Download as PDF, PPTX



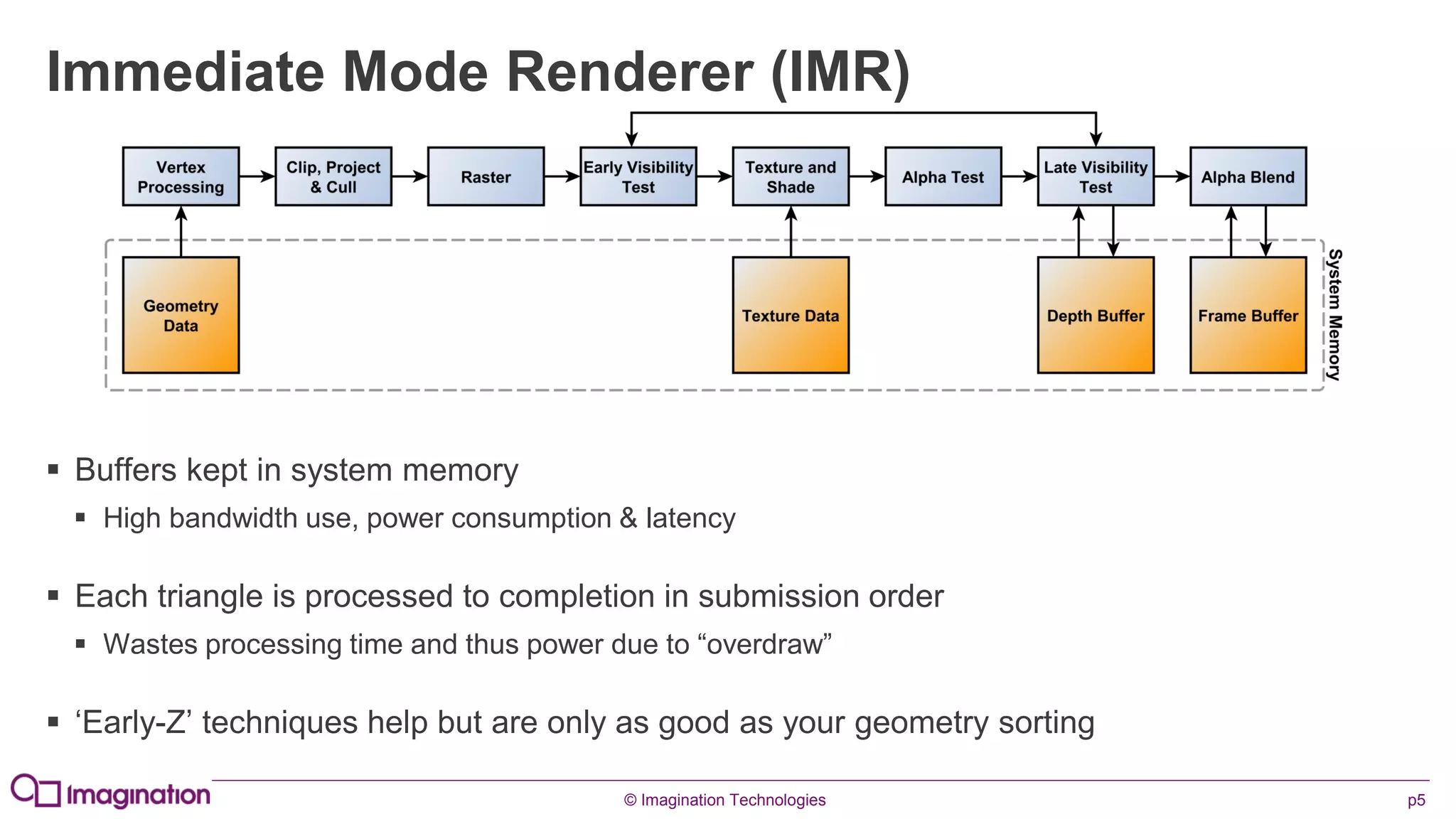

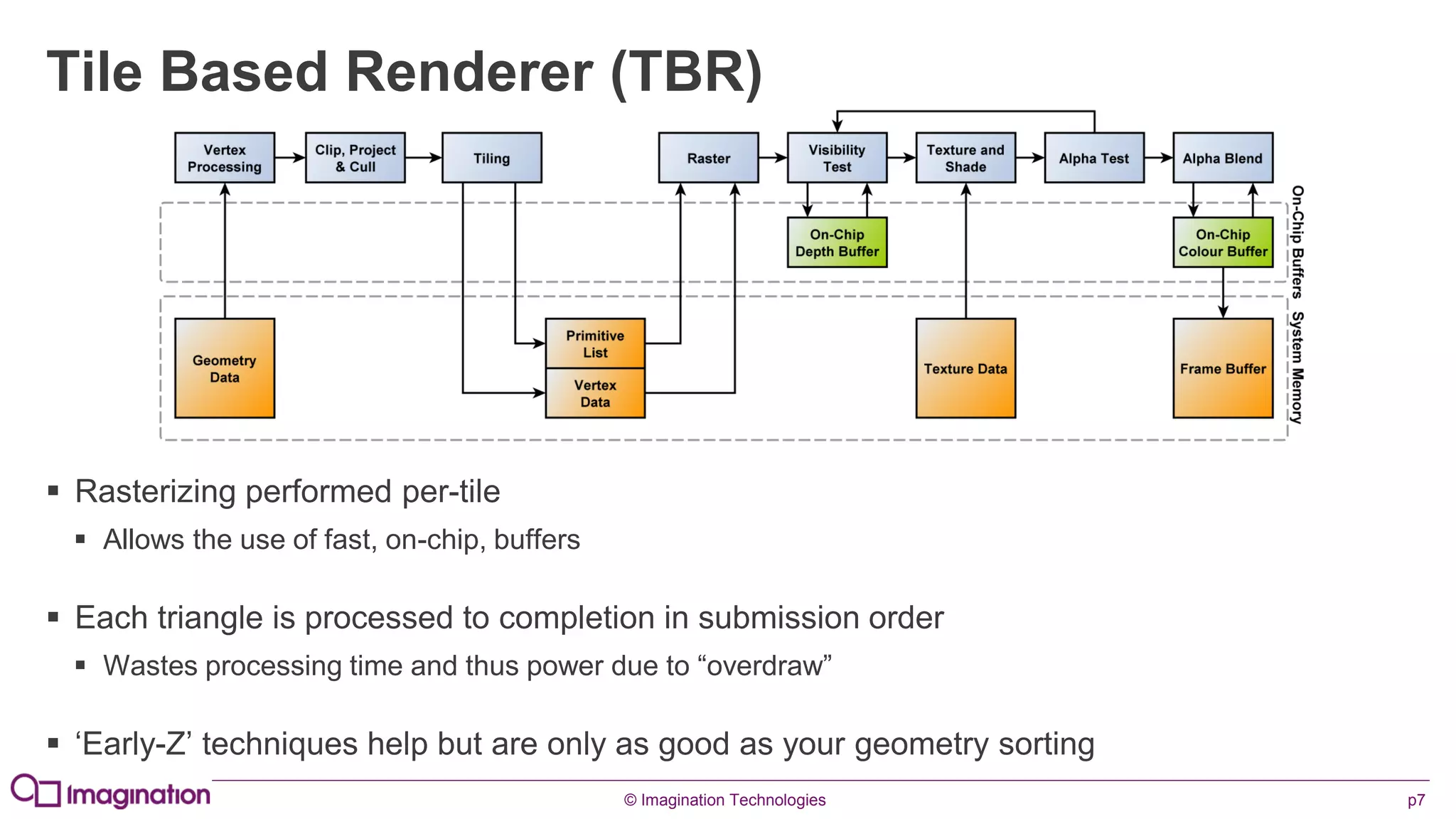
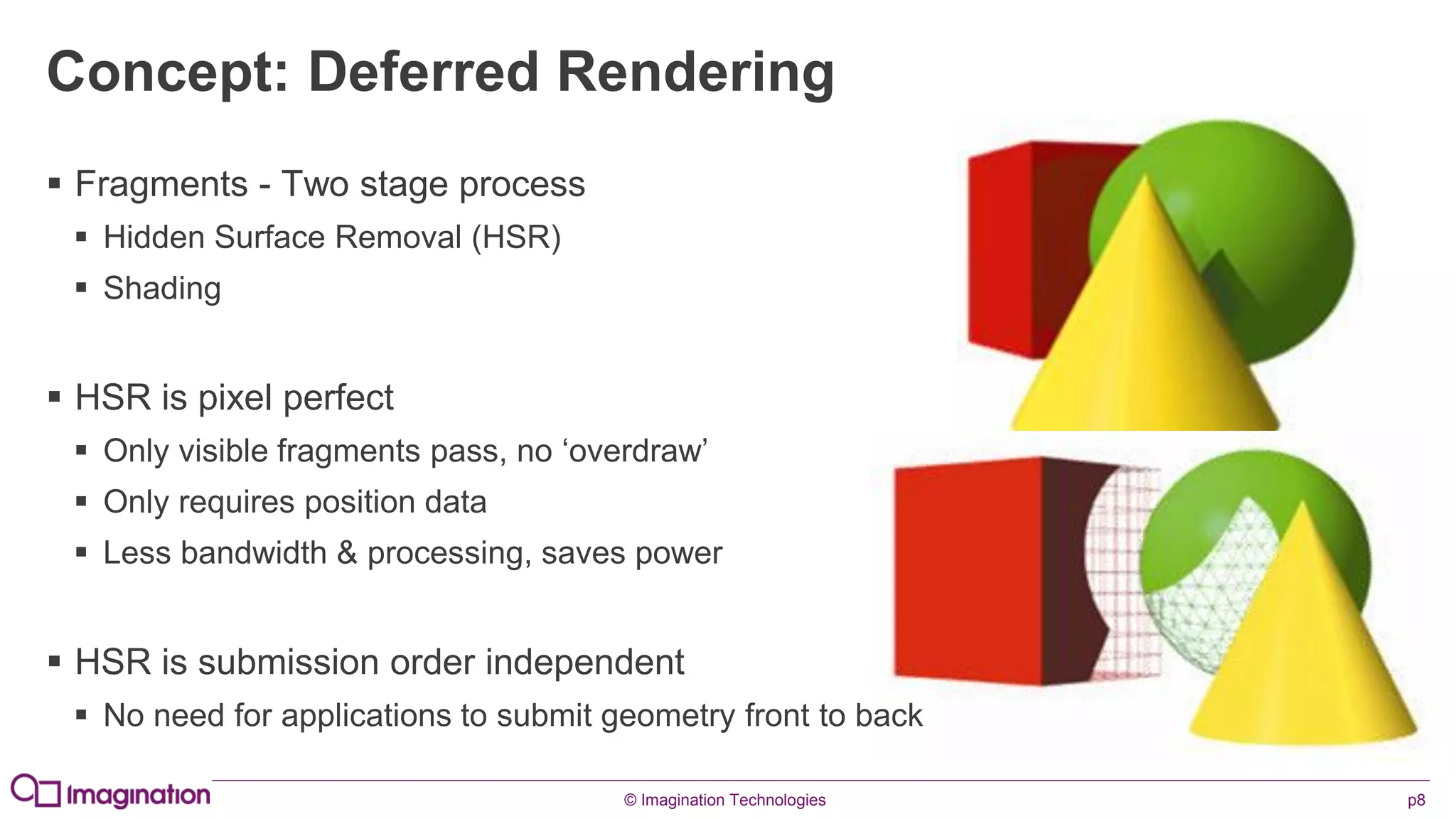
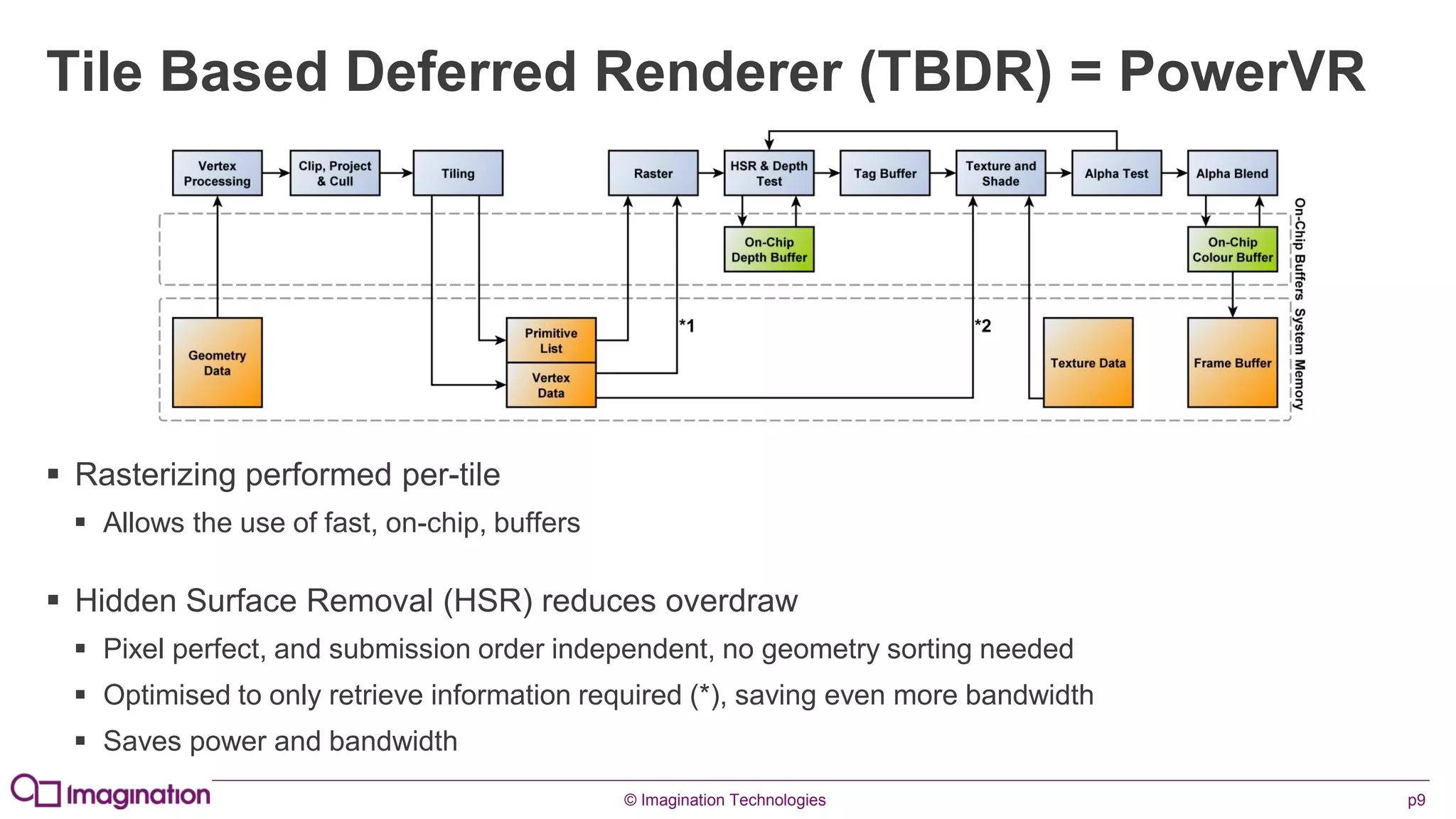

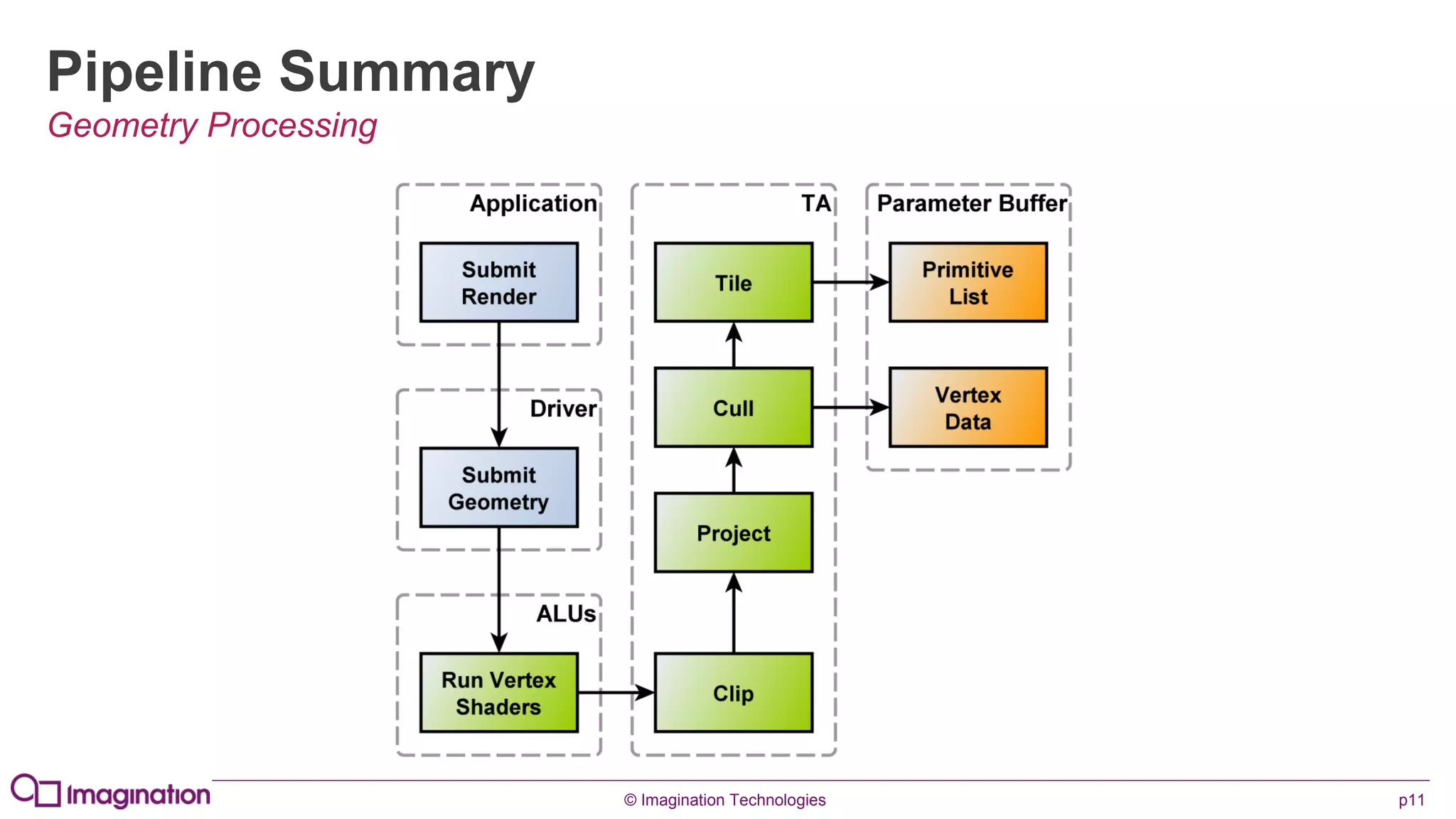
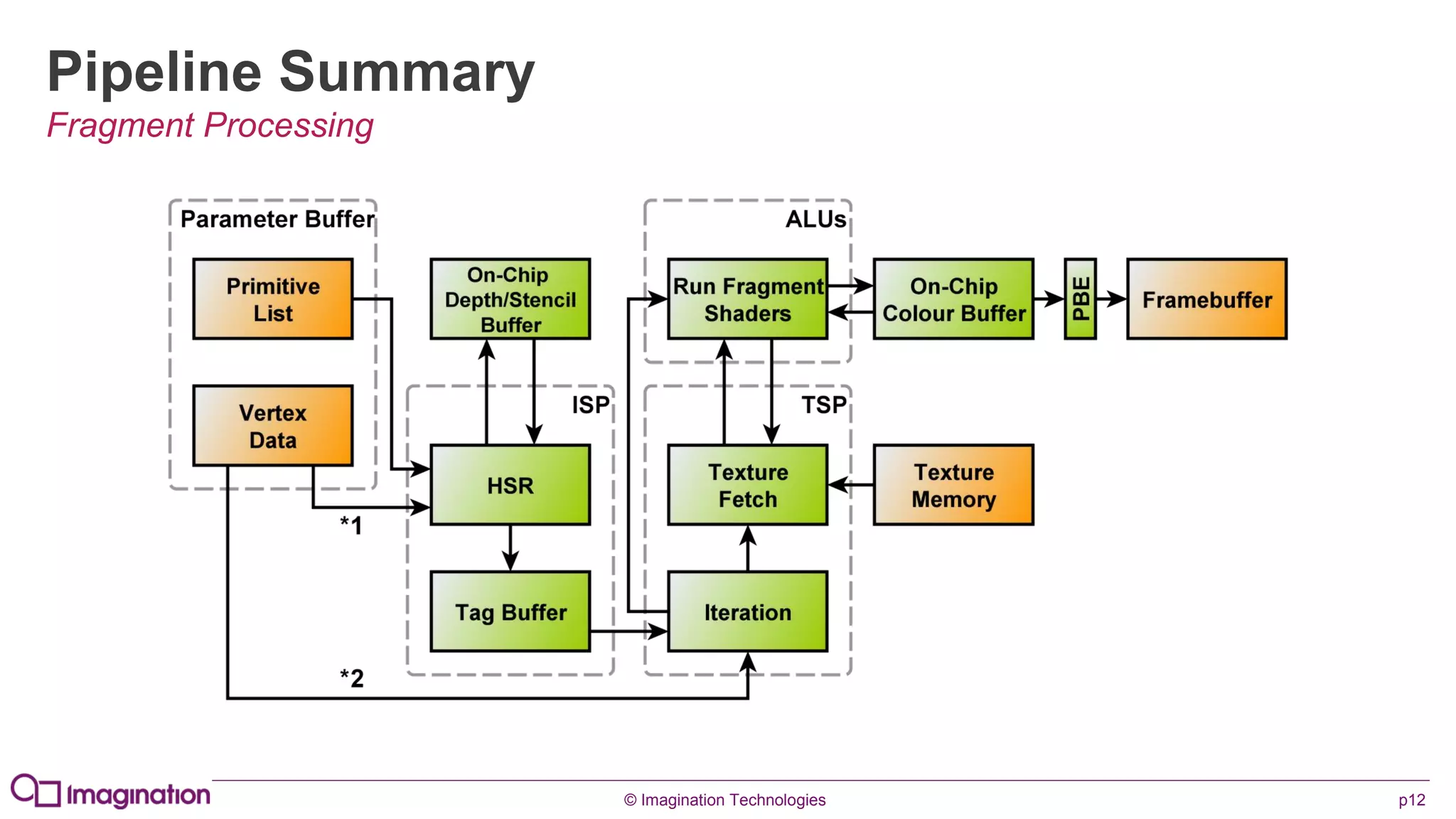
