Download as PDF, PPTX


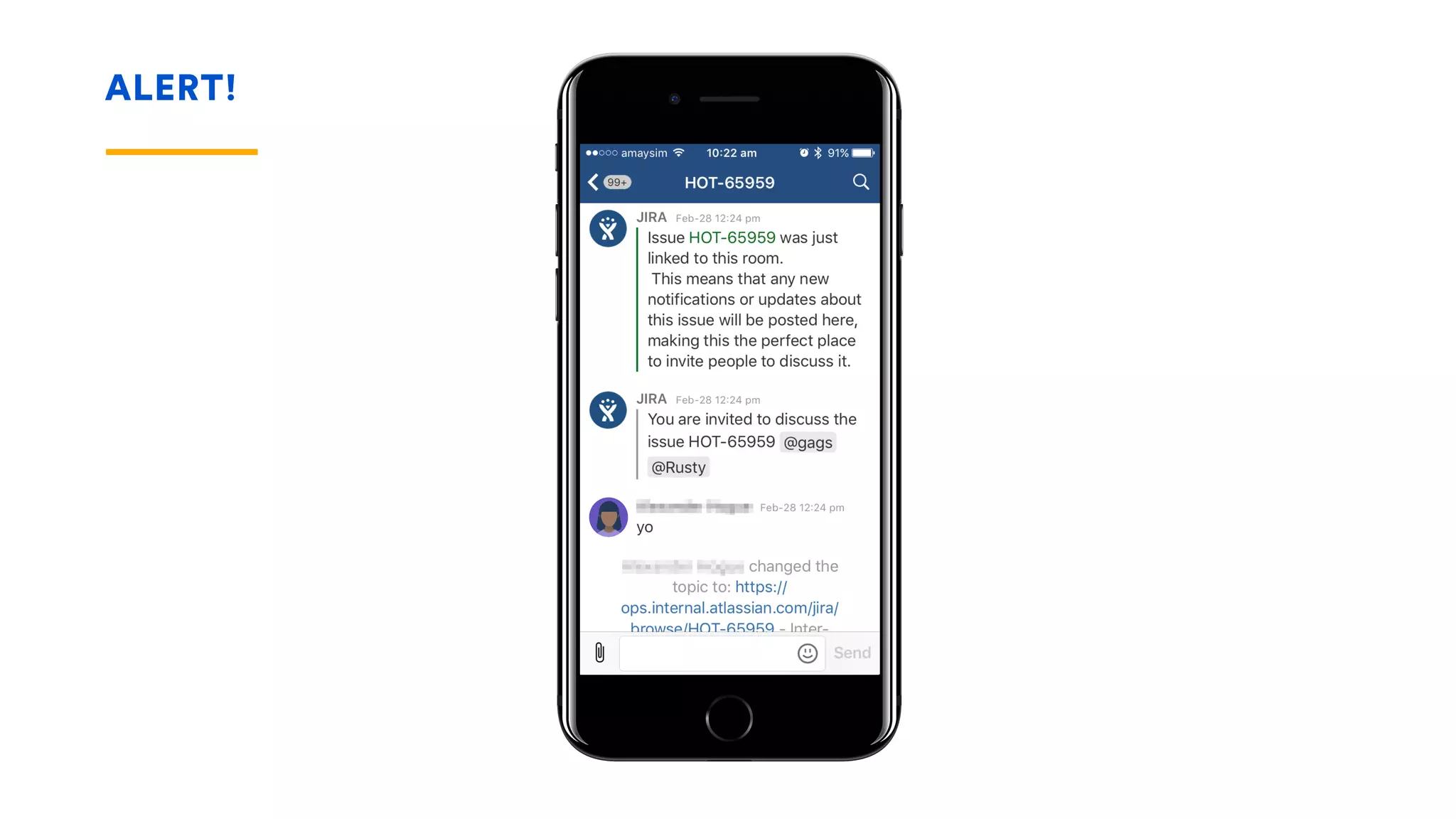

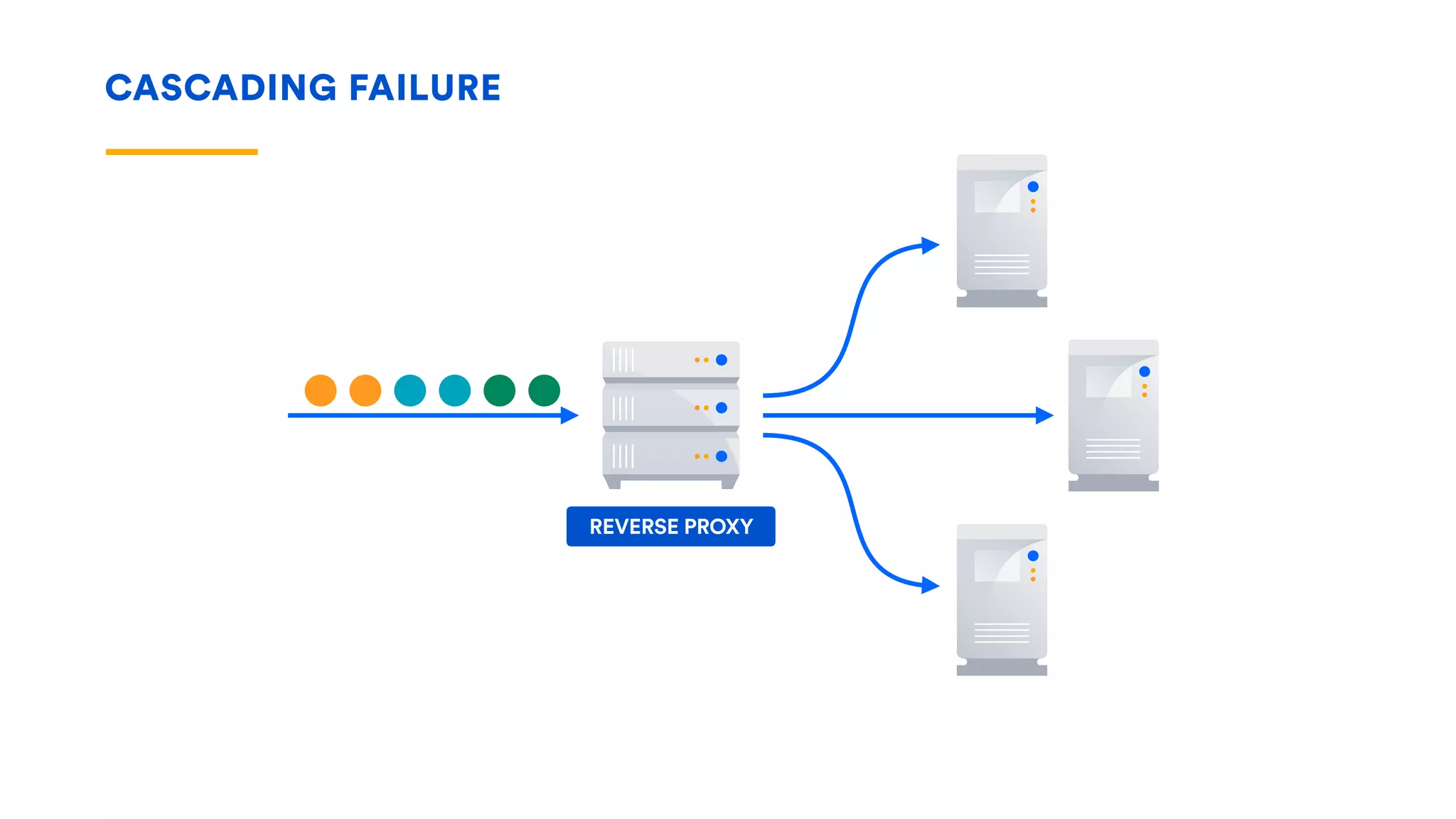
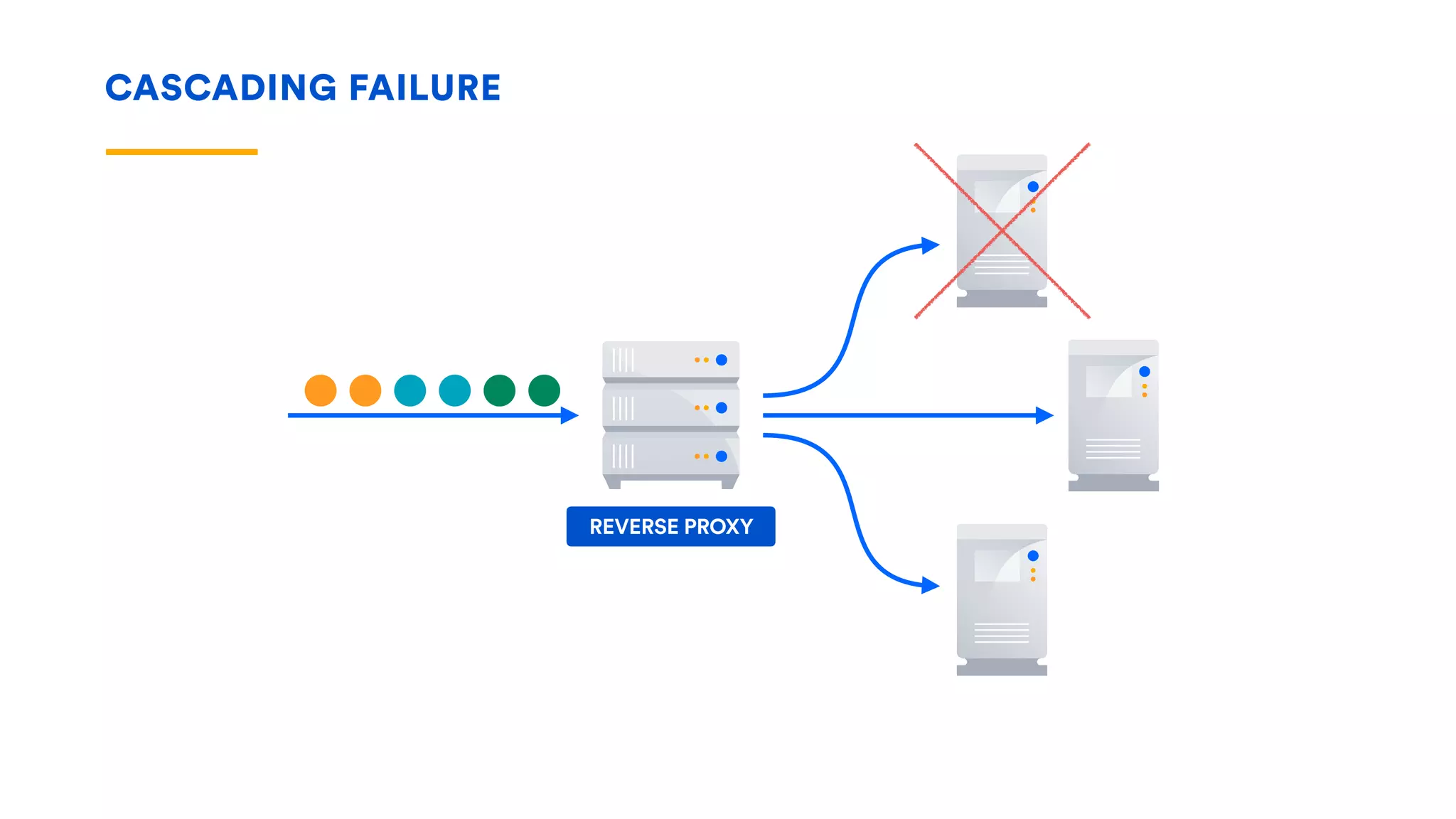






