Download as PDF, PPTX

















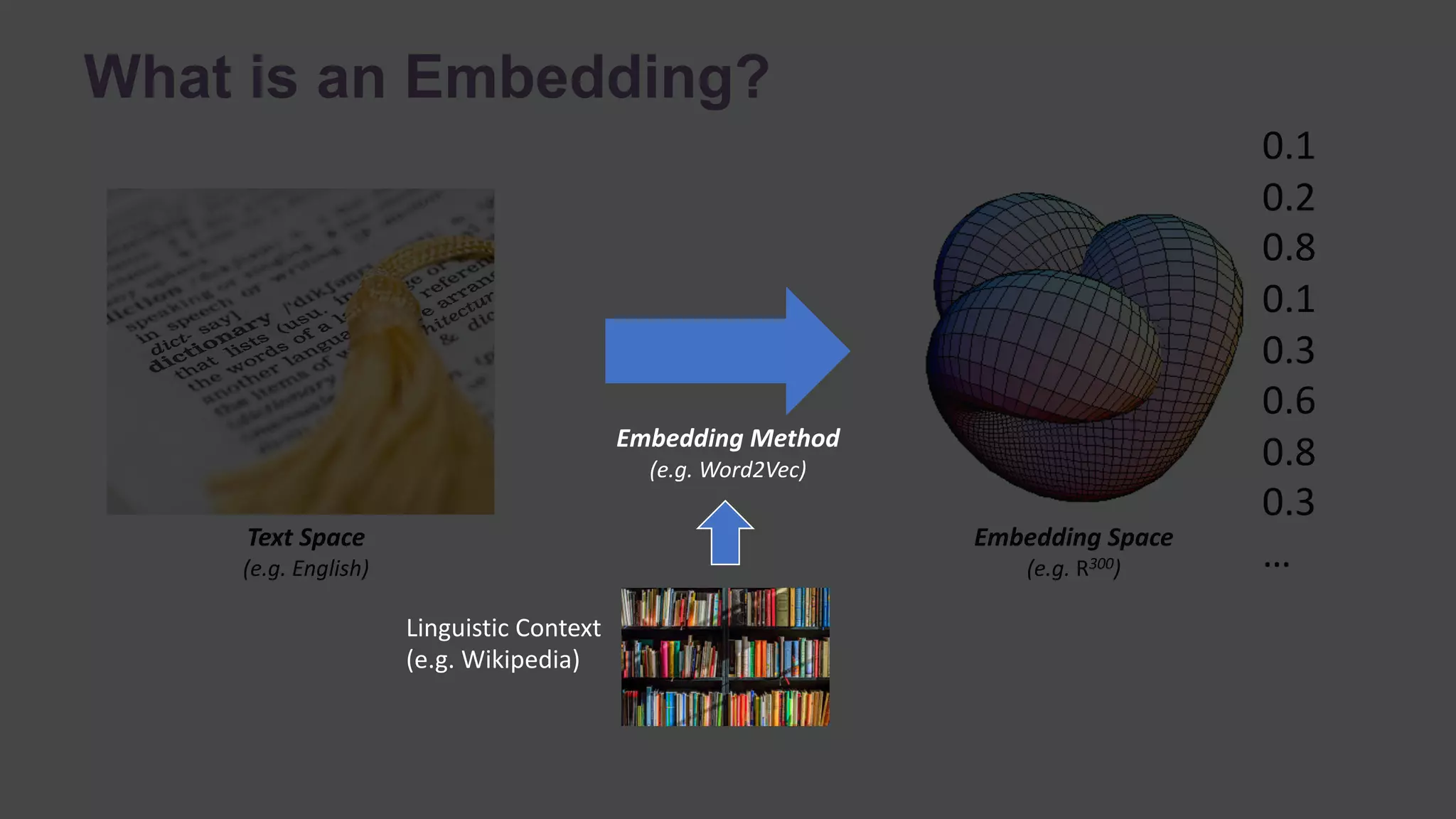


![“Word” Embeddings
Token Value
“great” [0.1, 0.3, …]
… …
Examples In Practice
• Word2vec
• GloVe
• fastText](https://image.slidesharecdn.com/transferlearningwebinar-181