Download to read offline










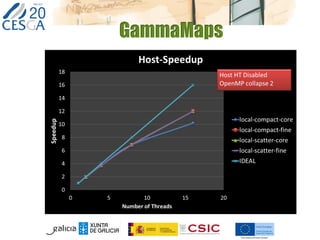
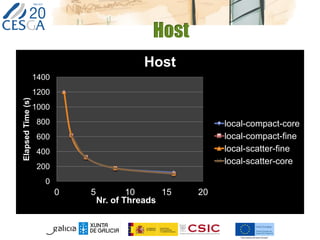
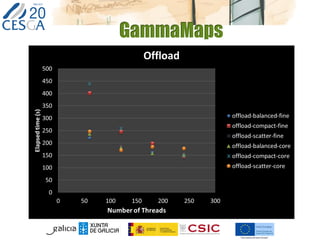
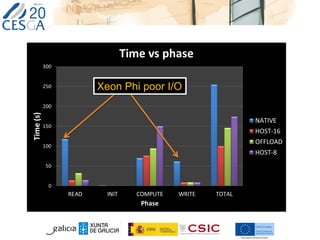




This document discusses lessons learned from porting two applications, CalcuNetW and GammaMaps, to the Intel Xeon Phi coprocessor. CalcuNetW calculates measurements in complex networks using MKL libraries, while GammaMaps performs dose calculations for radiation therapy using OpenMP pragmas. Both applications saw performance improvements when run natively on the Xeon Phi, with one Phi providing similar performance as one host Xeon CPU. However, I/O performance was poor on the Phi. With minimal code changes like pragmas, basic performance gains were achieved, but more work is needed for full optimization.





































































