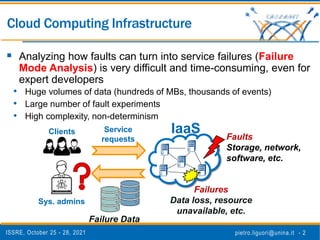
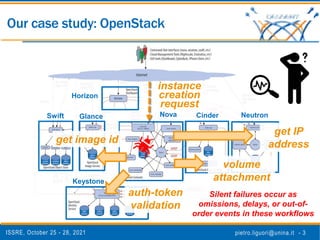
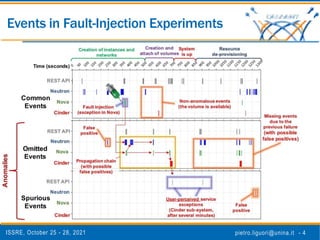
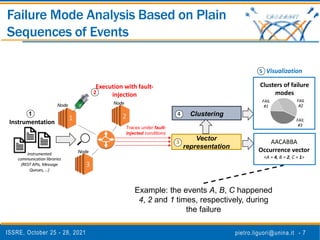
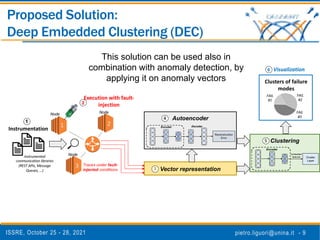
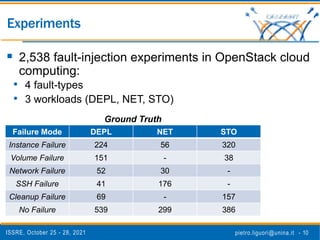
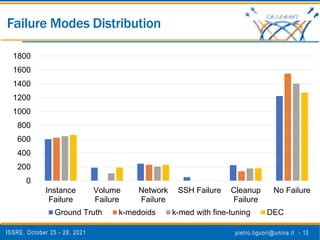
The document discusses a novel approach to analyze software failures in cloud computing systems using deep learning and fault injection, specifically focusing on OpenStack. It presents findings from 2,538 fault-injection experiments and compares the effectiveness of deep embedded clustering (DEC) with traditional clustering methods in identifying failure modes. The results indicate that DEC can achieve comparable or superior performance to manual tuning, enhancing the interpretation of failure data for developers and system administrators.