













![22KSQL- Streaming SQL for Apache Kafka
WINDOWing
● Not ANSI SQL ! à Continuous Queries
• TUMBLING
• SELECT appname, ip, COUNT(appname) AS problem_count FROM
logstream WINDOW TUMBLING (size 1 minute) WHERE loglevel='ERROR'
GROUP BY appname, ip;
• HOPPING
• SELECT itemid, SUM(arraycol[0]) FROM orders WINDOW HOPPING
(size 20 second, advance by 5 second) GROUP BY itemid;
• SESSION
• SELECT itemid, SUM(sales_price) FROM orders WINDOW SESSION
(20 second) GROUP BY itemid;](https://image.slidesharecdn.com/201811bigdataspainksqlintrokaiwaehner-181115051910/85/KSQL-The-Open-Source-SQL-Streaming-Engine-for-Apache-Kafka-Big-Data-Spain-2018-22-320.jpg)




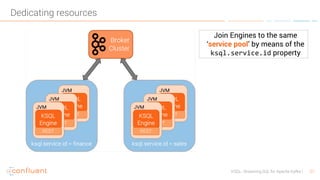


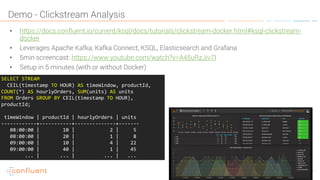



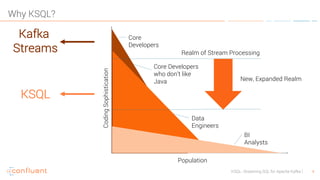
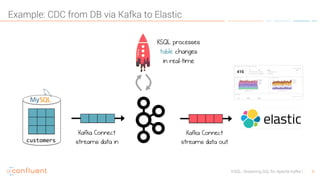
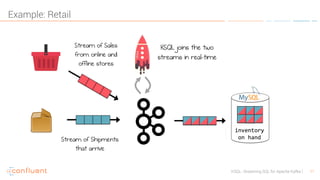
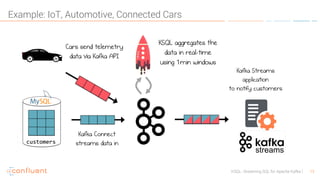
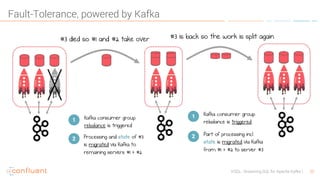
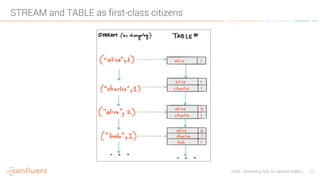
KSQL is an open-source streaming SQL engine designed for Apache Kafka, enabling real-time data processing and analysis without requiring source code. It facilitates data exploration, transformation, real-time ETL, monitoring, and anomaly detection through user-friendly SQL-like queries. KSQL's architecture consists of an engine, a REST server interface, and a command-line interface, making it suitable for various applications from development to production environments.










































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)