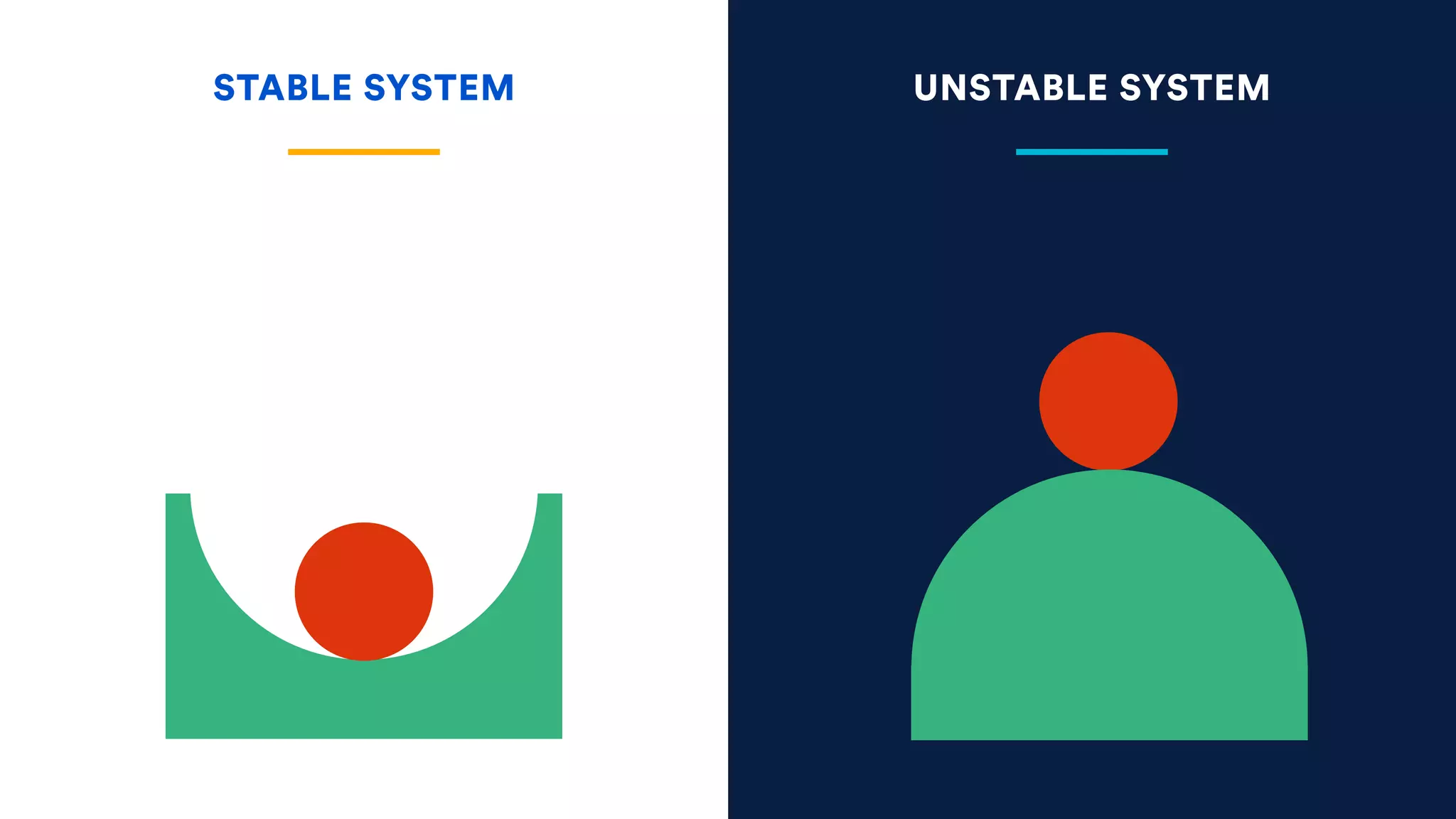





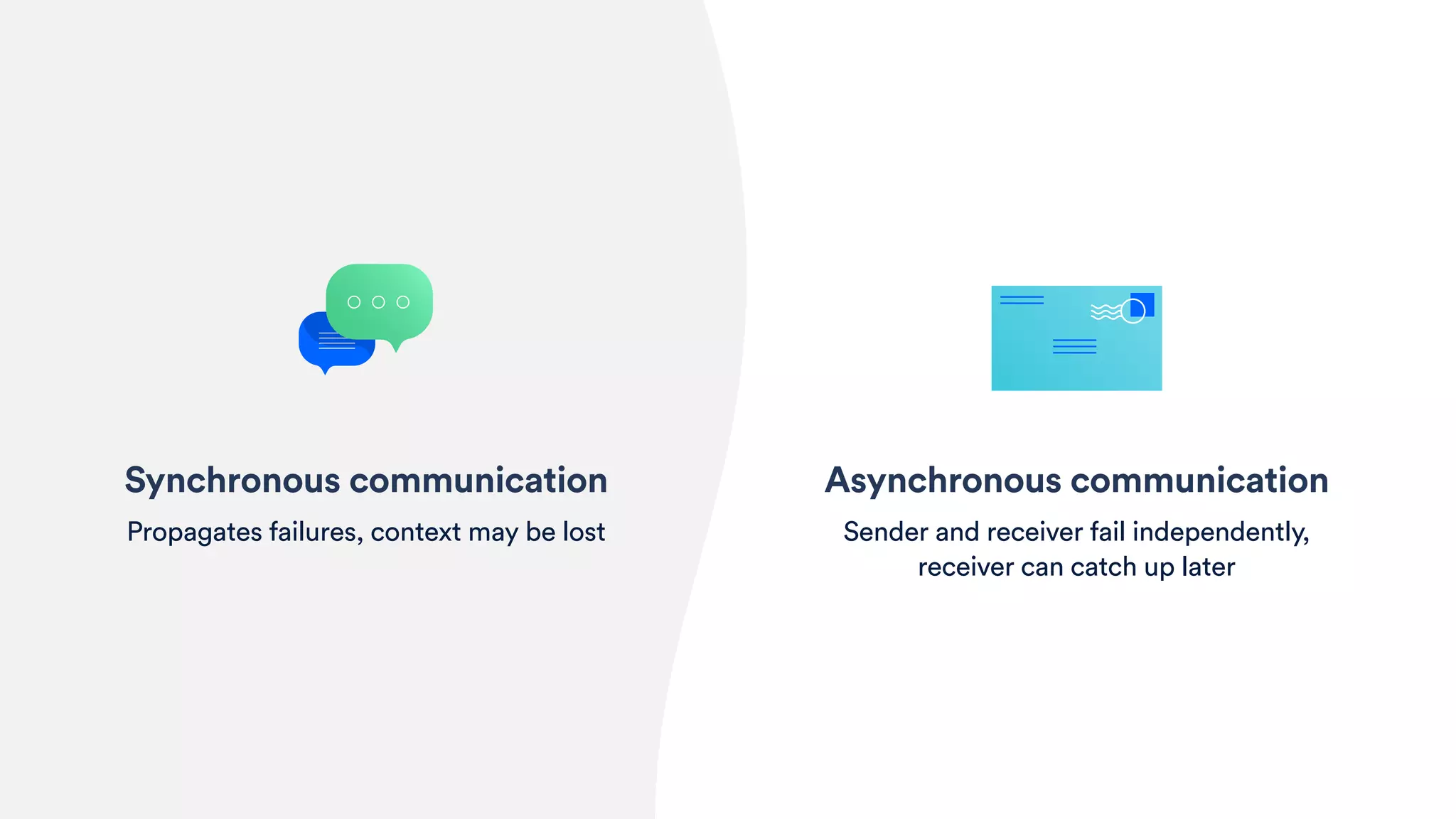

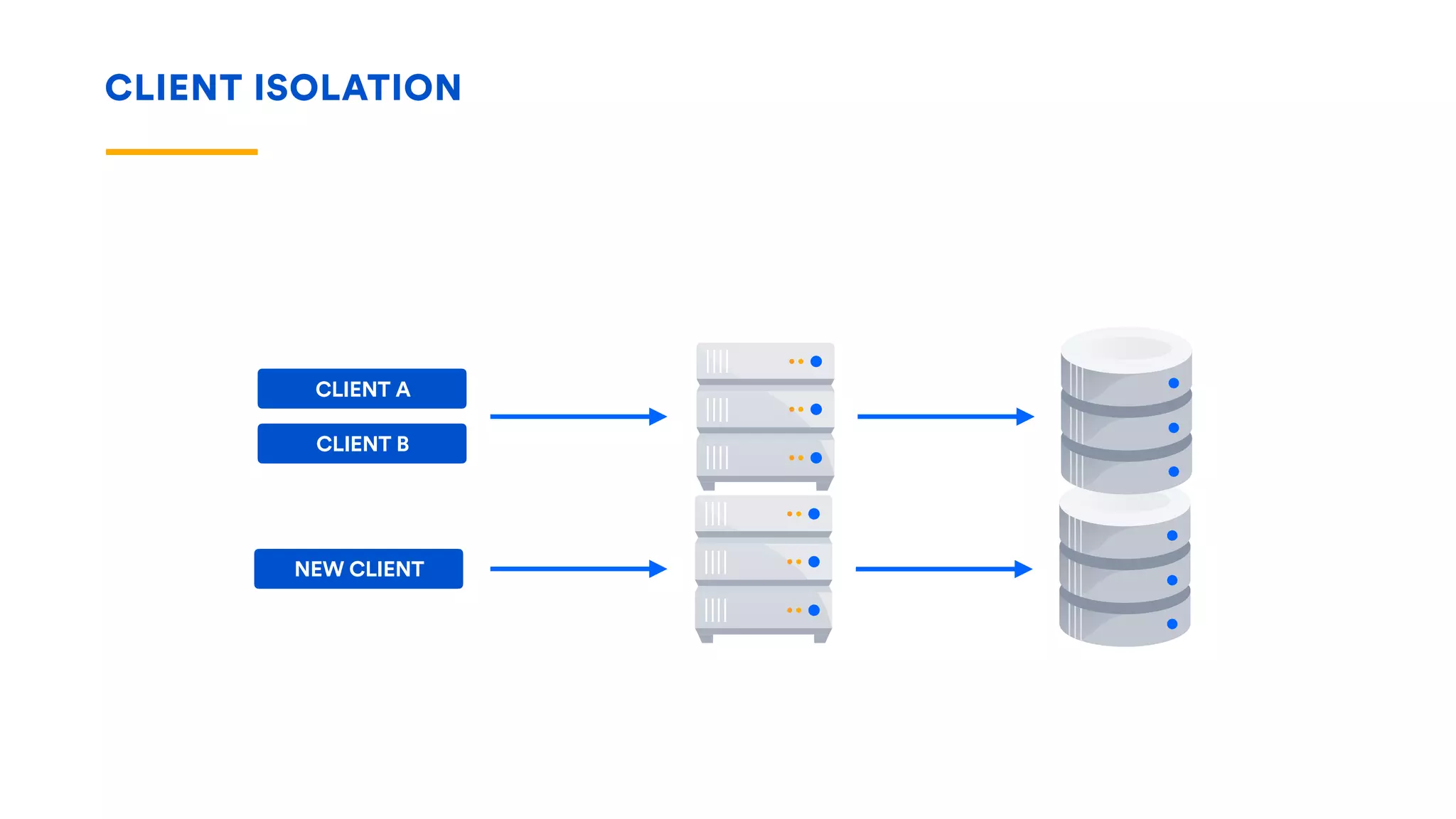