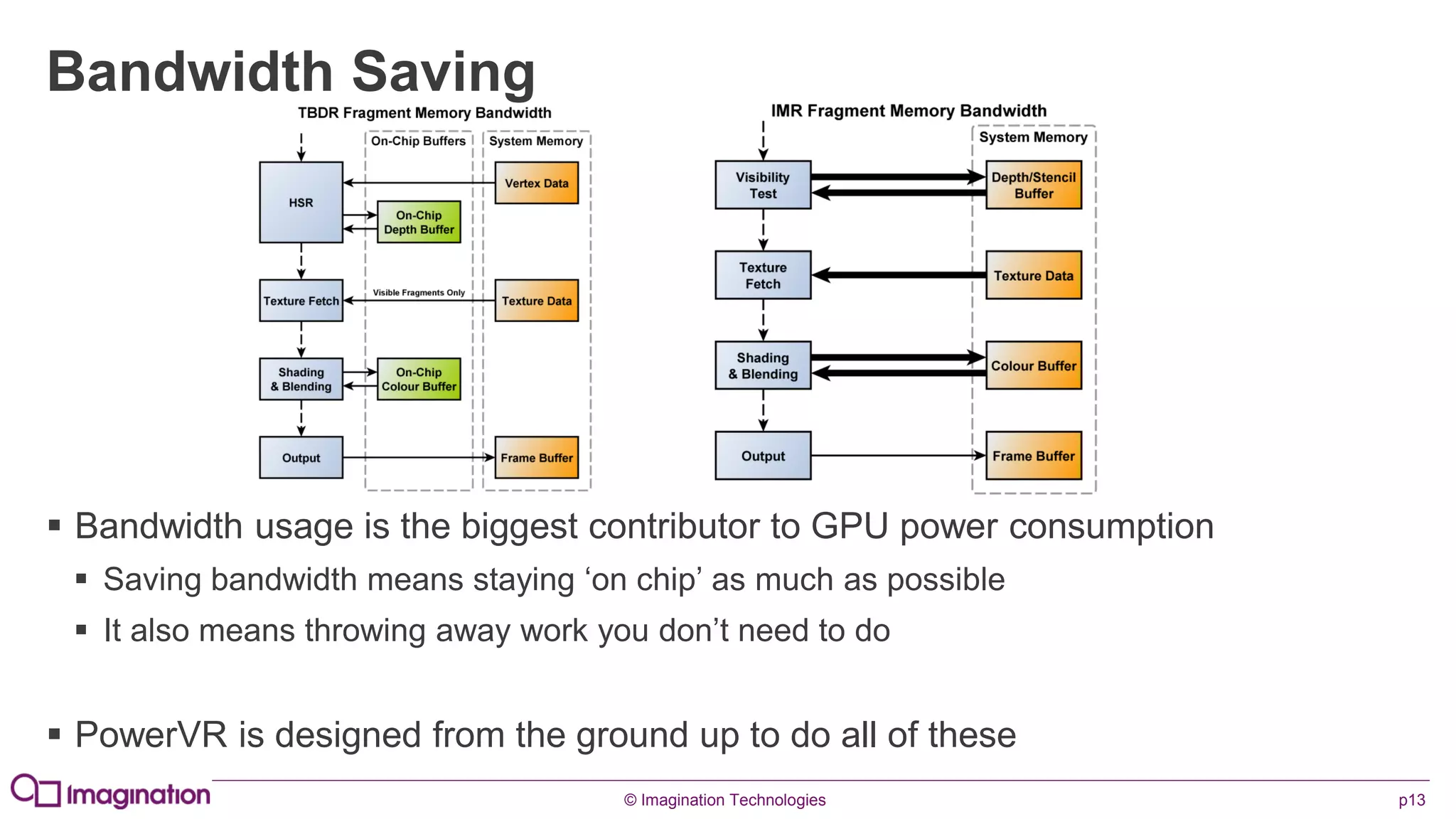
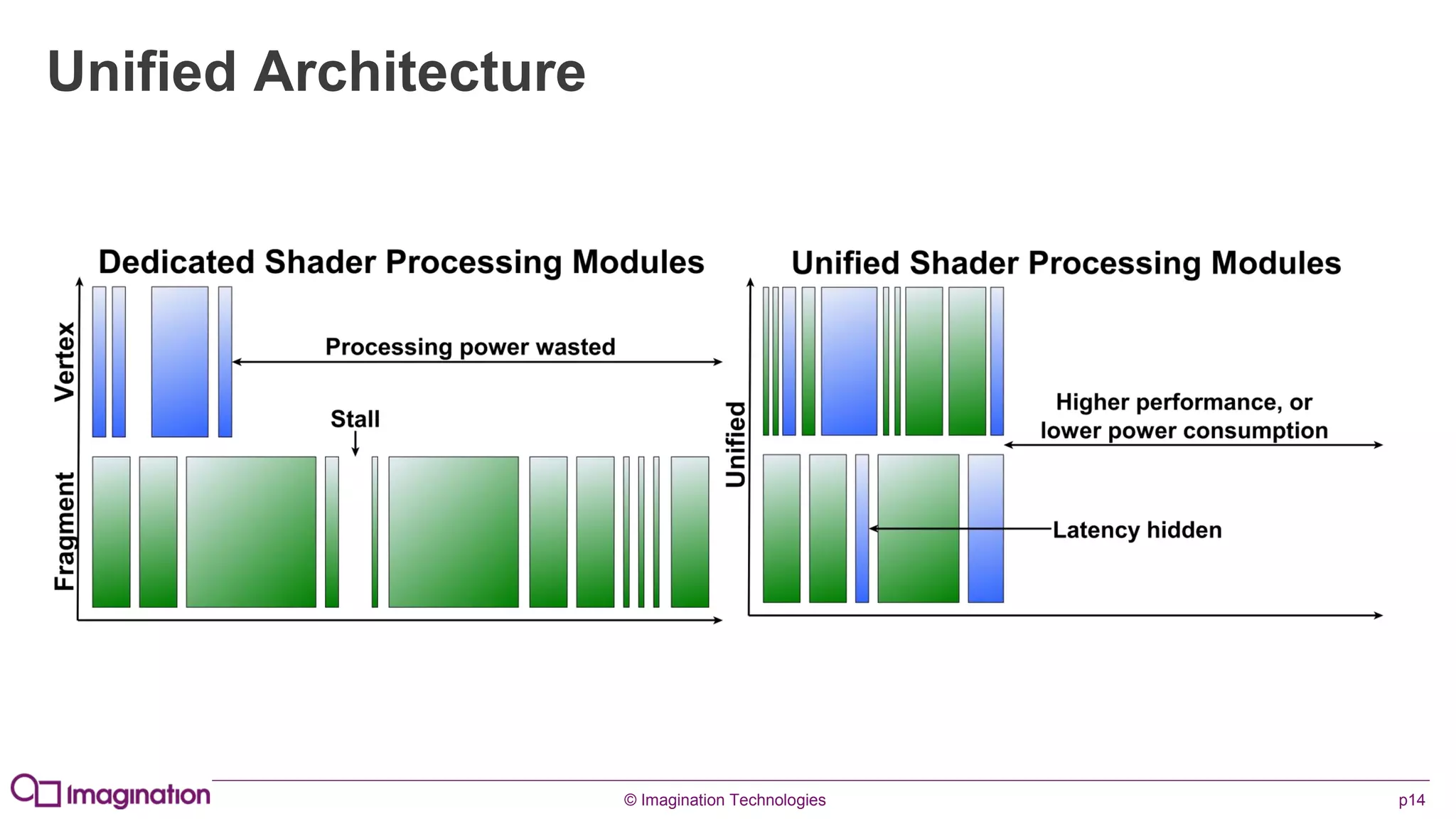
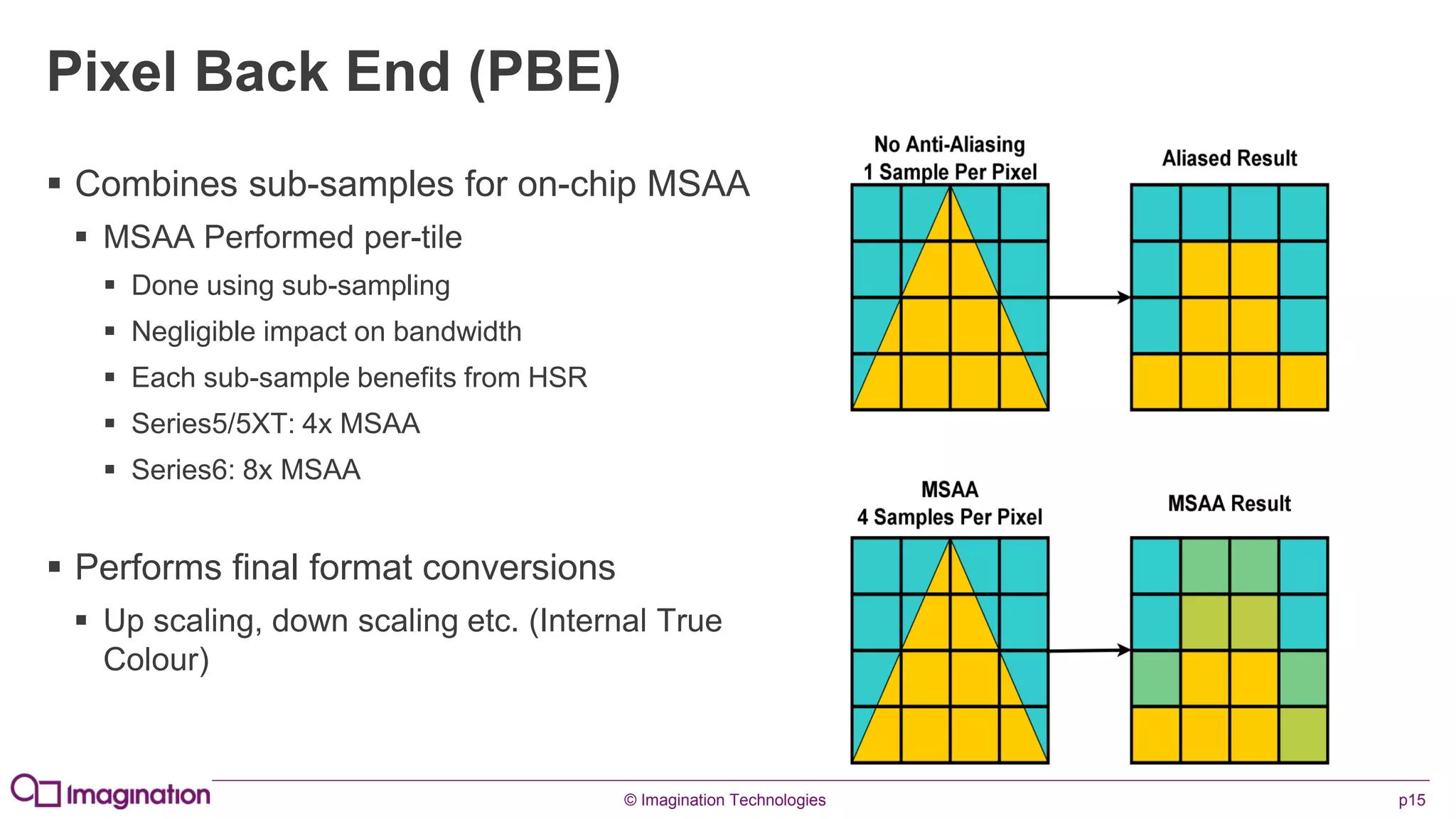

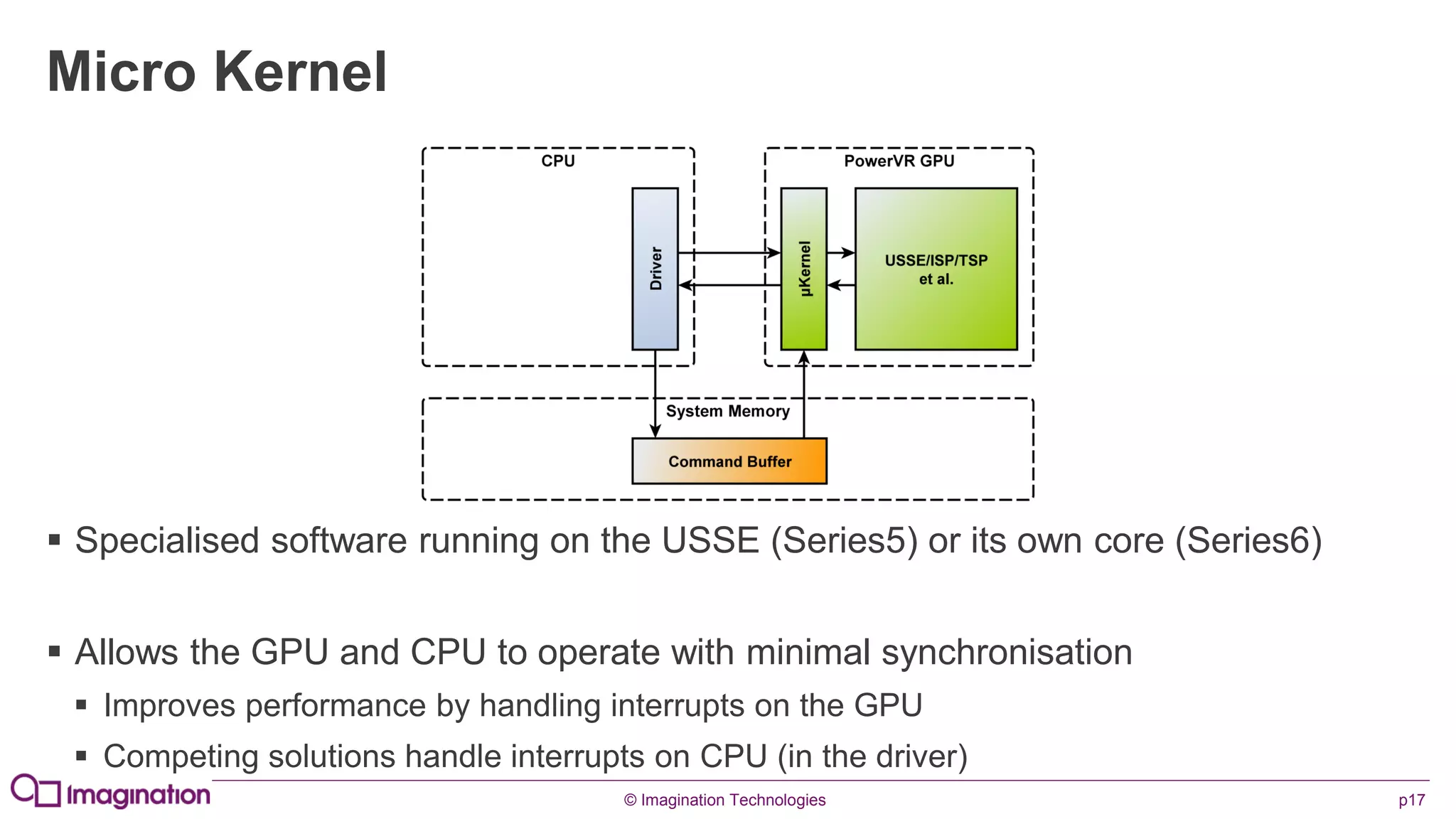
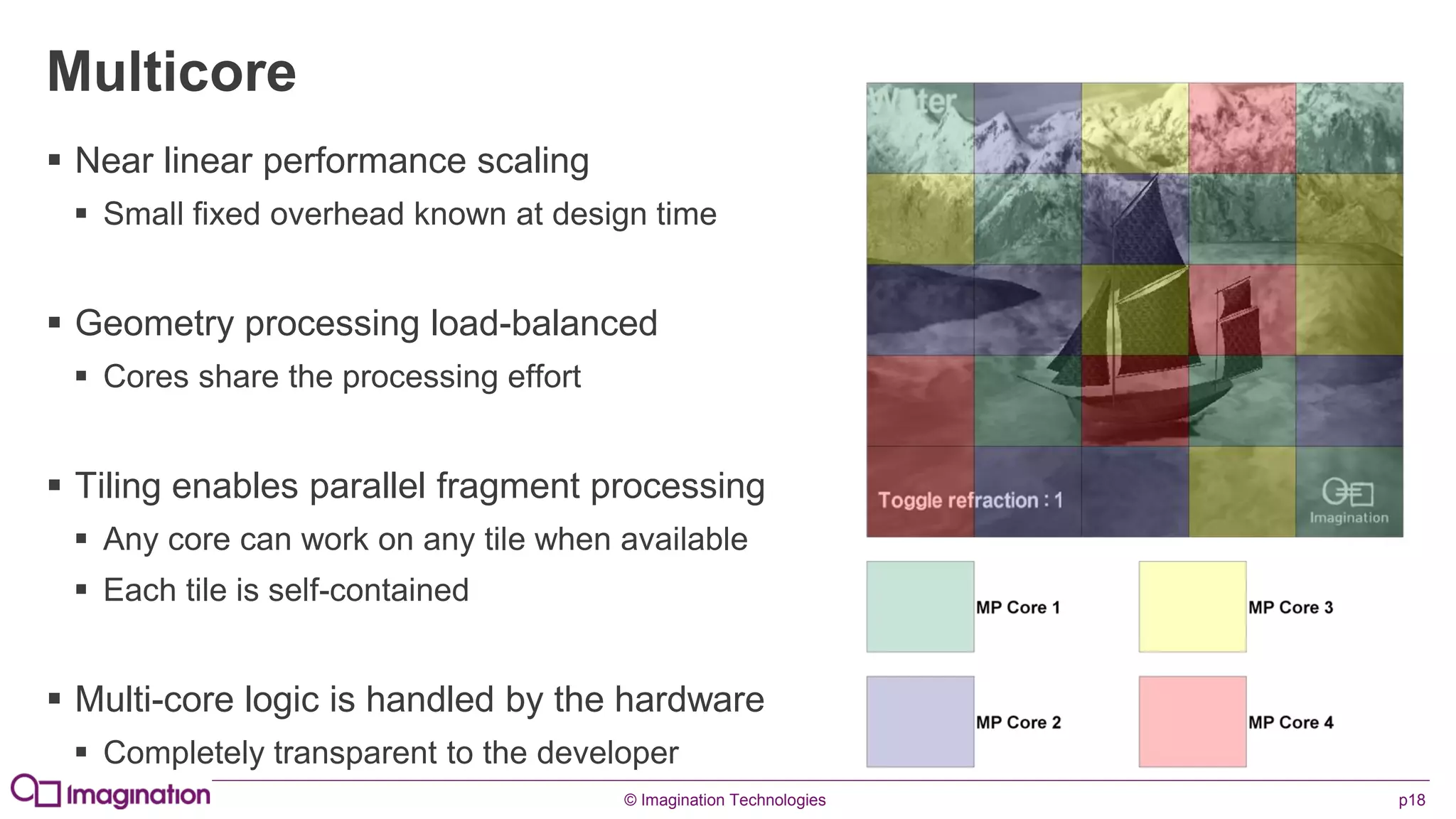






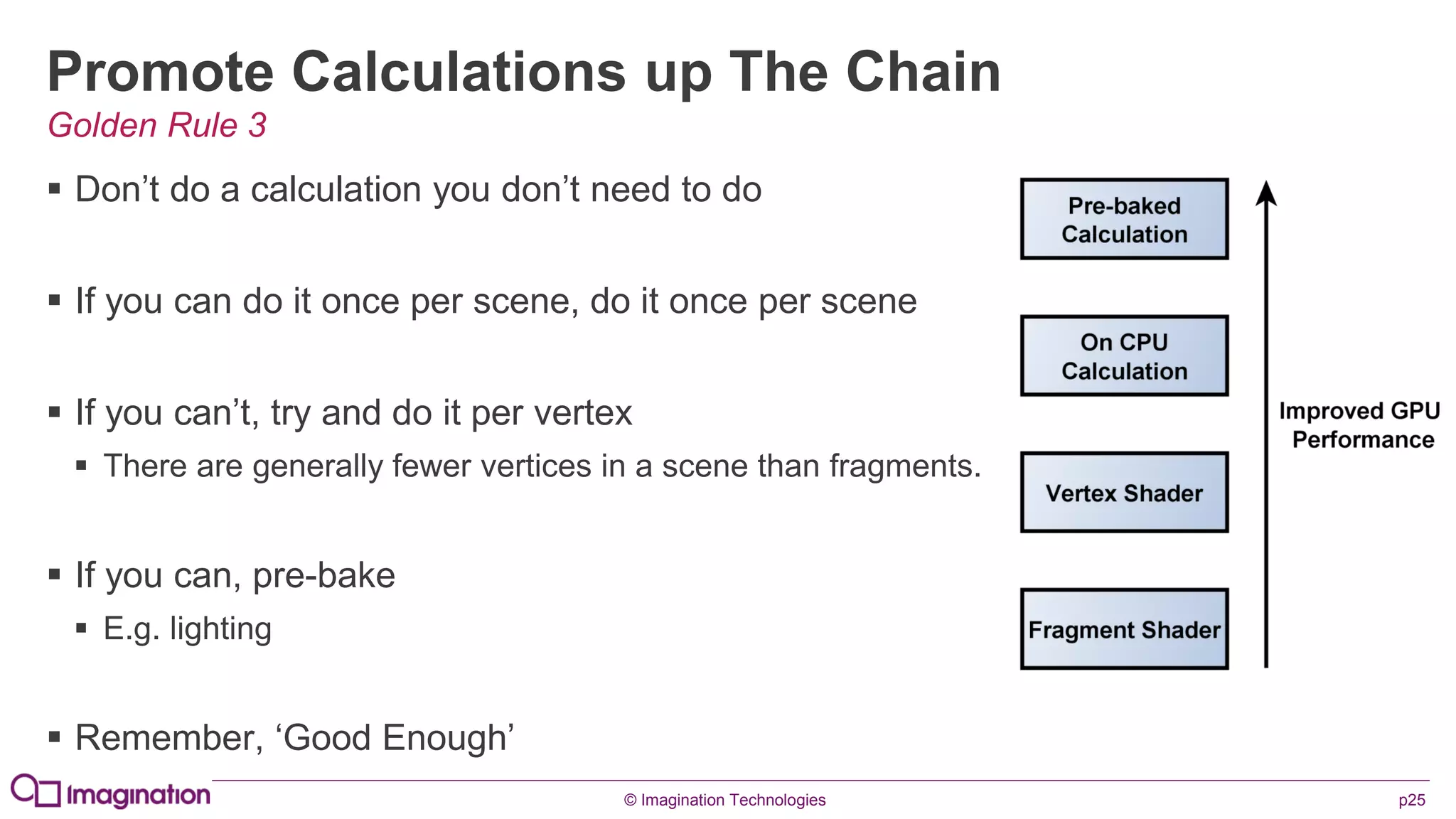
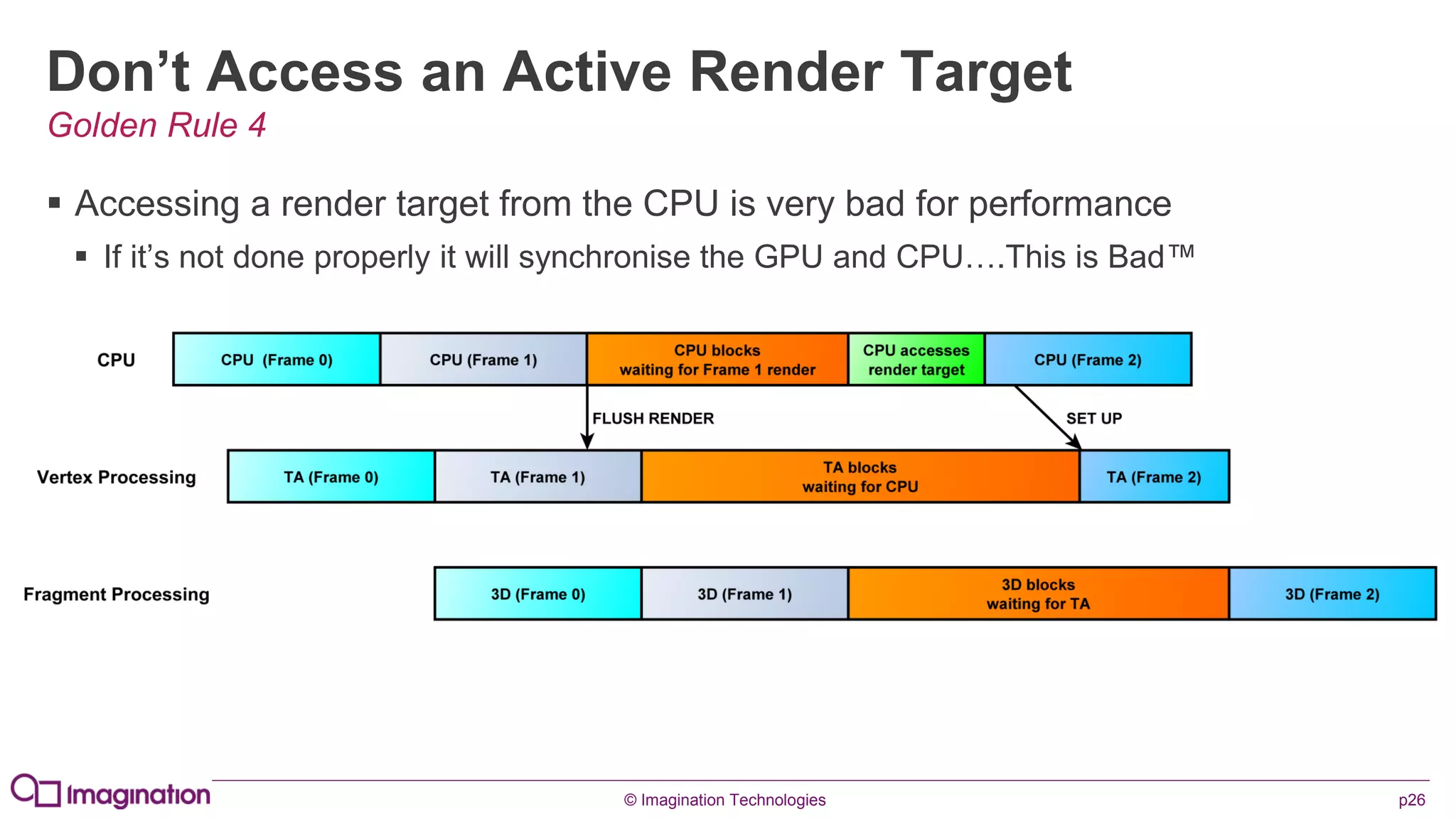
