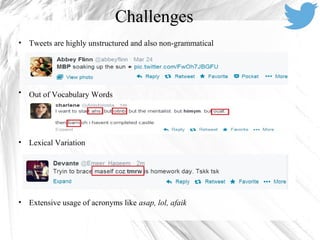
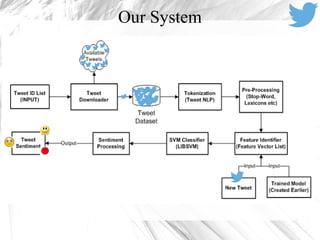
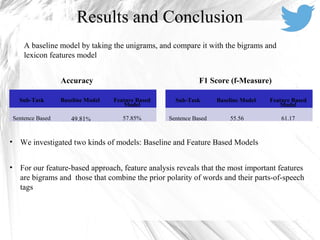
This document discusses sentiment analysis on Twitter data using machine learning techniques. It begins with introducing sentiment analysis and its goals for Twitter data. It then discusses preprocessing tweets which includes removing URLs and mentions, expanding acronyms, and assigning sentiment scores to emoticons. Features like unigrams, bigrams, word polarity scores and counts are extracted for training an SVM classifier. Evaluating on a sentence-level task, the feature-based model achieves 57.85% accuracy and 61.17% F1 score, outperforming the baseline model. Tools used include Python, Java, LIBSVM, NLTK and the Twitter API.