Downloaded 86 times




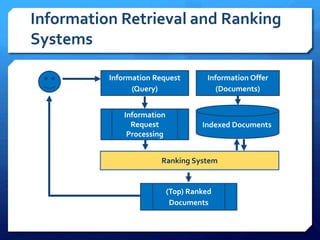
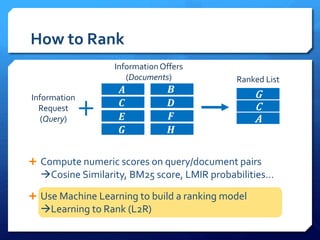
















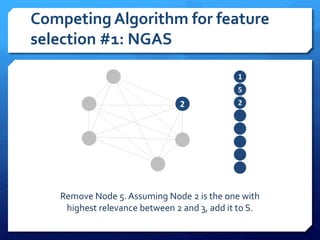



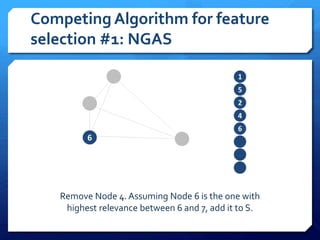
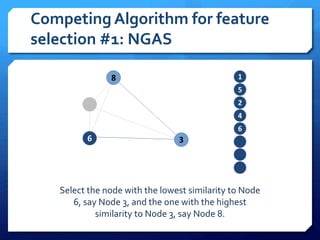





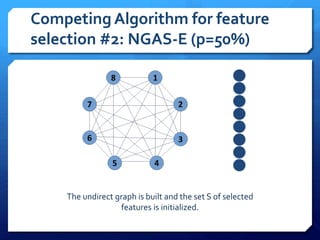
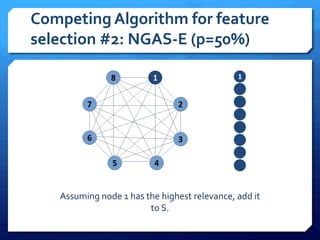

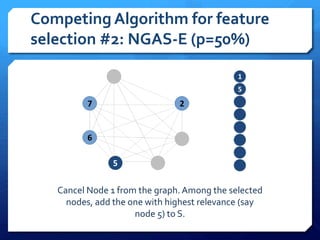






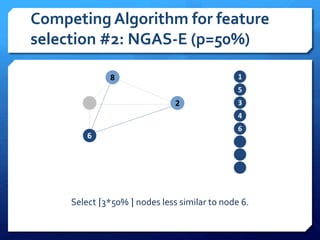











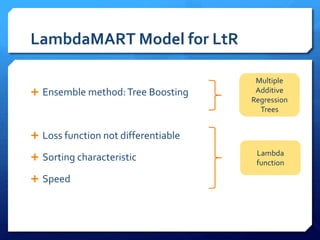
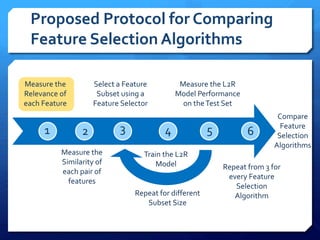
















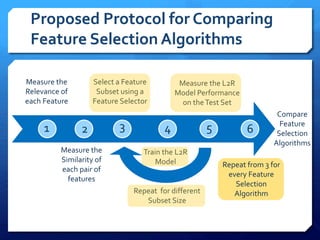

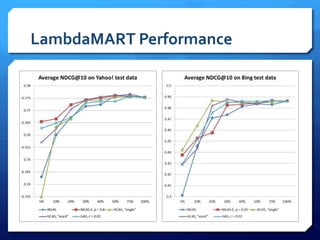
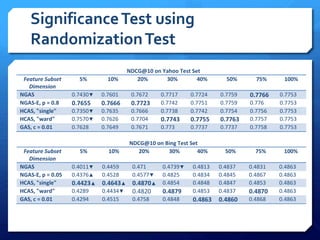




The document discusses feature selection algorithms for learning to rank, focusing on proposed feature selection protocols and their application to publicly available web search data. It outlines various competing algorithms including naive greedy search and hierarchical clustering, detailing methods to measure feature relevance and selection performance. Additionally, it describes machine learning strategies for ranking and provides insights into the operational mechanics of ranking systems and their evaluation metrics.











































































































