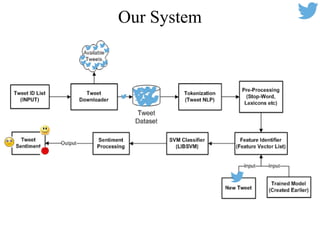
This document summarizes work on sentiment analysis for Twitter data. It outlines the challenges of analyzing tweets, which are informal and use slang. The described system downloads tweets, preprocesses them by handling emojis, hashtags, mentions and acronyms. It then extracts unigram and bigram features along with sentiment scores of words and emojis. A support vector machine classifier is trained on these features to predict sentiment. Testing showed the feature-based model with bigrams and lexicon features improved over a baseline model, achieving an F1 score of 61.17% for sentence-level sentiment classification.