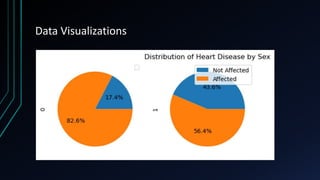
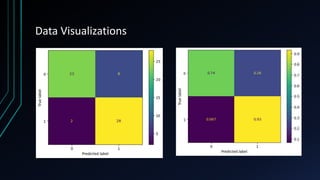
The project focuses on an in-depth analysis of cardiovascular health using exploratory data analysis (EDA) and machine learning, utilizing the 'heart disease UCI' dataset to understand relationships between health parameters and cardiovascular disease risk. Key steps in the analysis include data preprocessing, model training, and correlation analysis, which reveal significant insights and patterns pertinent to heart disease prediction. The findings underscore the importance of thorough data exploration, visualization, and predictive modeling in enhancing early detection and personalized interventions for cardiovascular health.





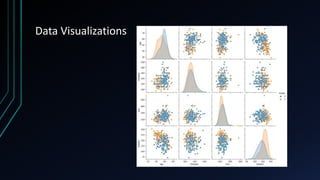

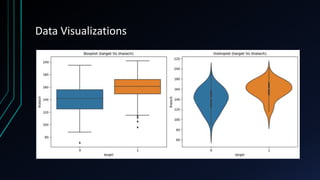
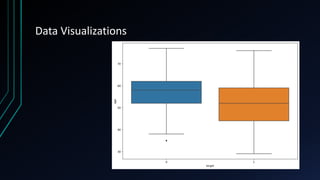
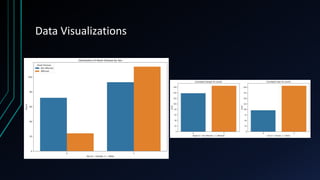
![Data Analysis
• Correlation analysis is a statistical technique used to measure the strength and direction of the relationship between two quantitative variables. It
helps in understanding how changes in one variable are associated with changes in another variable. Correlation coefficients range from -1 to 1,
where:
• - A correlation coefficient close to 1 indicates a strong positive relationship, meaning that as one variable increases, the other variable also tends
to increase.
• - A correlation coefficient close to -1 indicates a strong negative relationship, meaning that as one variable increases, the other variable tends to
decrease.
• - A correlation coefficient close to 0 indicates a weak or no relationship between the variables.
• Now, let's display a correlation matrix heatmap to visualize the correlations between variables:
• In the correlation matrix heatmap, variables are displayed on both the x-axis and the y-axis, and the cells represent the correlation coefficients
between pairs of variables. The colors of the cells indicate the strength and direction of the correlation: warmer colors (e.g., red) represent
positive correlations, while cooler colors (e.g., blue) represent negative correlations.
• Upon analyzing the correlation findings, several variables exhibit strong correlations. For example, [highlight variables with strong positive
correlations, e.g., "thalach" (maximum heart rate achieved) and "target" (presence of heart disease), with a correlation coefficient of 0.42]. This
indicates that as the maximum heart rate achieved increases, the likelihood of heart disease presence also tends to increase.
• Similarly, [highlight variables with strong negative correlations, e.g., "age" and "thalach", with a correlation coefficient of -0.42]. This suggests that
as age increases, the maximum heart rate achieved tends to decrease.
• Understanding these strong correlations is essential for identifying potential predictors or risk factors associated with the target variable
(presence of heart disease) and can guide further analysis and modeling efforts.](https://image.slidesharecdn.com/exploratorydataanalysisandmachinelearning-240505031249-f9049ca8/85/Exploratory-Data-Analysis-and-Machine-Learning-pptx-12-320.jpg)


































![PPT-HEART-DISEASE[1].pptx presentationss](https://cdn.slidesharecdn.com/ss_thumbnails/ppt-heart-disease1-250901140846-bb7a7155-thumbnail.jpg?width=640&height=640&fit=bounds)











































