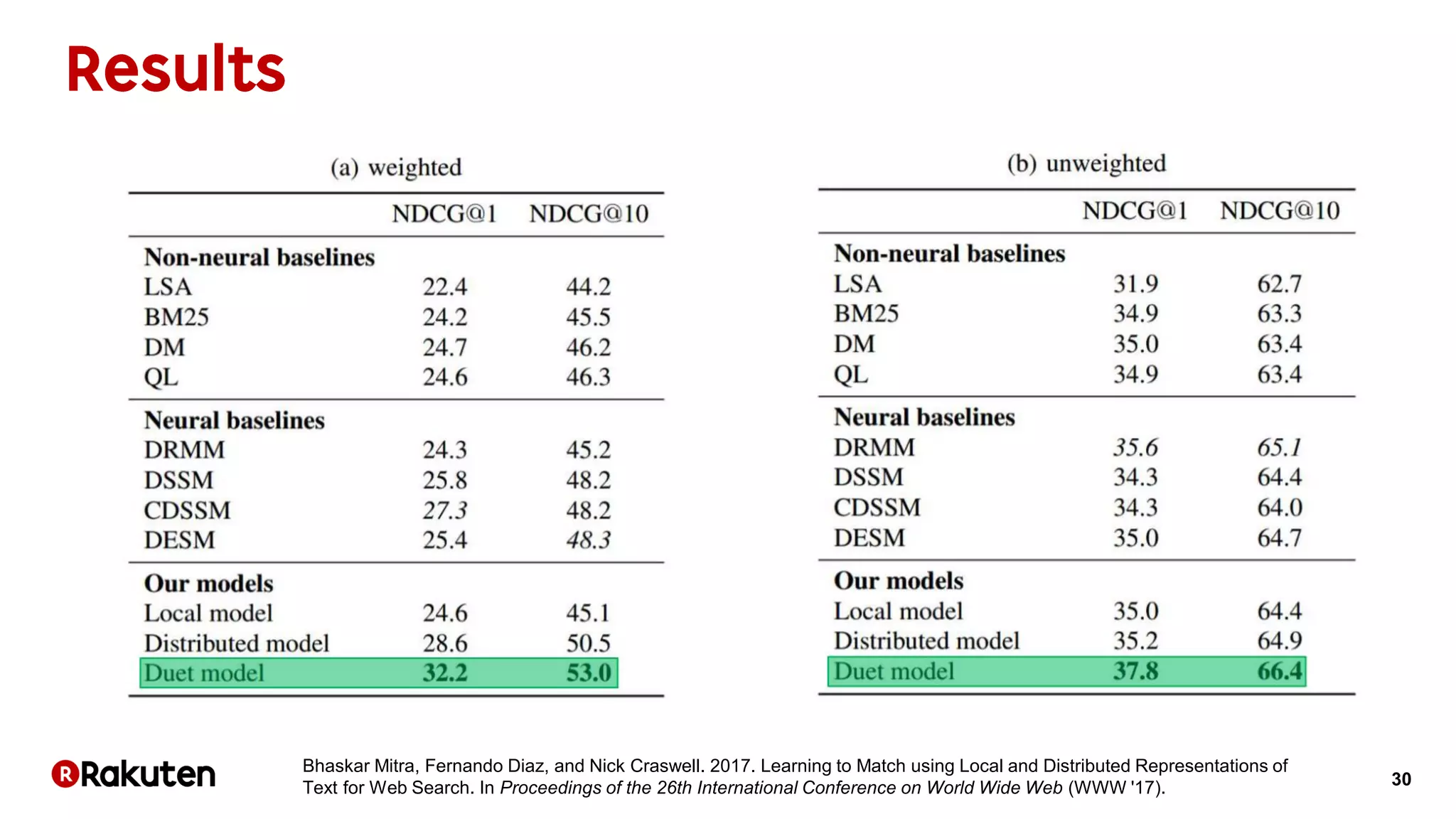



The document discusses learning-to-rank models for improving search relevance in e-commerce. It describes how traditional information retrieval models do not scale well to modern needs, while learning-to-rank methods can handle thousands of features and implicit user feedback data. The document reports that using listwise learning-to-rank with NDCG as the loss function improved NDCG by 15.6% and increased conversion rates by 7.5% on e-commerce data. It concludes that deep neural network methods may now outperform traditional machine learning for information retrieval tasks.










































































































