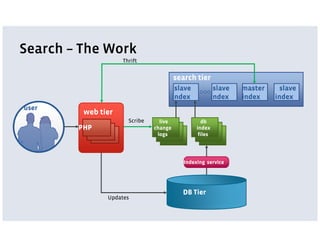
Facebook uses a LAMP stack with additional services and customizations for its architecture. The LAMP stack includes PHP, MySQL, and Memcache. PHP is used for its web programming capabilities but has scaling issues. MySQL is used primarily as a key-value store and is optimized for recency of data. Memcache provides high-performance caching. Additional services are created using Thrift for tasks better suited to other languages. Services include News Feed, Search, and logging via Scribe. The architecture emphasizes scalability, simplicity, and optimizing for common use cases.