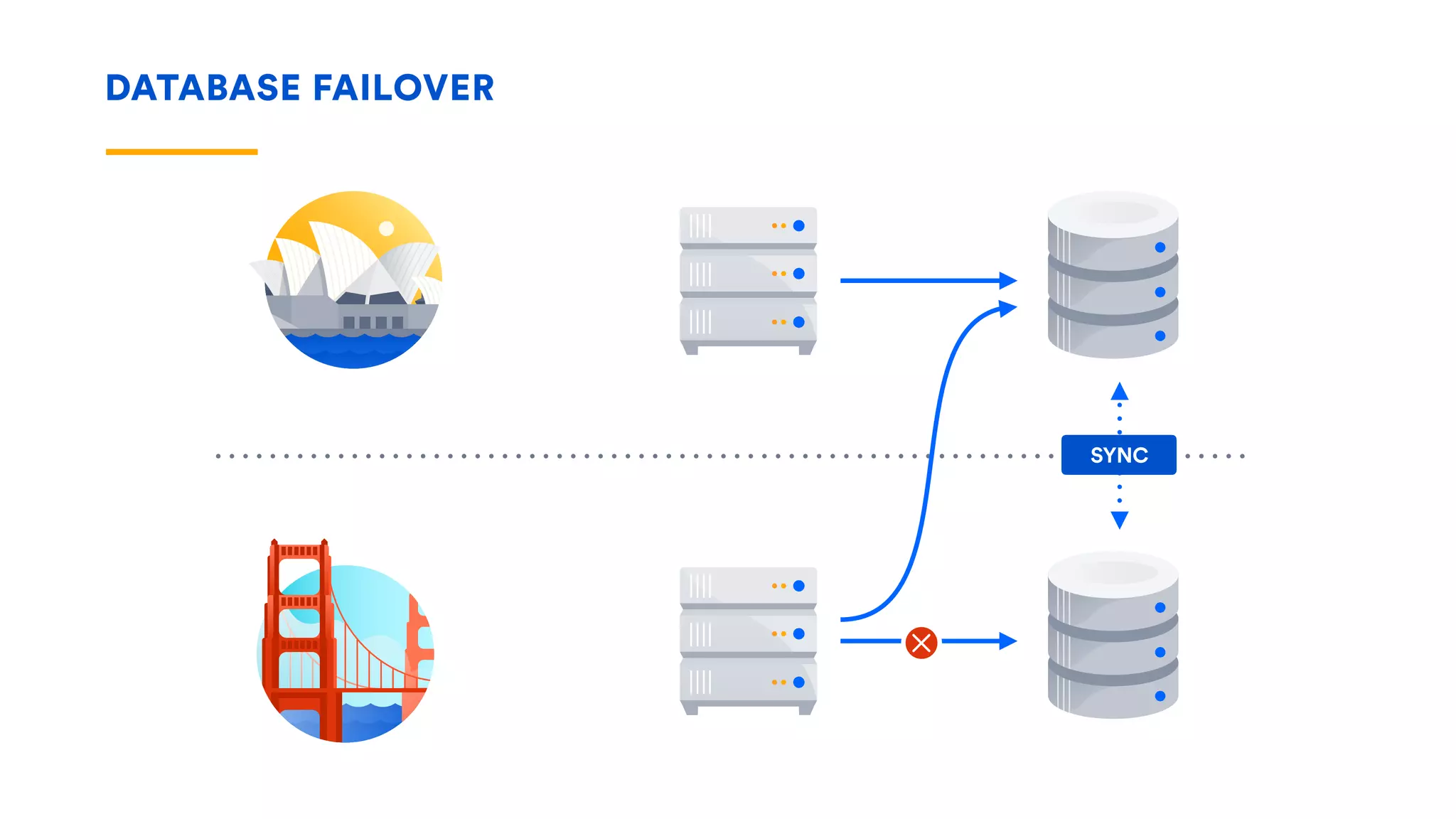



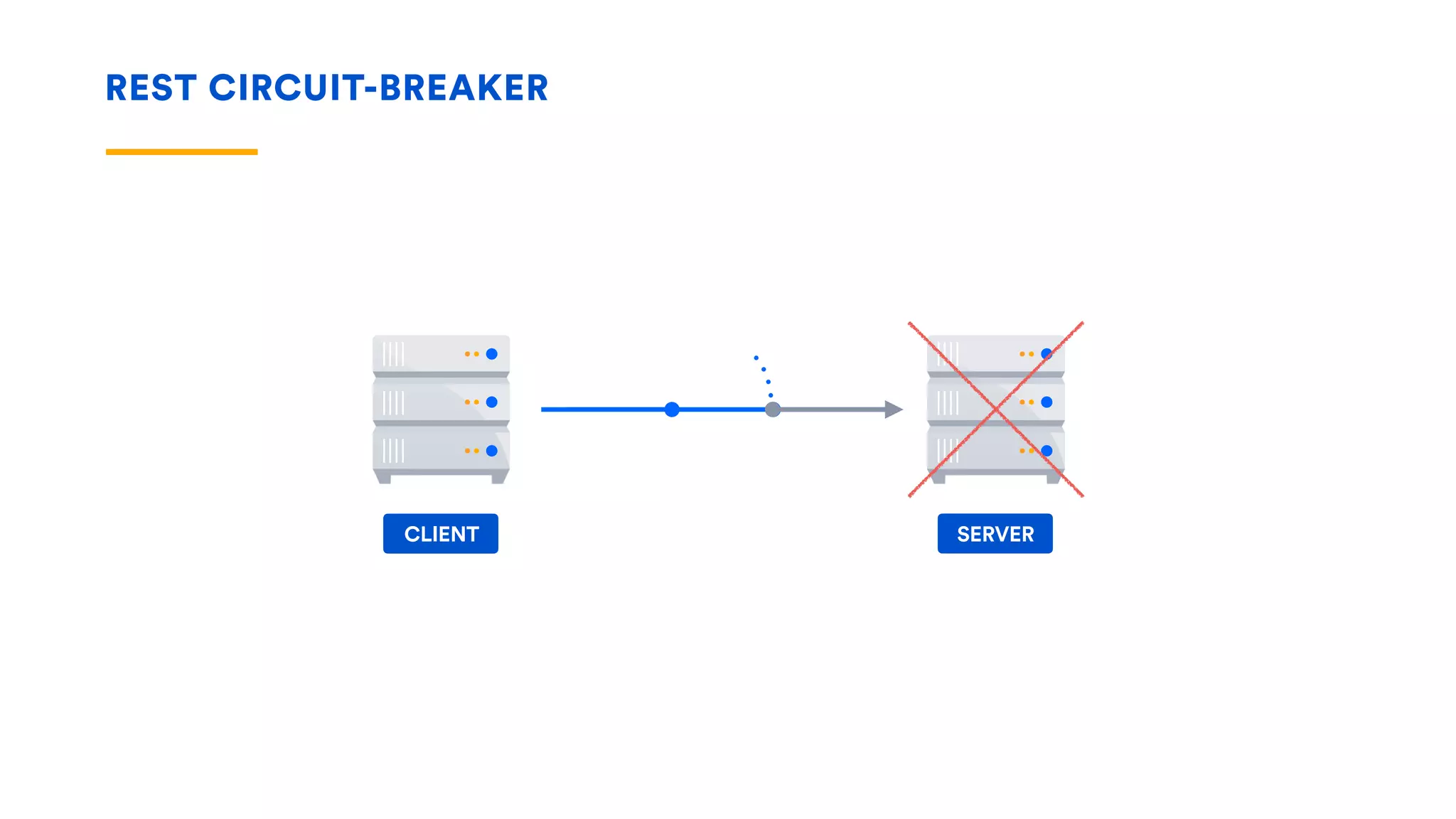


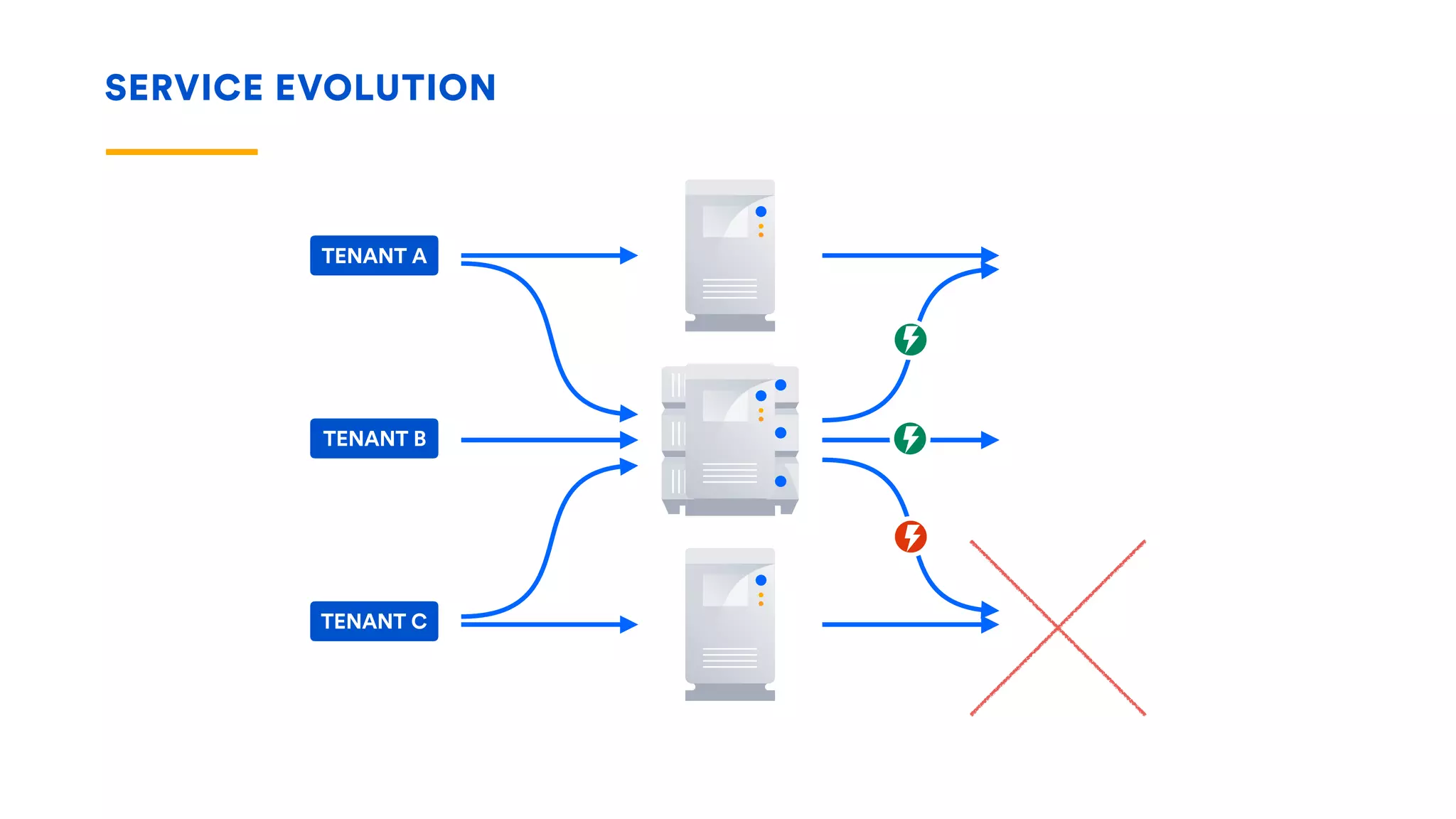








