Download as PDF, PPTX





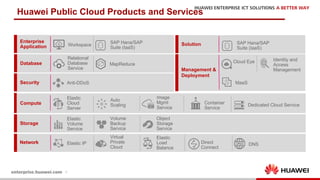
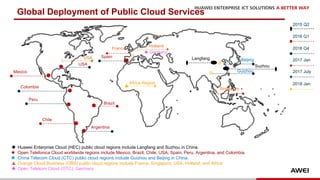

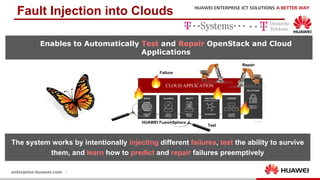
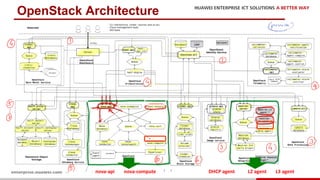
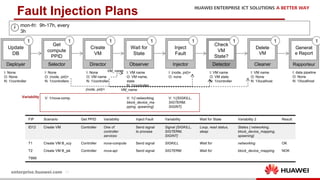


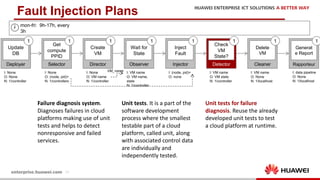



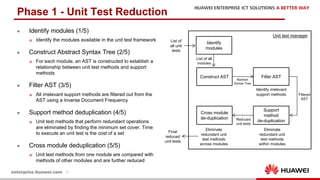
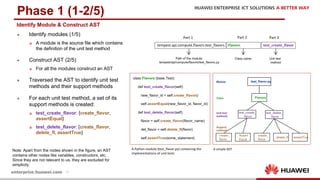
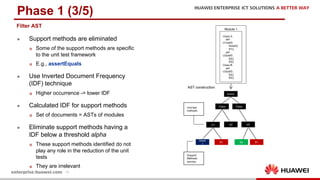
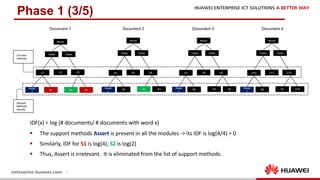




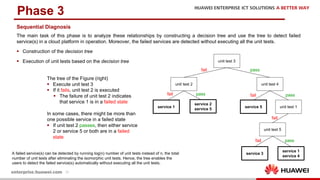




The document discusses the 9th International Workshop on Software Engineering for Resilient Systems held in Geneva, highlighting Dr. Jorge Cardoso's presentation on using fault injection to enhance cloud reliability, as demonstrated with OpenStack. It emphasizes the significance of toolsets like Netflix's Chaos Monkey for testing cloud applications and proposes a method to efficiently diagnose failures by reducing unit tests and establishing service relationships. The approach aims to diagnose failures using only 4-5% of the original unit tests, aligning with operational reliability requirements.









































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)











