Downloaded 53 times





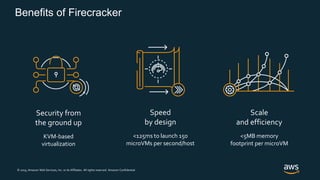


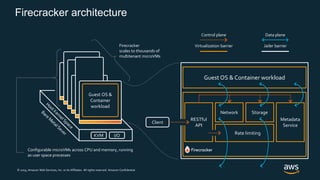


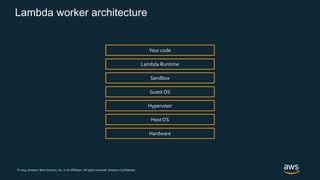
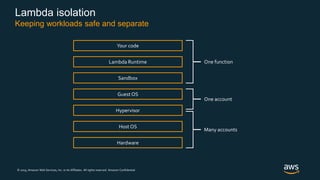

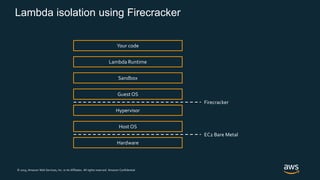
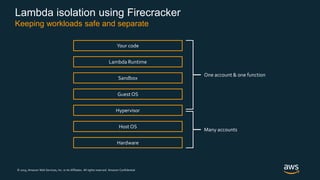
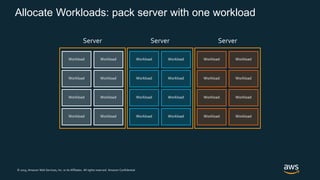
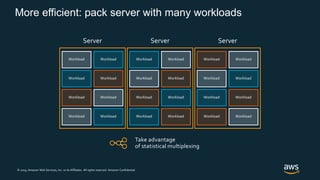
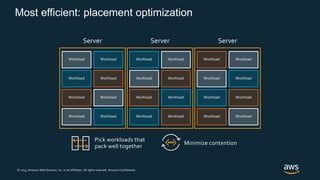








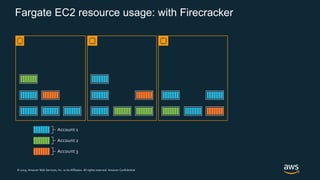


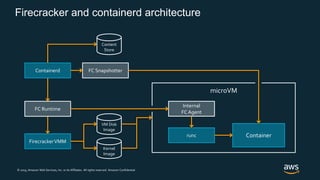




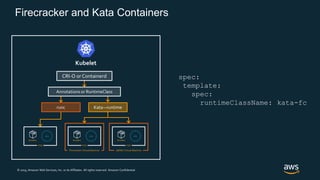







Firecracker is a lightweight virtualization technology developed by Amazon that provides security and isolation of virtual machines with the speed and density of containers. It uses KVM virtualization and has a minimal guest device model to provide fast launch times of less than 125ms per microVM while using under 5MB of memory per microVM. Firecracker is open source and designed to securely run thousands of multitenant microVMs on a single host through its REST API and by leveraging statistical multiplexing of resources.



















![[AWS Dev Day] 실습워크샵 | Amazon EKS 핸즈온 워크샵](https://cdn.slidesharecdn.com/ss_thumbnails/awsdevdayseoul2019-amazonekshands-onworkshopv0-190930092336-thumbnail.jpg?width=640&height=640&fit=bounds)


































































