Download as PDF, PPTX



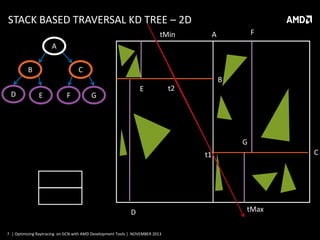
![TRAVERSING KD TREES – PSEUDO CODE
stack.push(KDroot,sceneMin,sceneMax)
tHit=infinity
while !(stack.empty()):
(node,tStart,tEnd)=stack.pop()
while !(node.isLeaf()):
tSplit = ( node.value - ray.origin[node.axis] ) / ray.direction[node.axis]
(near, far) = findNear(ray.origin[node.axis], node.left, node.right)
if( tSplit >= tEnd or tSplit < 0)
node=near
else if( tSplit <= tStart)
node=second
else
stack.push( far, tSplit, tEnd)
node=near
tEnd=tSplit
for prim in node.primitives():
tHit=min(tHit,prim.Intersect(ray))
if tHit<tEnd:
return tHit
return tHit
8 | Optimizing Raytracing on GCN with AMD Development Tools | NOVEMBER 2013](https://image.slidesharecdn.com/pt-4055tzachicohen-131121144249-phpapp02/85/PT-4055-Optimizing-Raytracing-on-GCN-with-AMD-Development-Tools-by-Tzachi-Cohen-8-320.jpg)








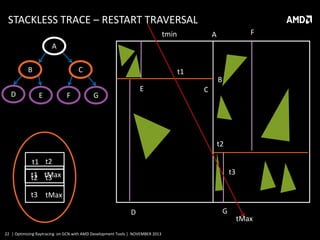
![KD RESTART ALGORITHM
tStart=tEnd=sceneMin
timeHit=infinity
while (tEnd<sceneMax):
node=root
tStart=tEnd
tEnd=sceneMax
while (not node.isLeaf()):
axis = node.axis
tSplit = ( node.PlanePos - ray.origin[axis] ) / ray.direction[axis]
(near, far) = findNear(ray.origin[axis], node.left, node.right)
if( tSplit >= tEnd or tSplit <= 0)
node=near
else if( tSplit <= tStart)
node=far
else
node=near
tEnd=tSplit
for prim in node.primitives():
timeHit=min(tHit,prim.Intersect(ray))
if timeHit<tEnd:
return tHit
return tHit
23 | Optimizing Raytracing on GCN with AMD Development Tools | NOVEMBER 2013](https://image.slidesharecdn.com/pt-4055tzachicohen-131121144249-phpapp02/85/PT-4055-Optimizing-Raytracing-on-GCN-with-AMD-Development-Tools-by-Tzachi-Cohen-23-320.jpg)



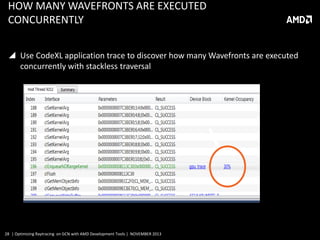
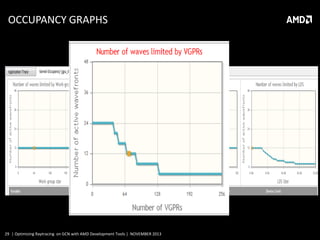


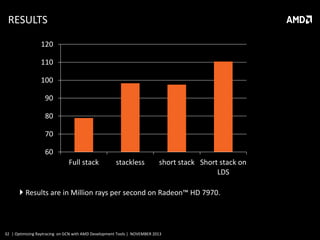




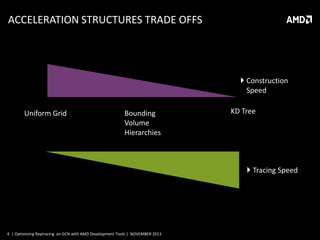
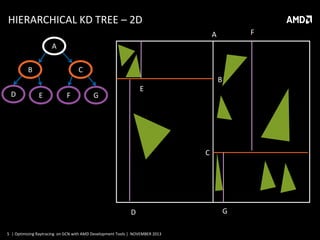
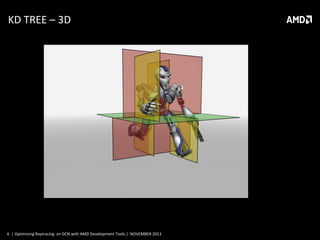
This document discusses optimizing raytracing on AMD's GCN architecture using AMD development tools. It provides an overview of raytracing and KD trees, describes the GCN architecture and its scalar nature, and how this impacts raytracing. It then discusses mapping raytracing to GPUs, optimizing with a stackless traversal and short stack in local memory. CodeXL is used to analyze occupancy and optimize the kernel further.































![[Harvard CS264] 11b - Analysis-Driven Performance Optimization with CUDA (Cli...](https://cdn.slidesharecdn.com/ss_thumbnails/analysisdrivenoptimization-110407230024-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 11a - Programming the Memory Hierarchy with Sequoia (Mike Bau...](https://cdn.slidesharecdn.com/ss_thumbnails/analysisdrivenoptimization-110407225811-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)











![[2018 GDC] Real-Time Ray-Tracing Techniques for Integration into Existing Ren...](https://cdn.slidesharecdn.com/ss_thumbnails/gdc2018takahiroharada-180330041526-thumbnail.jpg?width=640&height=640&fit=bounds)










































