Downloaded 94 times














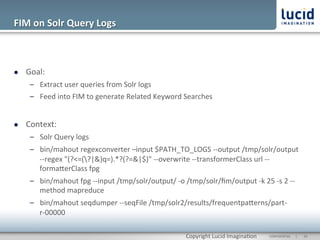
![Output
l Key:
Chris:
Value:
([Chris,
HosteOer],870),
([Chris],870),
([Search,
Faceted,
Chris,
HosteOer,
Webcast,
Power,
Mastering],18),
([Search,
Faceted,
Chris,
HosteOer,
Webcast,
Power],18),
([Search,
Faceted,
Chris,
HosteOer],18),
([Solr,
new,
Chris,
HosteOer,
webcast,
along,
sponsors,
DZone,
QA,
Refcard],
12),
([Solr,
new,
Chris,
HosteOer,
webcast,
along,
sponsors,
DZone],12),
([Solr,
new,
Chris,
HosteOer,
webcast,
along,
sponsors],12),
([Solr,
new,
Chris,
HosteOer,
webcast,
along],12),
([Solr,
new,
Chris,
HosteOer,
webcast],
12),
([Solr,
new,
Chris,
HosteOer],12)
Copyright
Lucid
Imagina@on
CONFIDENTIAL
|
25](https://image.slidesharecdn.com/enhancediscoverysolrandmahout-120123123705-phpapp02/85/Enhance-discovery-Solr-and-Mahout-25-320.jpg)
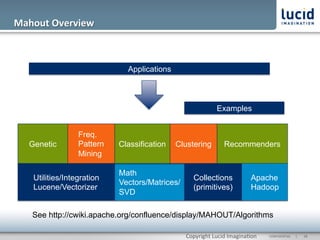

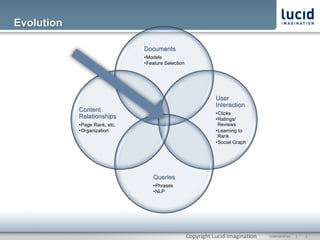
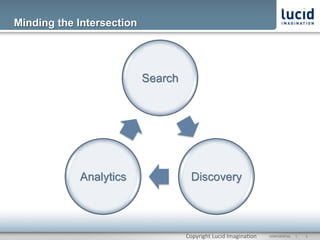
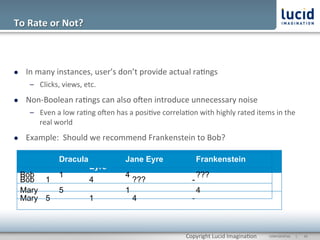
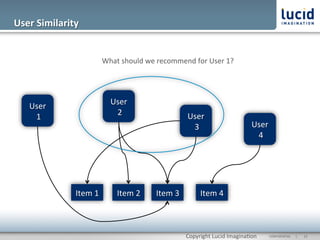
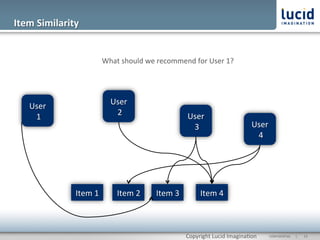
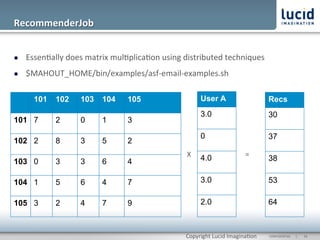
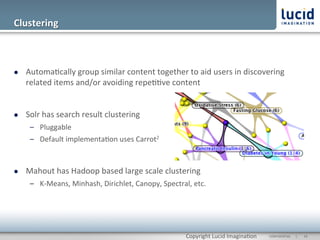
The document discusses enhancing discovery with Apache Solr, Lucene, and Mahout. It provides background on these tools, describing Solr as a search server built on Lucene, and Mahout as a machine learning library for tasks like recommendations, clustering, and classification. Specifically, it outlines how Mahout can be used for collaborative filtering to provide recommendations solely based on user preferences and similarities between items. The slope one algorithm is also described as a way to generate recommendations by assuming a linear relationship between a user's ratings.























































