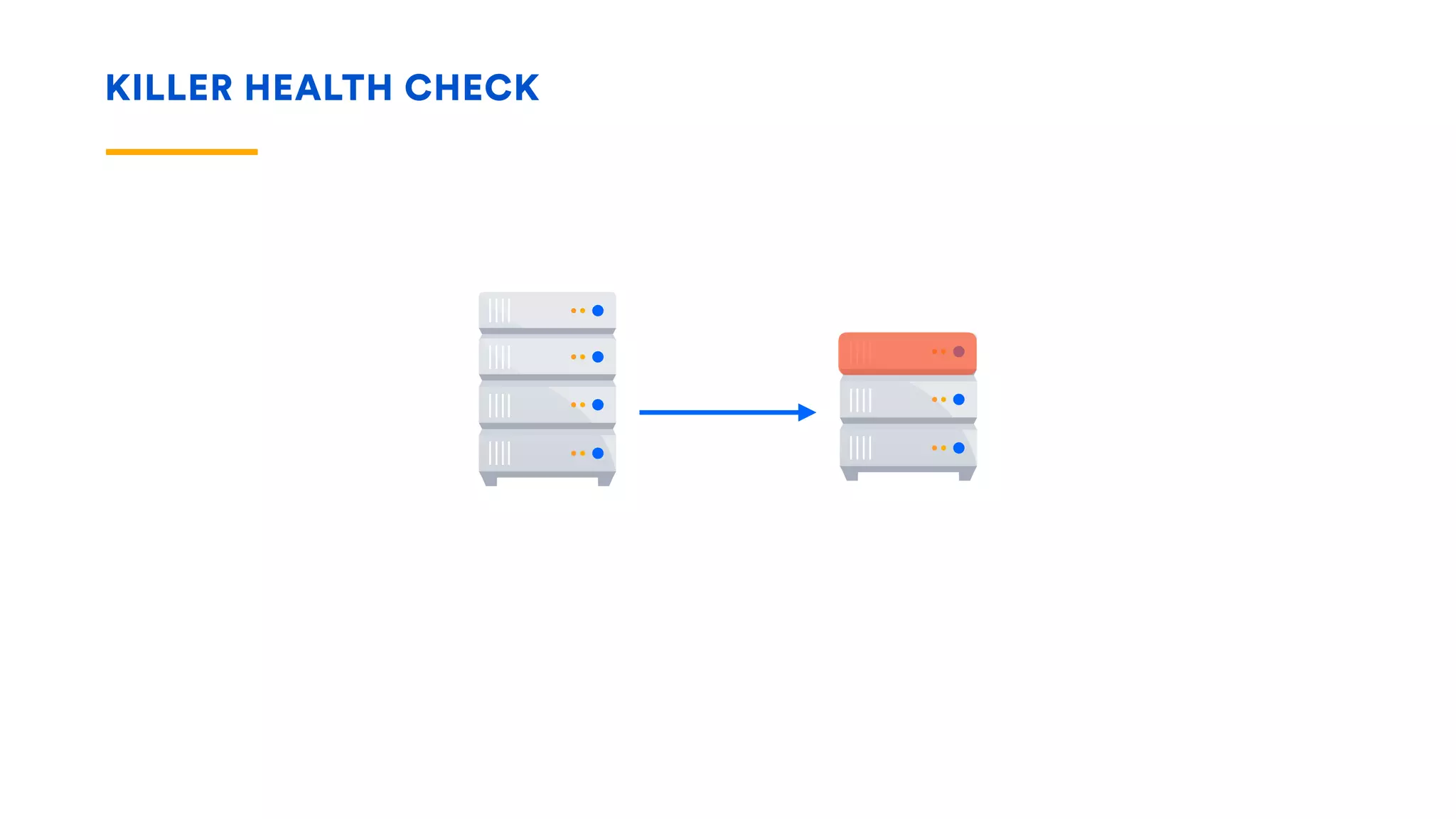



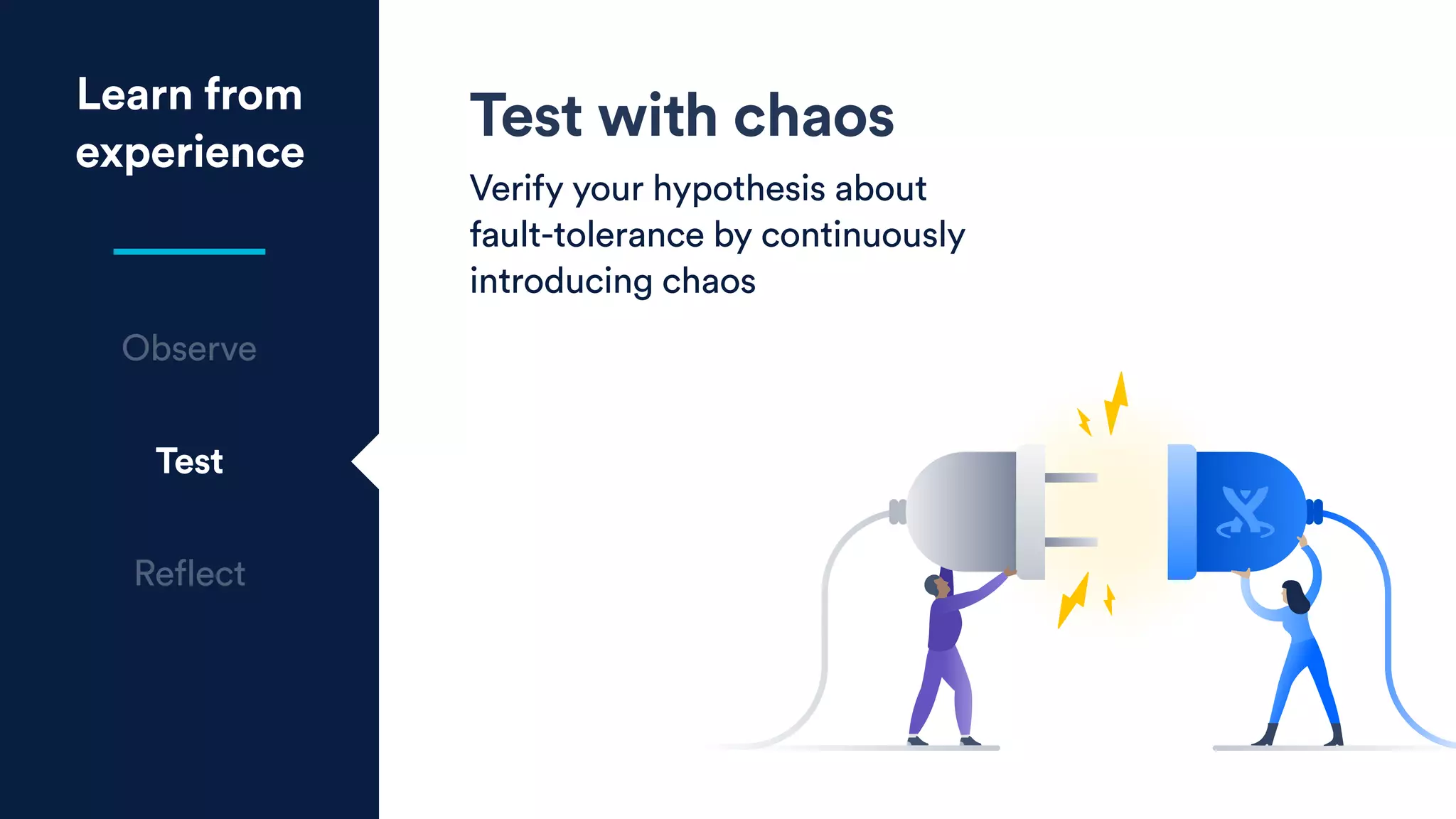


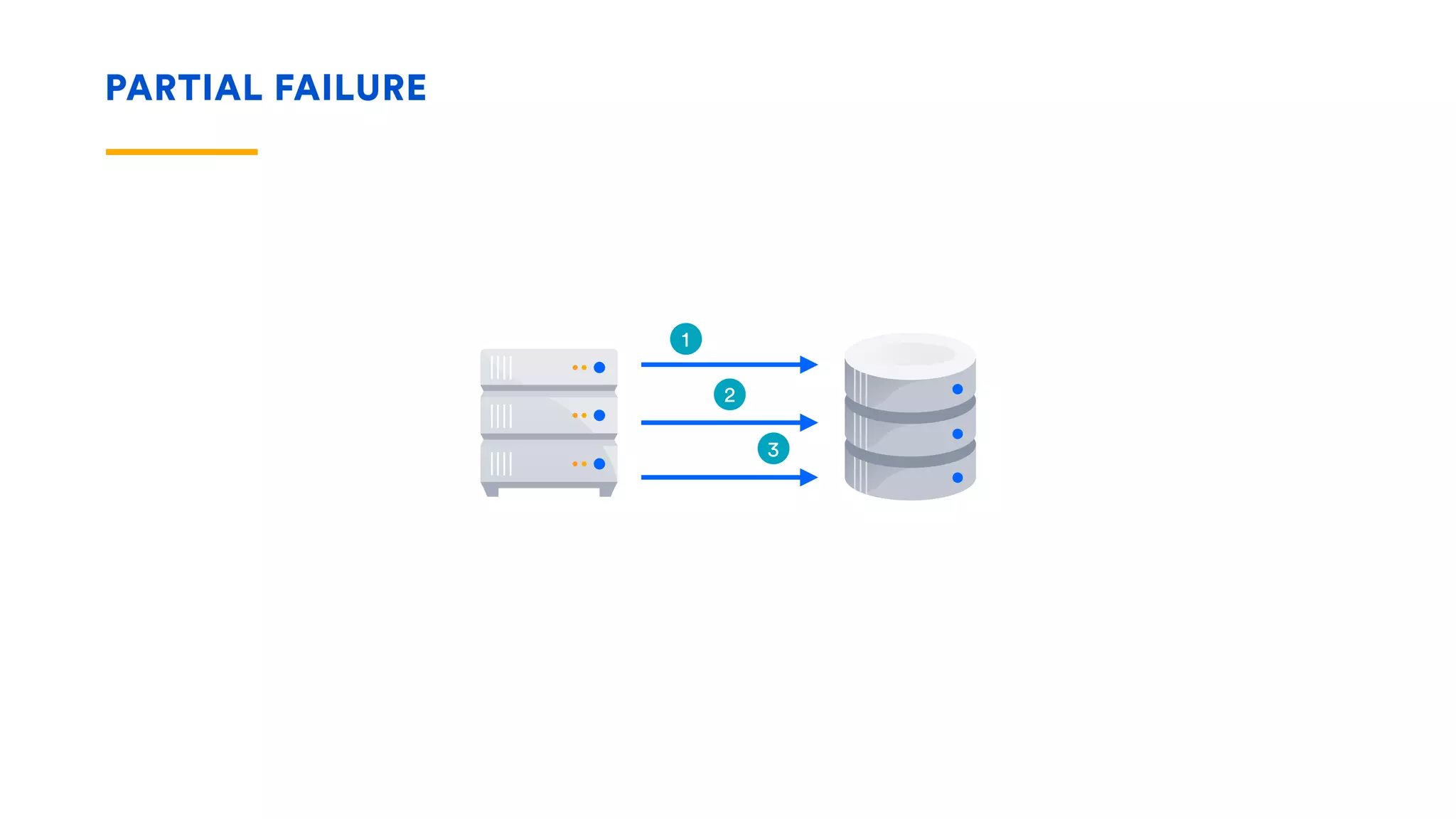
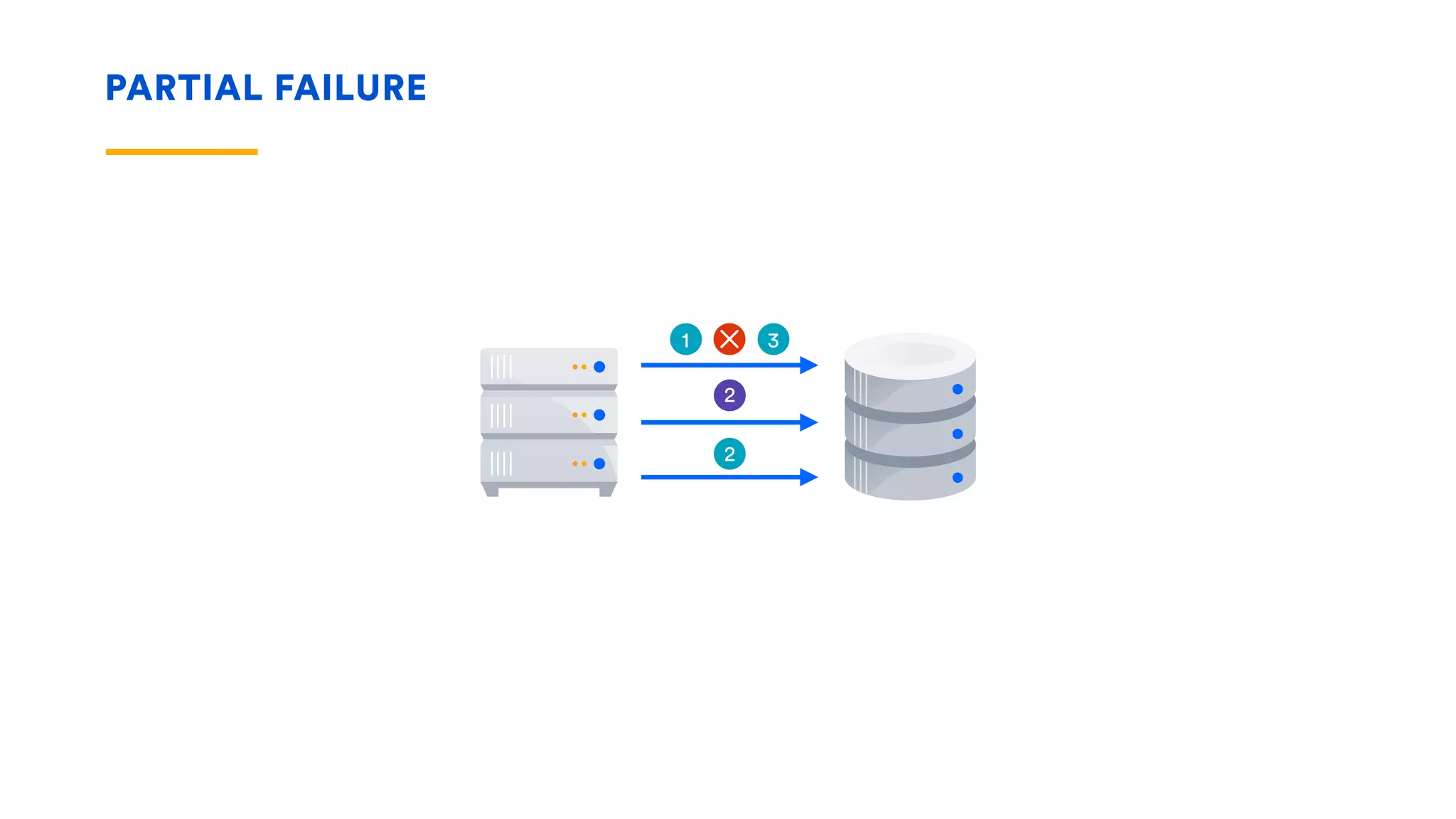
