Download to read offline





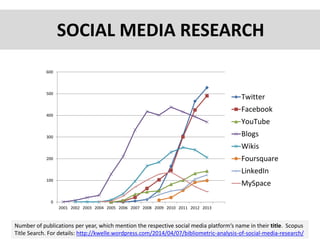















The document discusses a workshop focused on failures in social media research, aiming to collect examples of mishaps and learn from them across various research communities. Key challenges include engaging users, selecting appropriate methods for data analysis, dealing with unreliable tools, and managing the dynamic nature of social media content. The workshop emphasizes the need for best practices, improved evaluation standards, and an understanding of the complexities involved in social media research.























































