011131654/75/Small-Data-for-Big-Problems-Practical-Transfer-Learning-for-NLP-22-2048.jpg)
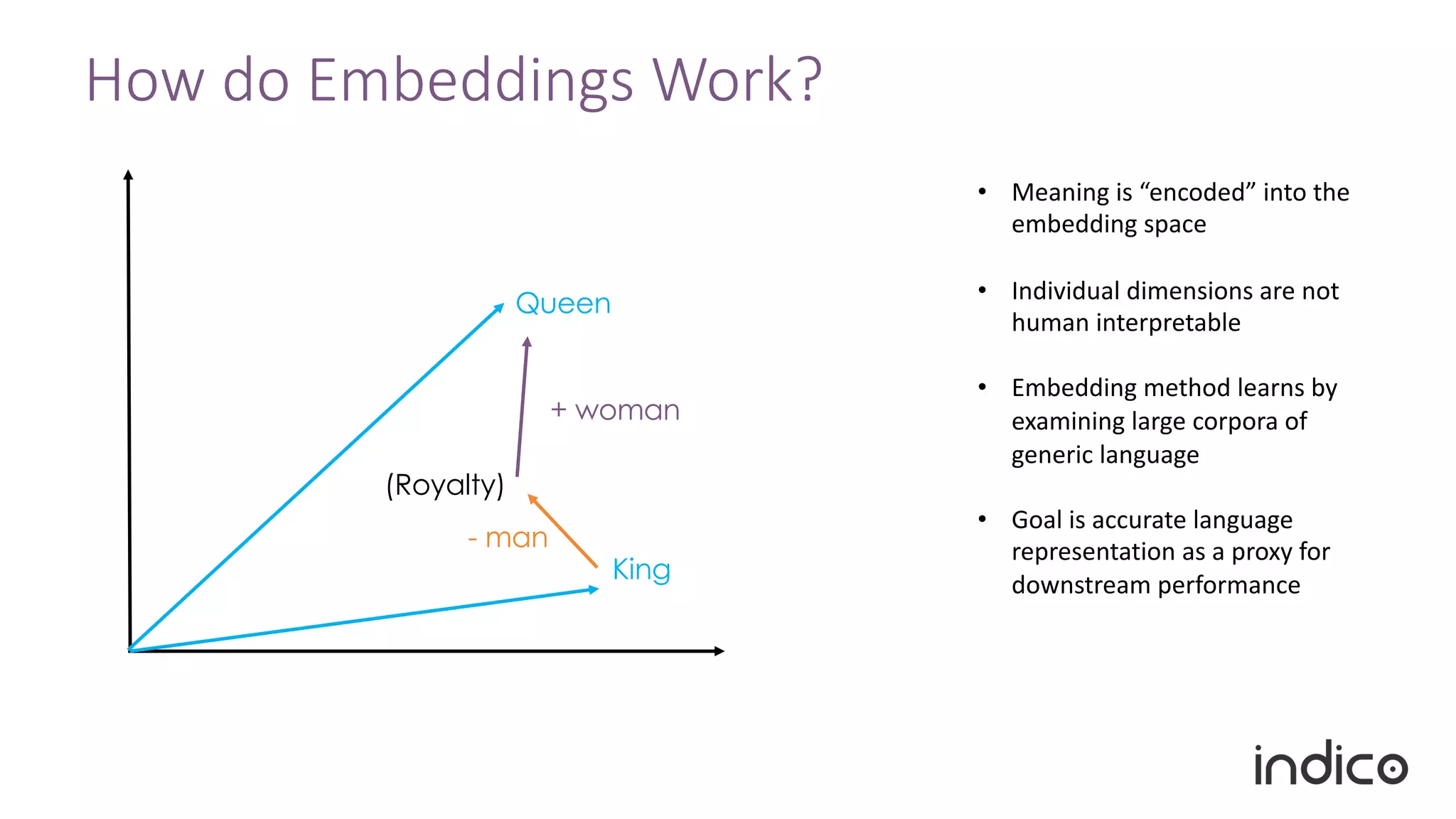
![“Word” Embeddings
Token Value
“great” [0.1, 0.3, …]
… …
Examples In Practice
Training
The quick brown fox _____ over the lazy dog
