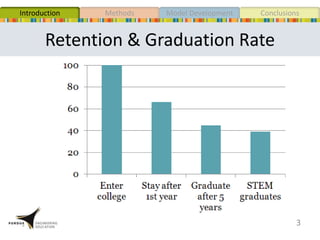
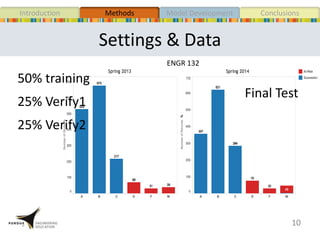
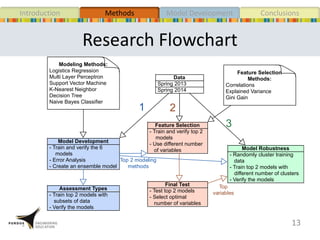
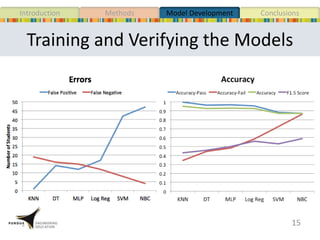
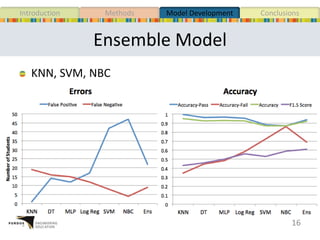
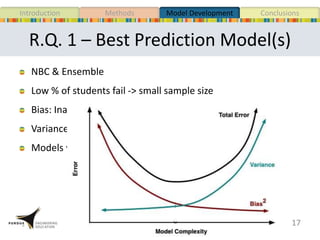
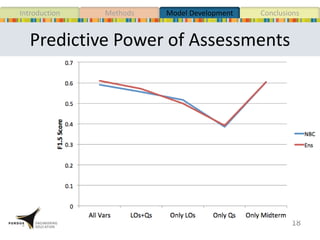
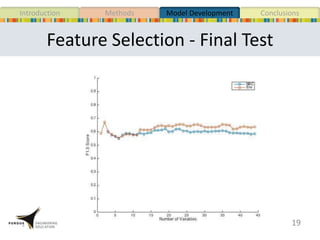
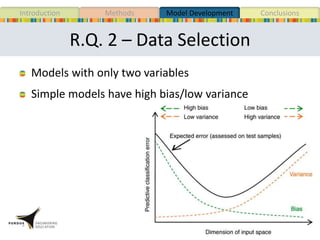
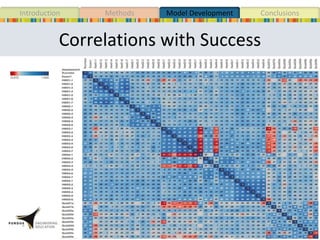
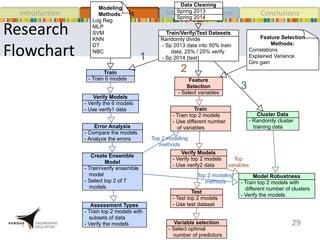
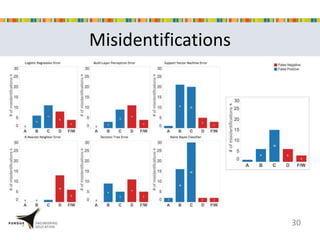
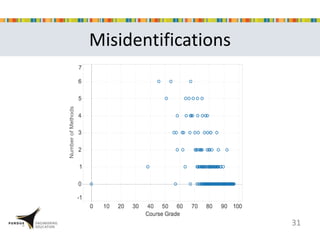
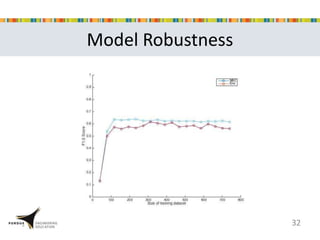
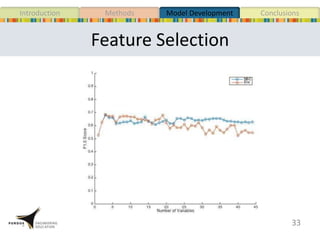
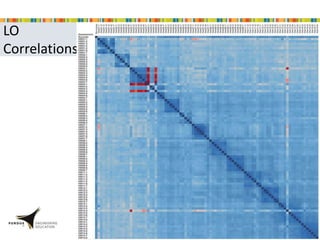
This document presents a study that developed predictive models to identify at-risk students in a first-year engineering course based on learning objective performance data. The study tested six predictive modeling methods and an ensemble method on student data from two semesters. The naive Bayes classifier and ensemble method were most successful at prediction. Feature selection revealed the midterm exam and performance in week 5 had the strongest relationship to student success. The models can help instructors identify struggling students and gain insights to improve pedagogy.