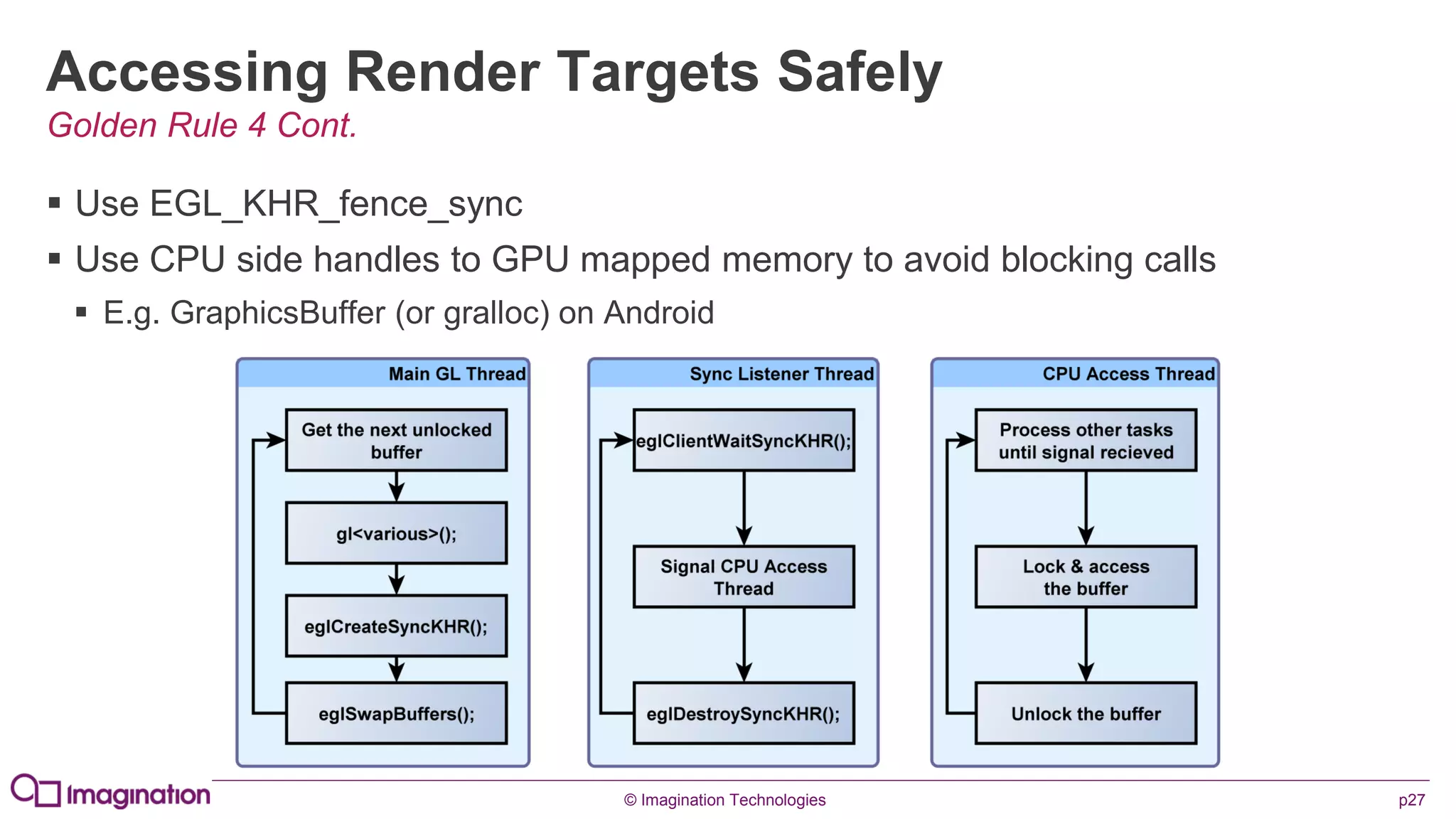
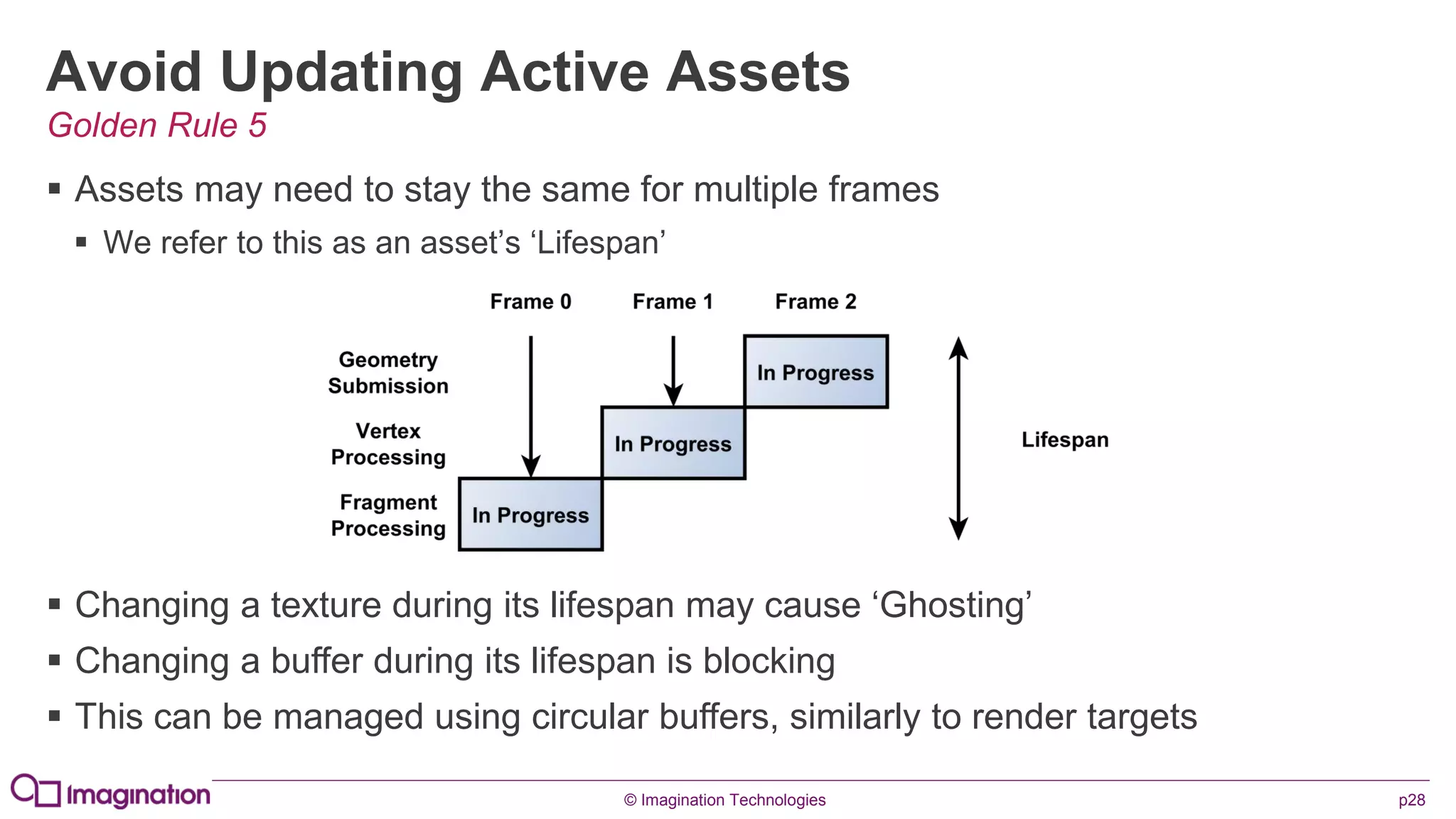

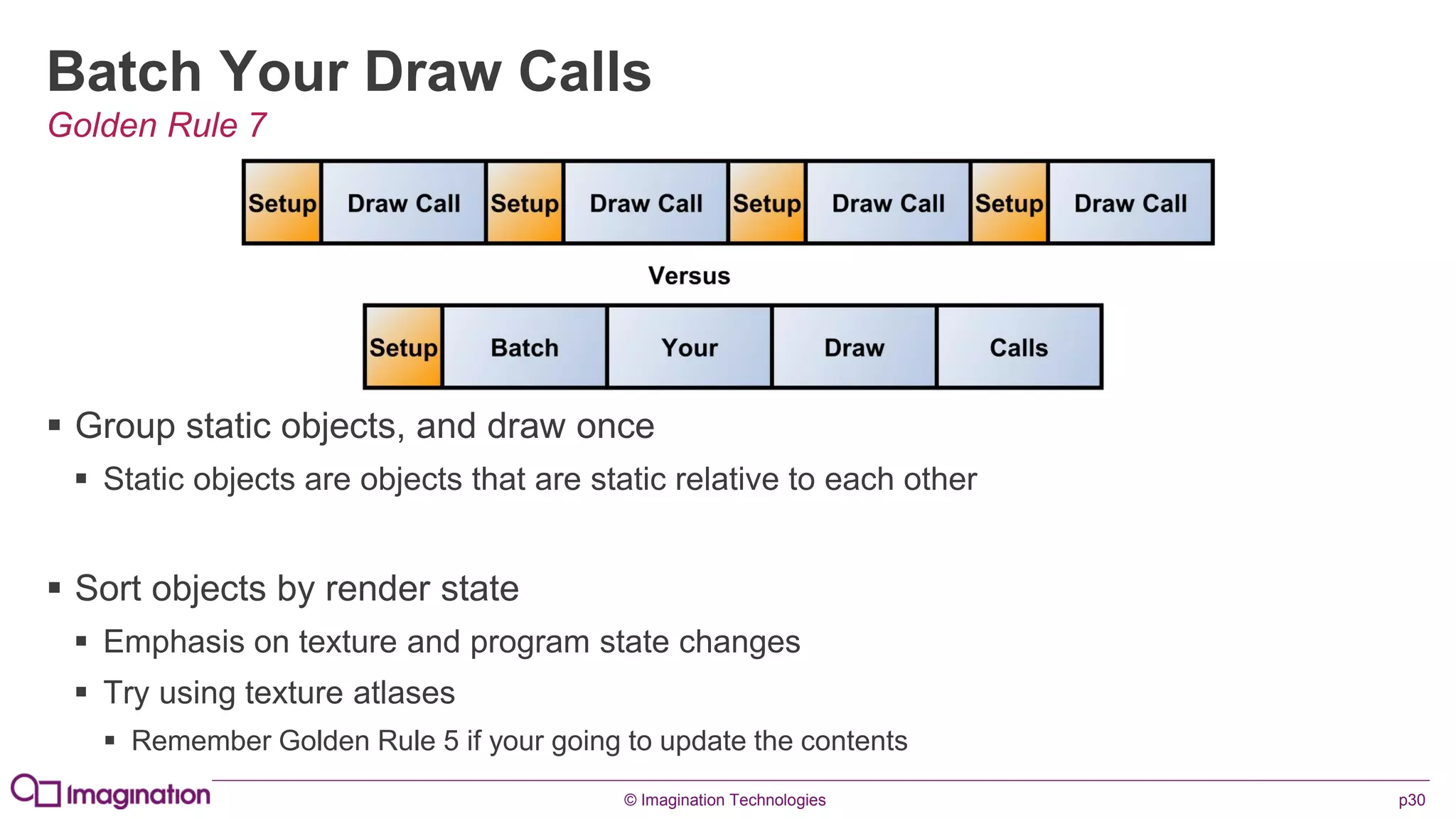
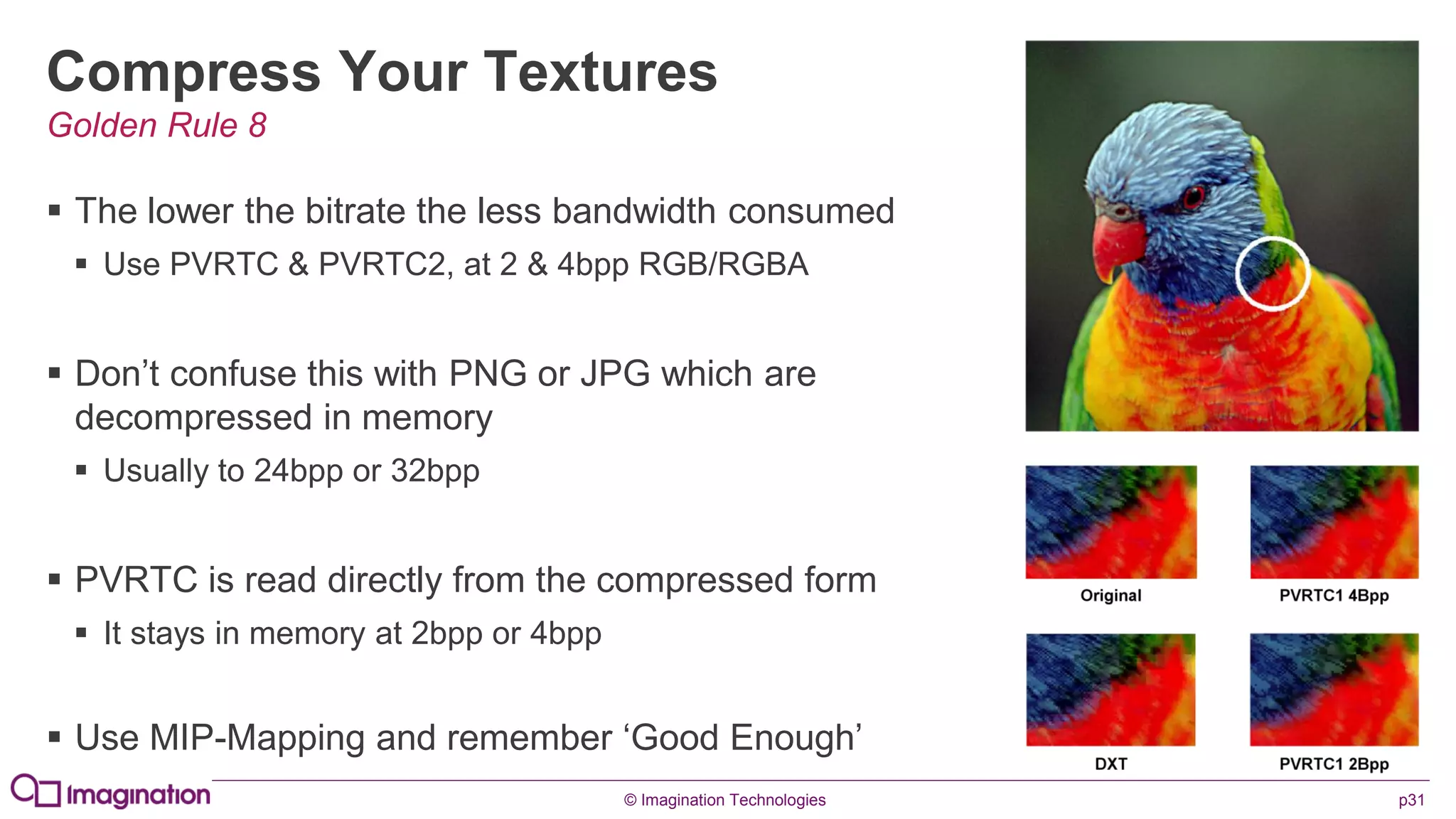
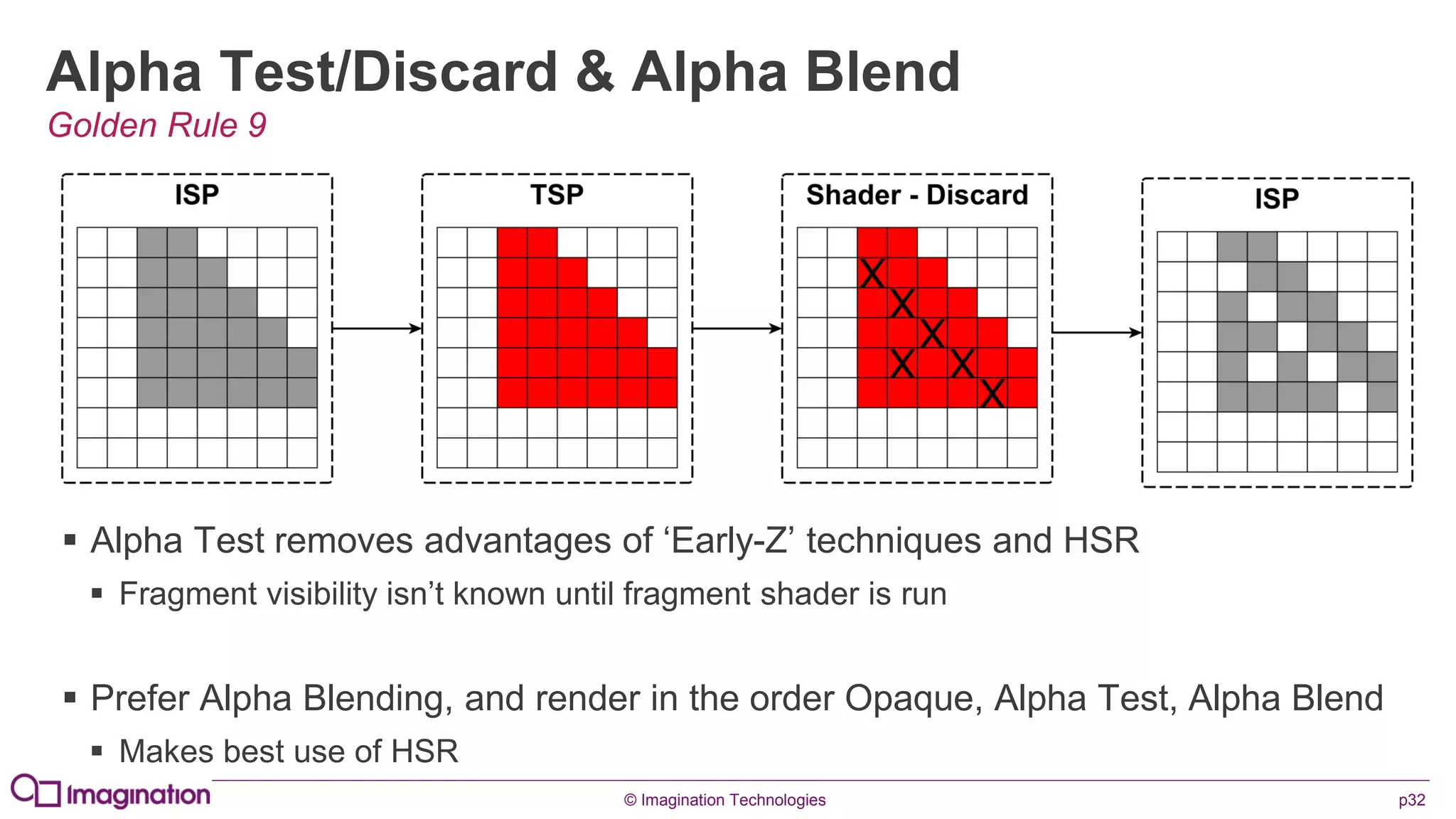




This document provides an overview of graphics