___ ___ ____ ___ jumps ___ __ ___ ___
CBOW
Skip Gram
• Word2vec
• GloVe
• fastText](https://image.slidesharecdn.com/transferlearningwebinar-181011131654/75/Small-Data-for-Big-Problems-Practical-Transfer-Learning-for-NLP-23-2048.jpg)
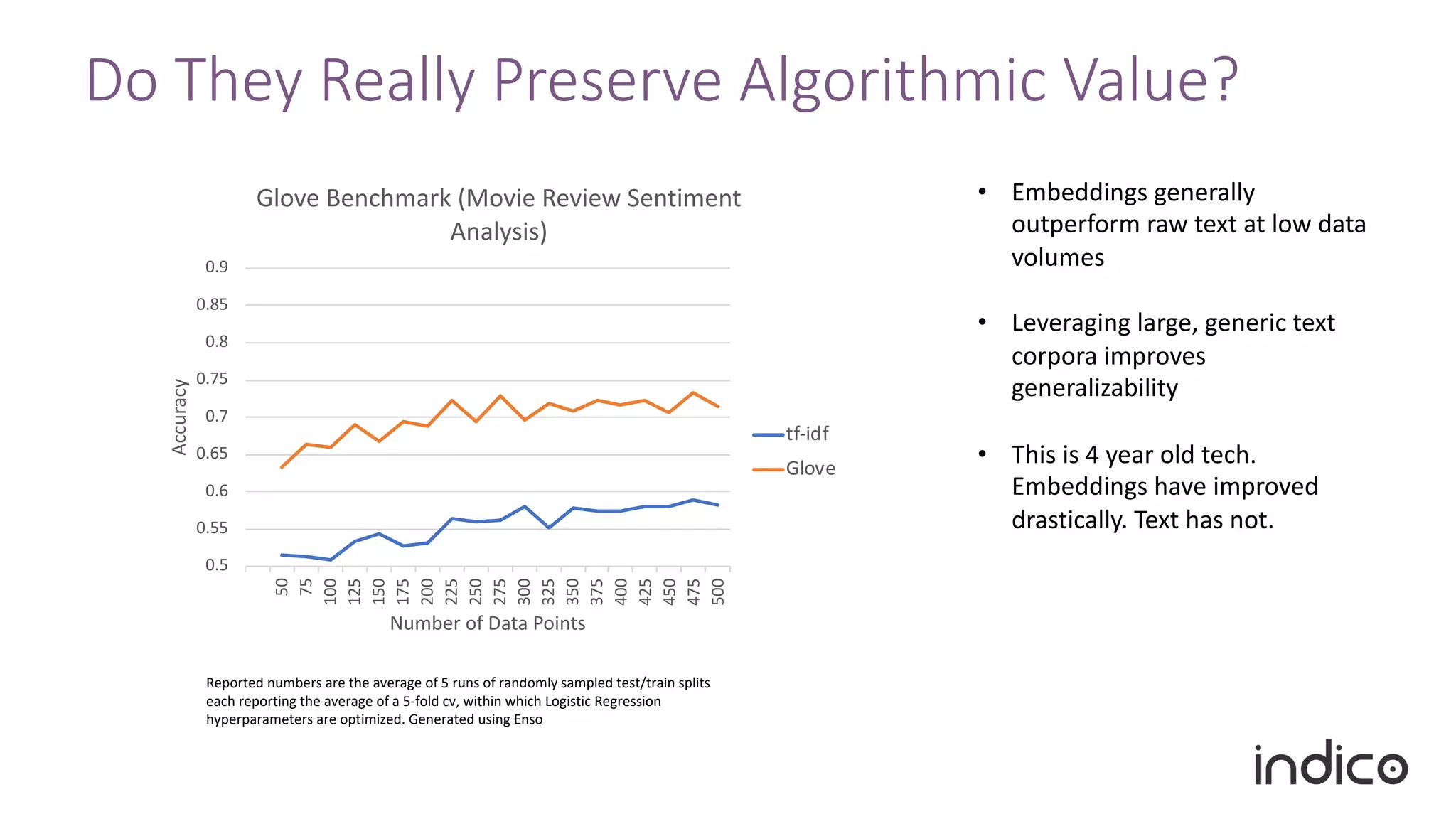




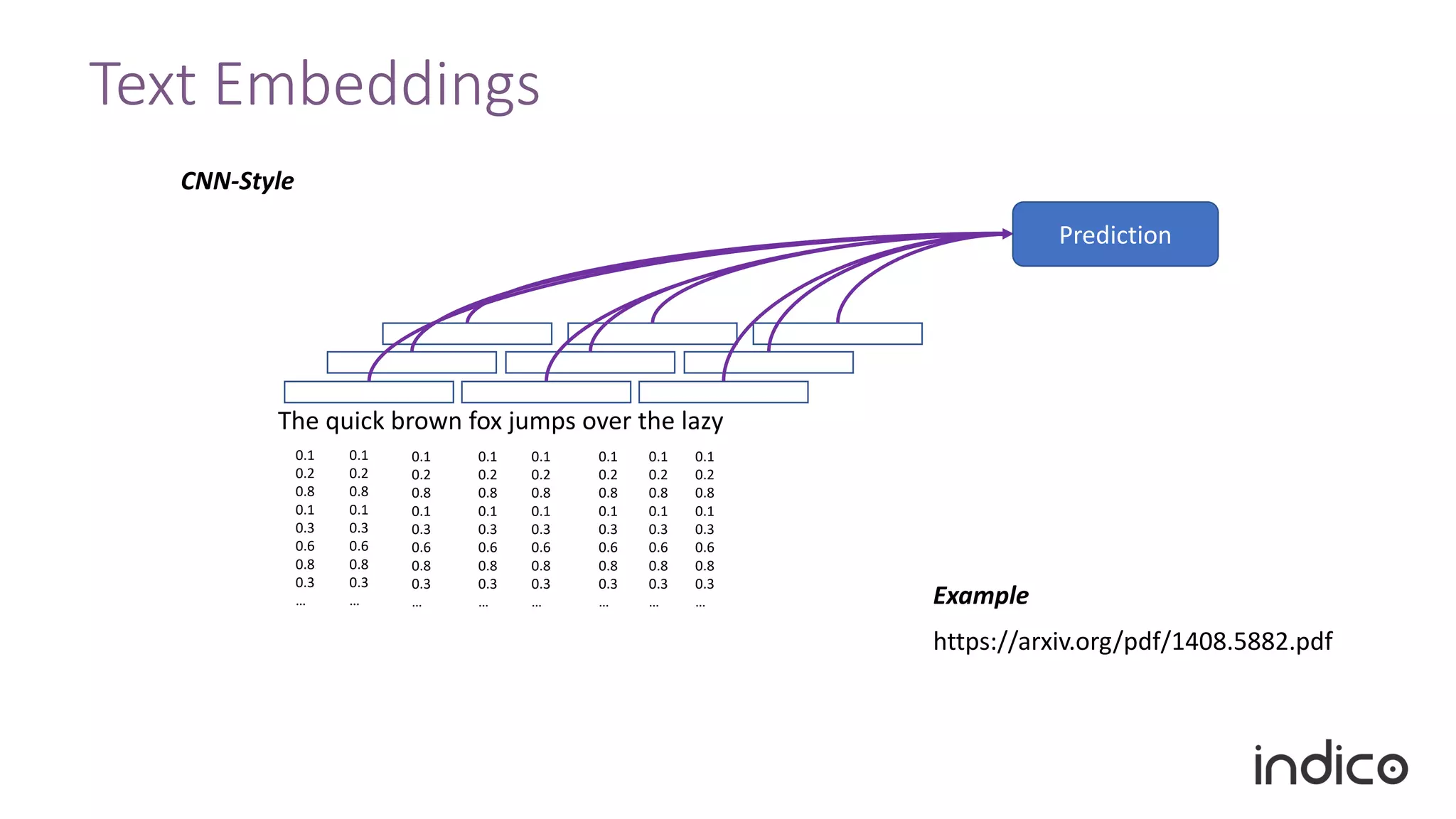
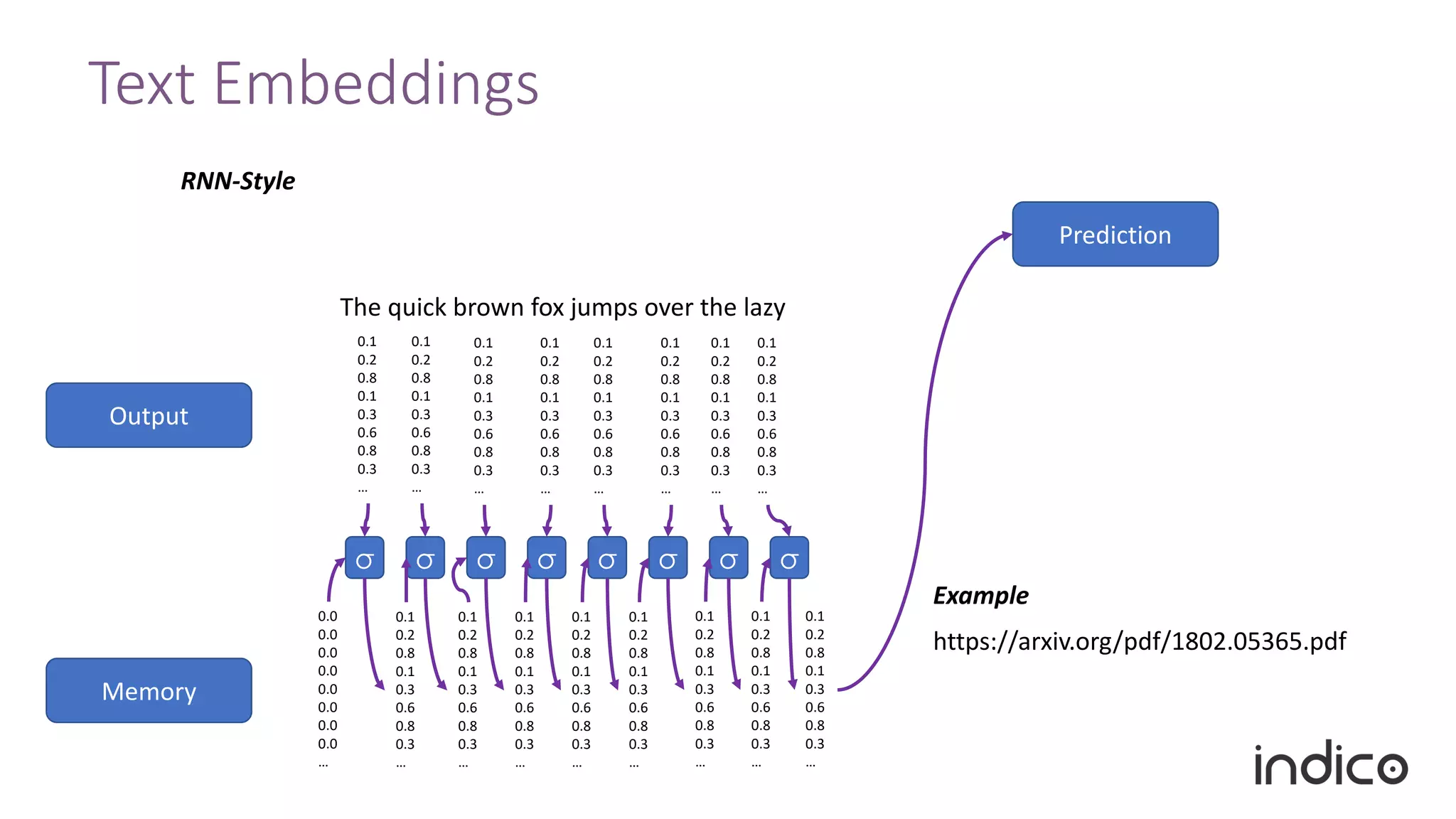



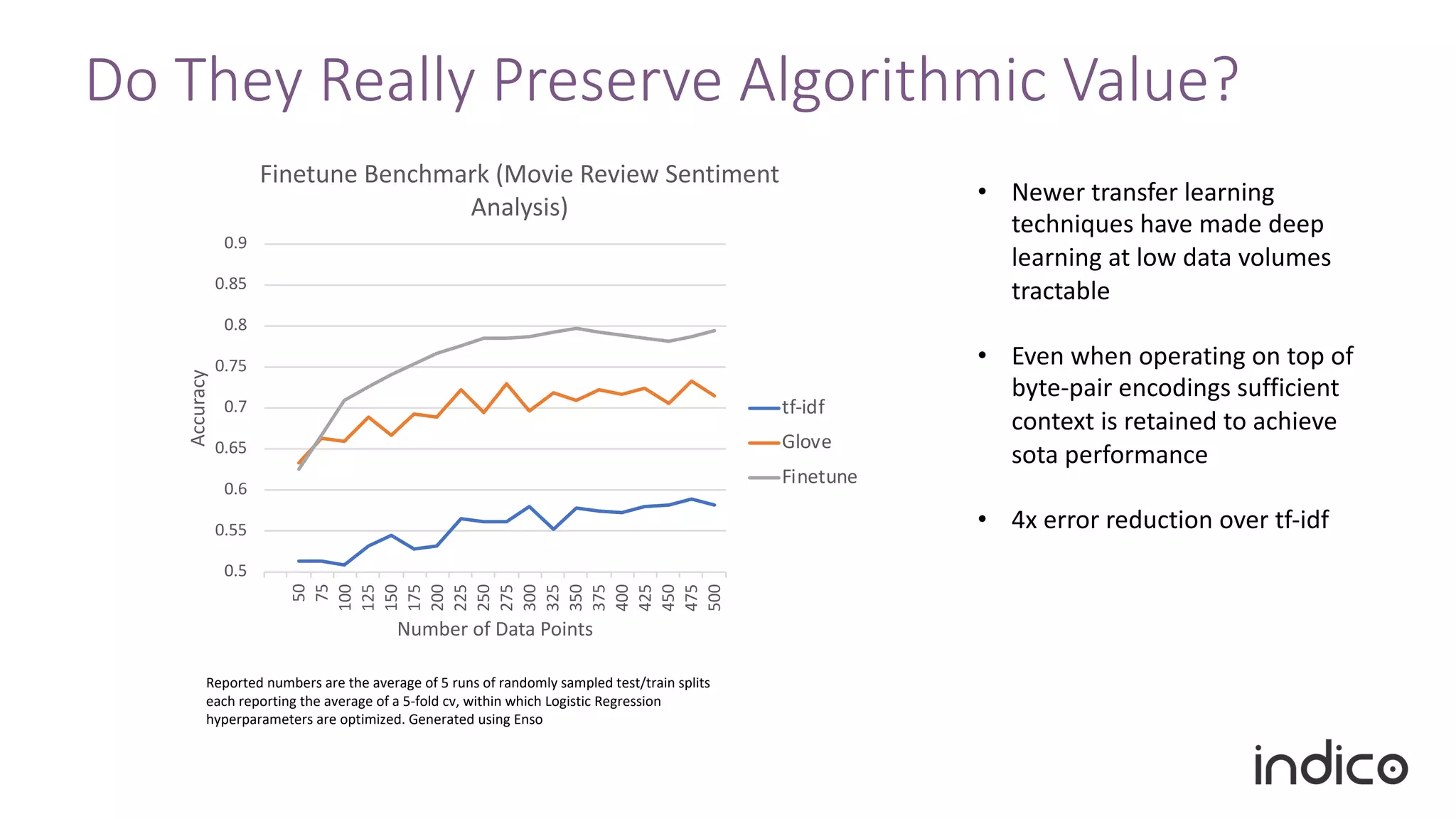


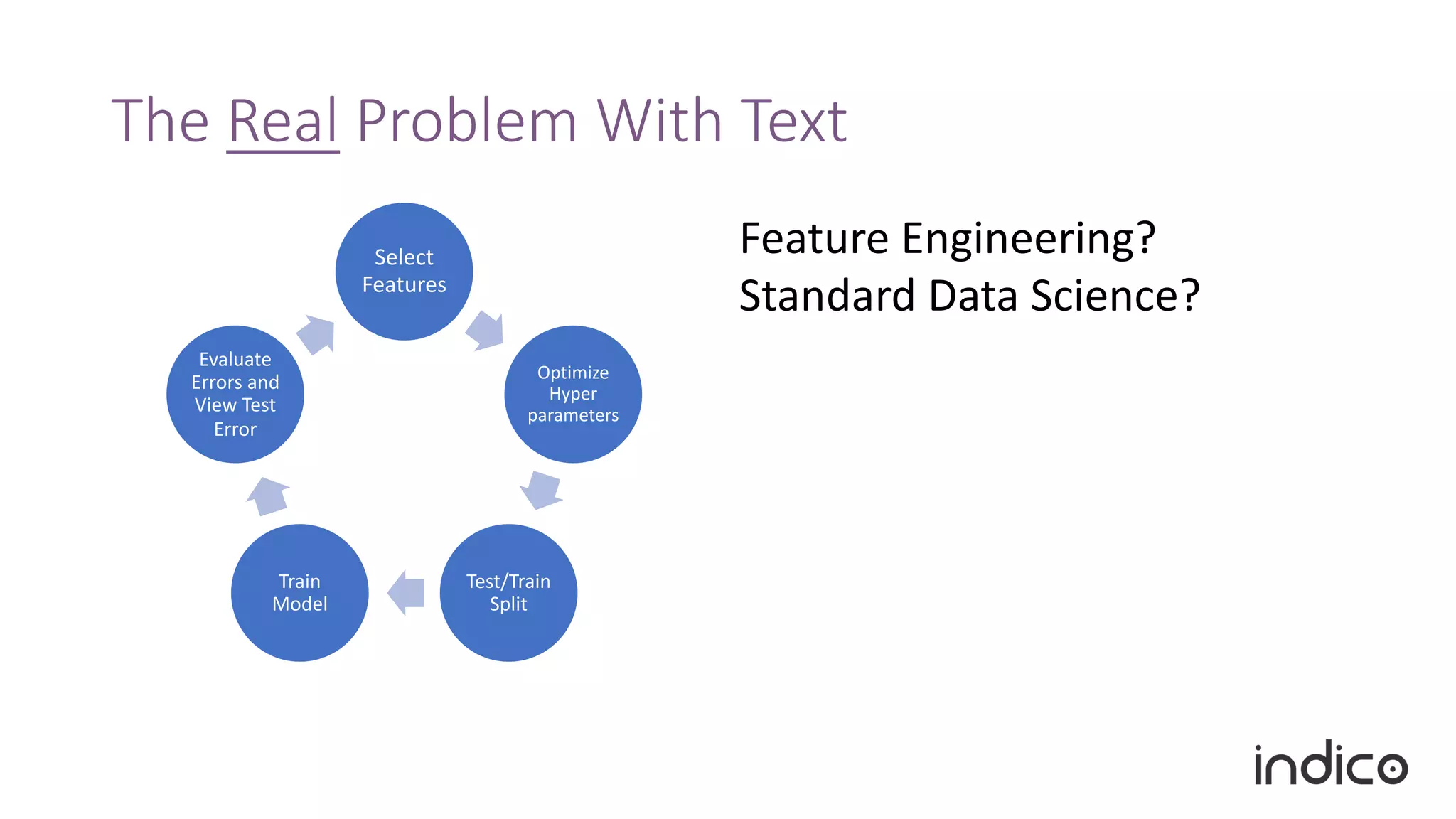
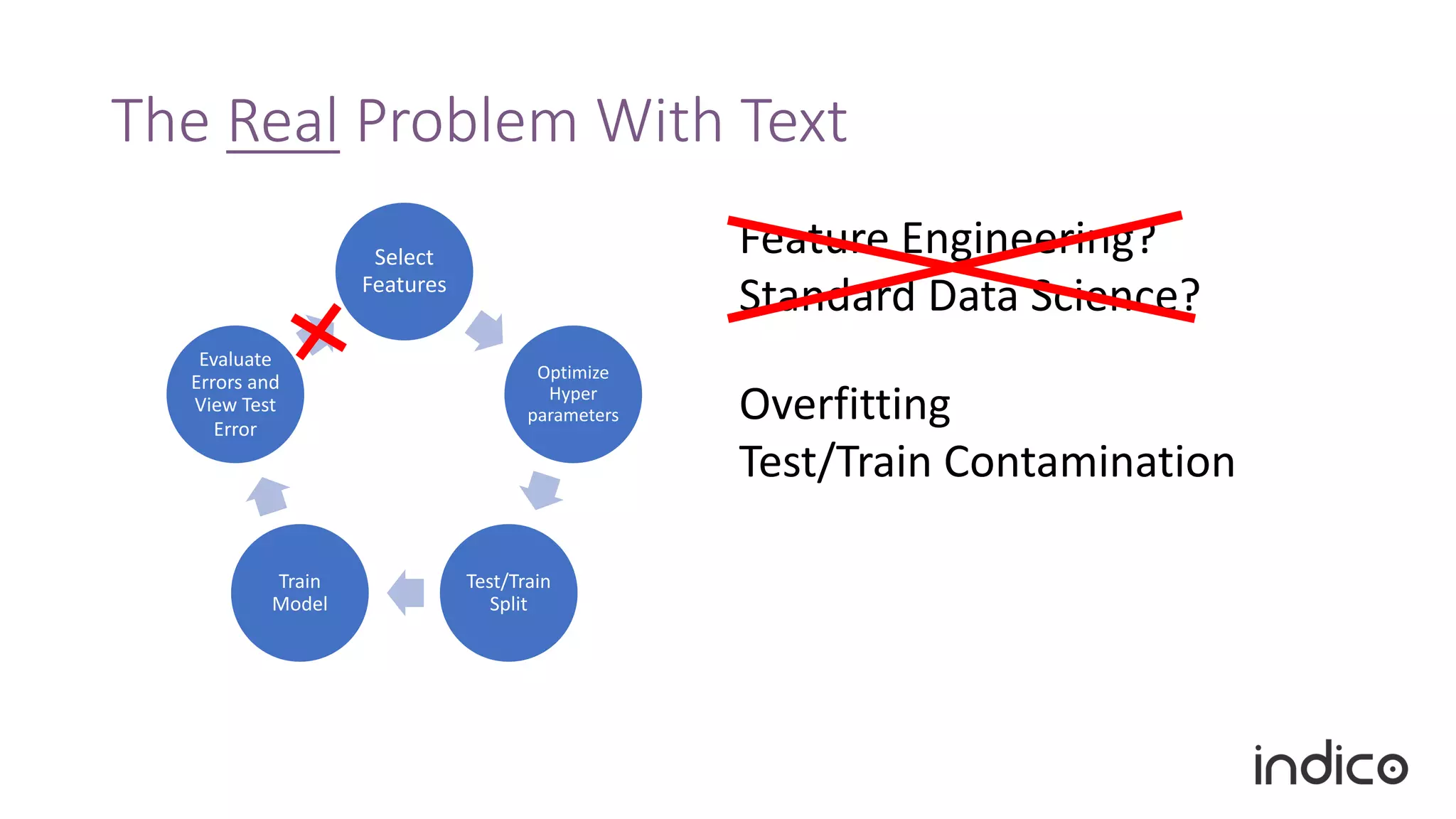
