Downloaded 164 times

















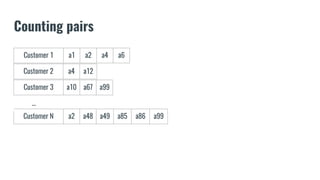
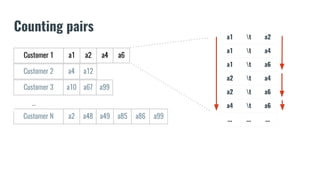
![Counting assets
a1 t 200
a2 t 1850
a3 t 800
a4 t 1100
a5 t 120
... ... ...
asset_counts = {}
with open("asset_counts.txt", 'r') as f:
for line in f:
items = line.split(‘t’)
asset, count = items[0], items[1]
dict_asset_counts[asset] = count
Let’s assume we saved on the file “asset_counts.txt” the counts for each
available asset on our dataset and we want to save them in a dict()](https://image.slidesharecdn.com/letthemusicplay-nocode-170411131257/85/Recommendation-Systems-in-banking-and-Financial-Services-27-320.jpg)



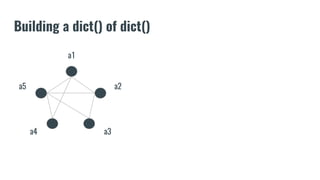
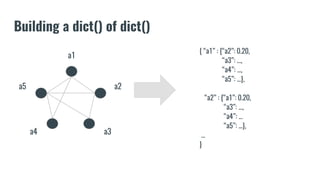
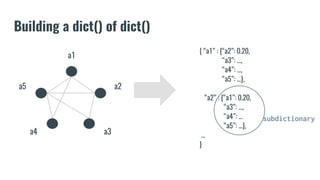

















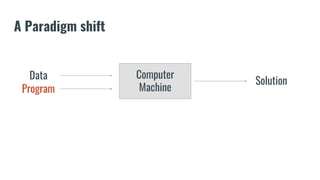
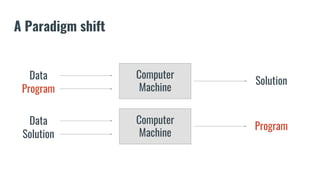
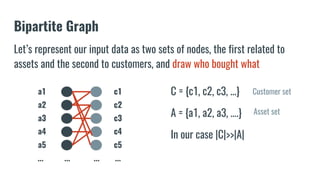
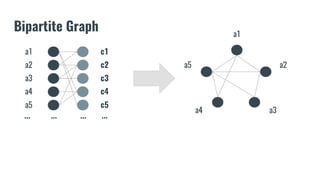
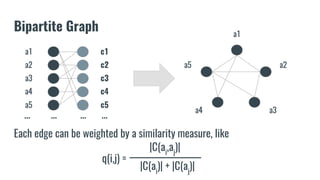
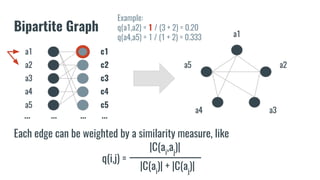
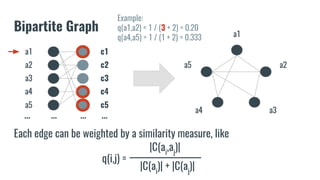
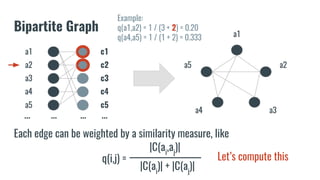
The document discusses recommendation systems in banking and financial services. It describes different types of recommendation systems including content-based filtering, collaborative filtering, and hybrid filtering. It then discusses how recommendation systems could be useful in banking by using a bipartite graph and word embedding approaches to represent customer and asset data and identify relationships between them. Code examples are provided for implementing some of these recommendation system techniques.












































![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt2931-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt3441-thumbnail.jpg?width=640&height=640&fit=bounds)









