processing unit (GPU) architectures and optimization techniques for mobile GPUs. It discusses tile-based deferred rendering architectures like PowerVR, which process graphics per tile to take advantage of on-chip memory. It then provides "golden rules" for optimizing code for mobile GPUs, such as avoiding unnecessary calculations, batching draw calls, using compressed textures, and leveraging the GPU's hidden surface removal capabilities.









![[GDC 2012] Enhancing Graphics in Unreal Engine 3 Titles Using AMD Code Submis...](https://cdn.slidesharecdn.com/ss_thumbnails/enhancinggraphicsinunrealengine3titlesusingnewcodesubmissions-150222111053-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)










































![[TGDF 2020] Mobile Graphics Best Practices for Artist](https://cdn.slidesharecdn.com/ss_thumbnails/mobilegraphicsbestpracticesforartist-200712102753-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Unity Forum 2019] Mobile Graphics Optimization Guides](https://cdn.slidesharecdn.com/ss_thumbnails/20191108taipeiunityforum-191204024024-thumbnail.jpg?width=640&height=640&fit=bounds)





![[Unite Seoul 2020] Mobile Graphics Best Practices for Artists](https://cdn.slidesharecdn.com/ss_thumbnails/arm-uniteseoul2020final-210524084305-thumbnail.jpg?width=640&height=640&fit=bounds)











