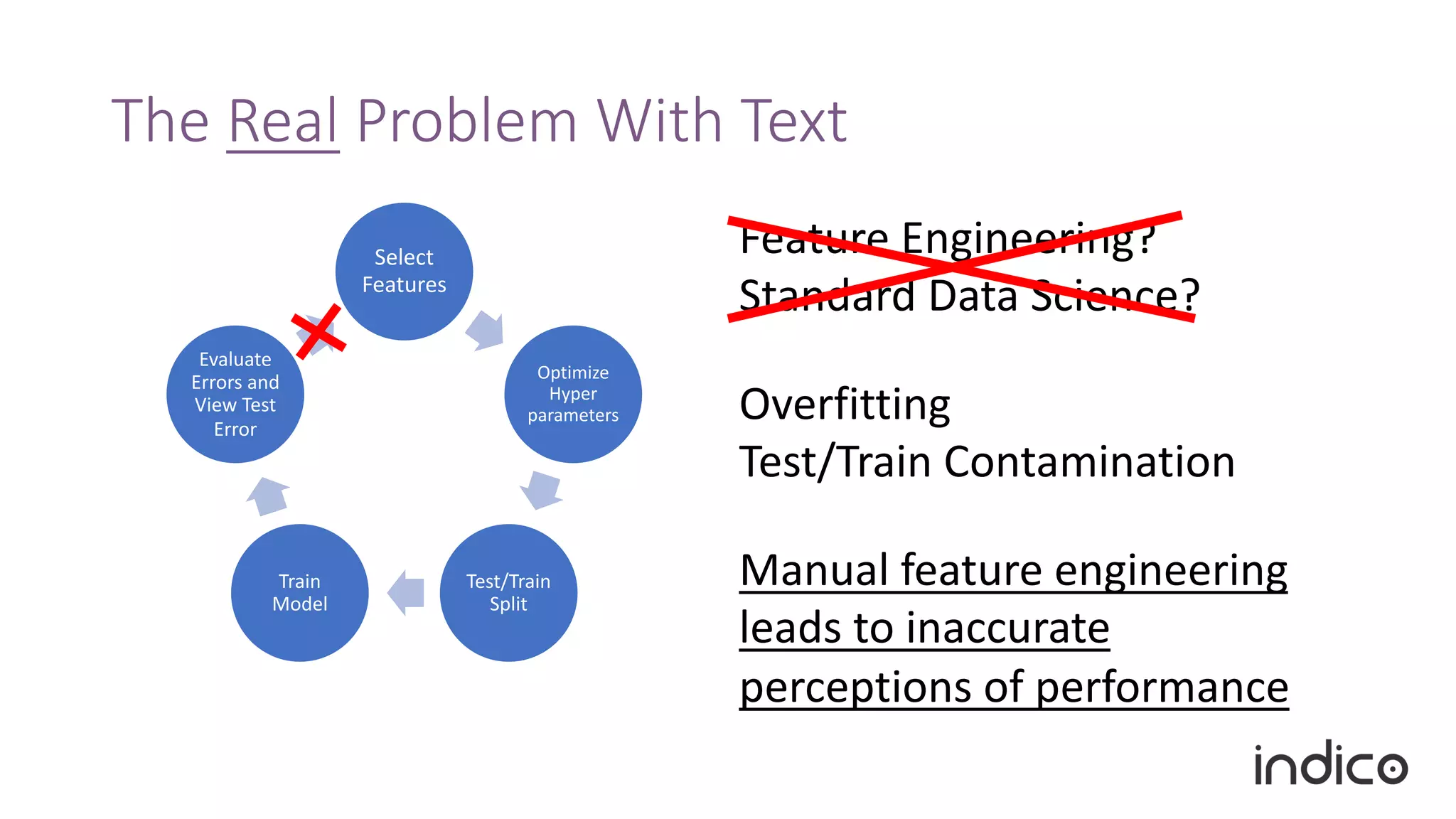

The document discusses the limitations of traditional natural language processing (NLP) techniques and emphasizes the advantages of transfer learning through embeddings for improving performance, especially with small data sets. It details how embeddings like word2vec and GloVe outperform raw text approaches and outlines practical applications and challenges in the field. Additionally, it highlights the importance of context in enhancing linguistic understanding and addresses issues related to feature engineering in NLP.


























![[246]QANet: Towards Efficient and Human-Level Reading Comprehension on SQuAD](https://cdn.slidesharecdn.com/ss_thumbnails/246qanetdeview2018-181012000849-thumbnail.jpg?width=640&height=640&fit=bounds)








![Getting started with indico APIs [Python]](https://cdn.slidesharecdn.com/ss_thumbnails/papisconference-141204130351-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)




















