Download to read offline

![SentiRuEval 2014-2015
Aspect-oriented
analysis of reviews
• Restaurants
• Cars
Entity-Oriented analysis
of tweets: reputation
monitoring
• Banks [8]
• Telecom companies [7]
Testing of sentiment analysis systems
of Russian texts](https://image.slidesharecdn.com/tsdrubtsova-150916124337-lva1-app6892/85/Entity-oriented-sentiment-analysis-of-tweets-results-and-problems-3-320.jpg)



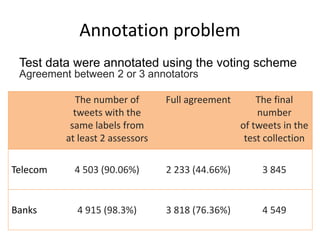
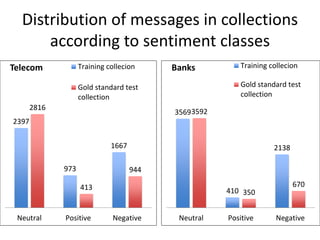
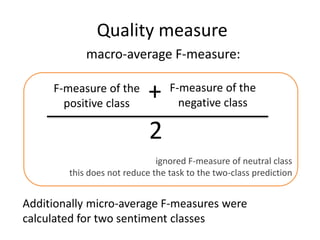
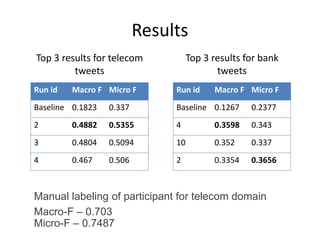

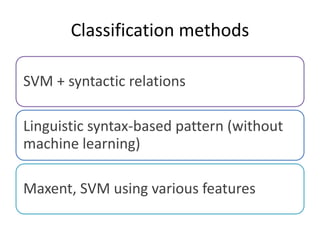








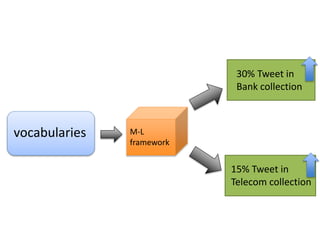
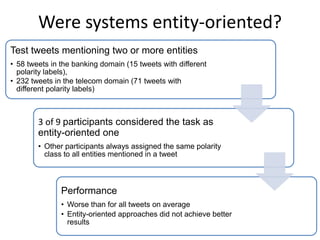



This document summarizes the results and problems of entity-oriented sentiment analysis of tweets in the SentiRuEval 2014-2015 evaluation. It describes the task of determining sentiment towards mentioned companies in tweets. The best performing systems achieved macro F-measures of 0.488 for telecom tweets and 0.36 for bank tweets. Performance varied between domains due to differences in training and test data. Many tweets were difficult to classify, either due to new events or vocabulary not covered in training, complex tweets mentioning multiple entities with different polarities, or irony. While most systems treated sentiment classification as a general task, true entity-oriented approaches did not achieve better results. Improving sentiment vocabularies and handling current events were seen as opportunities

















































![Aspect extraction using conditional random fields [SentiRuEval]](https://cdn.slidesharecdn.com/ss_thumbnails/dialogue-d-150602093500-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)


