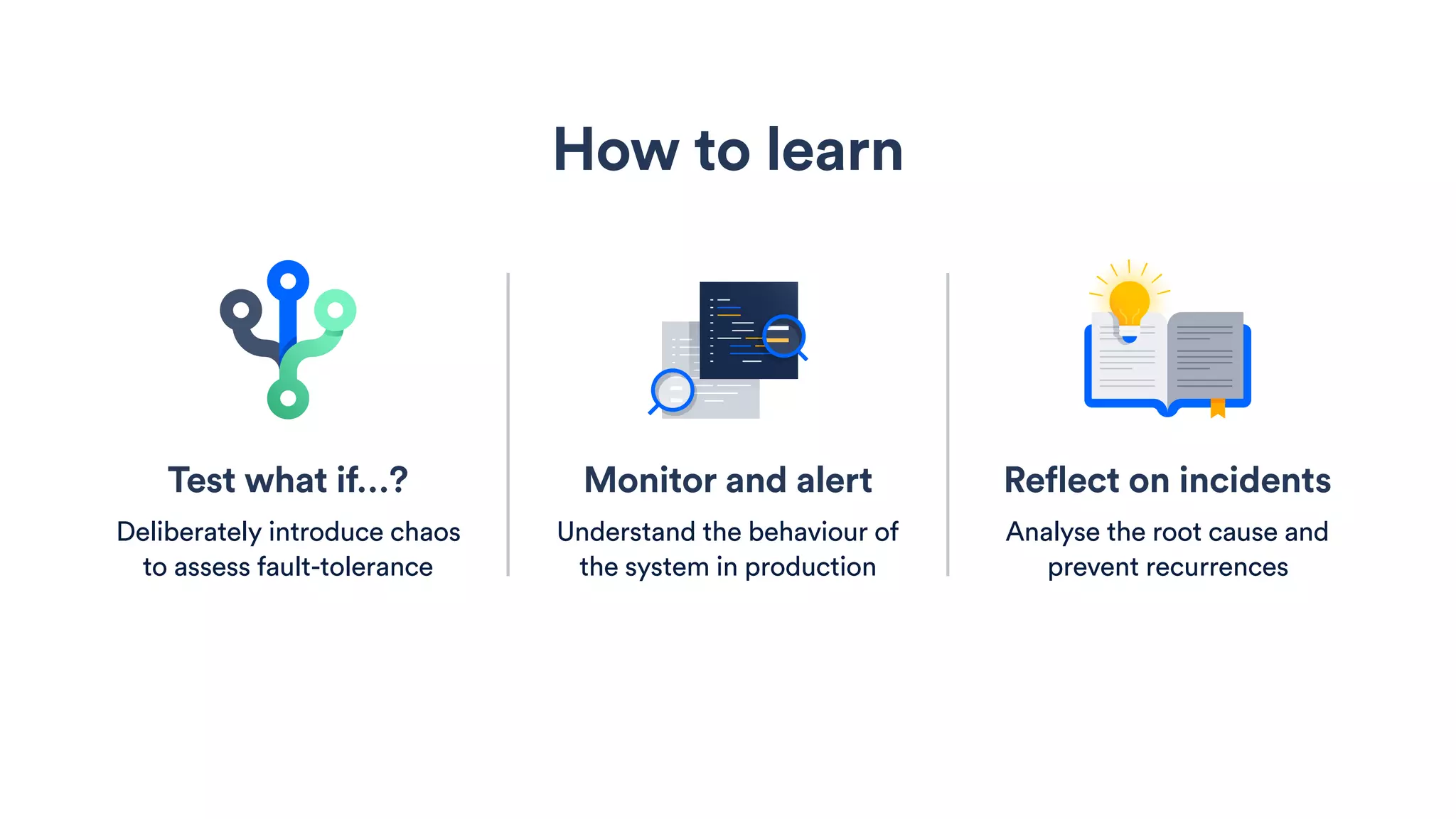







The document outlines five essential techniques for building fault-tolerant systems: containment, fail fast, escape, adjust, and learn. It emphasizes the importance of anticipating faults, implementing measures to minimize their impact, and fostering a culture of continuous improvement through monitoring and learning from incidents. These strategies aim to ensure system resilience and maintain availability even in the face of component failures.










































































































