Download as PDF, PPTX














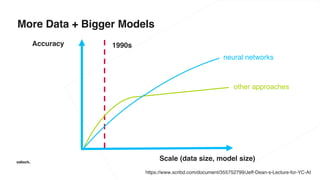
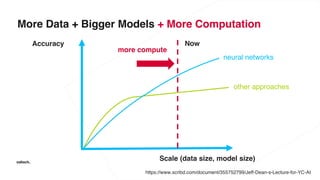











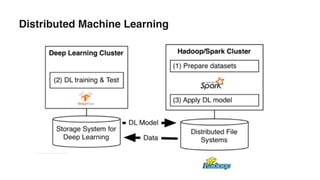


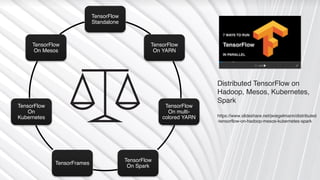















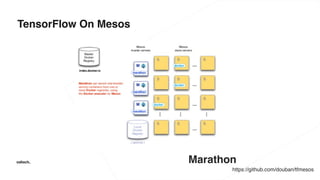


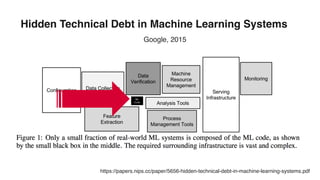





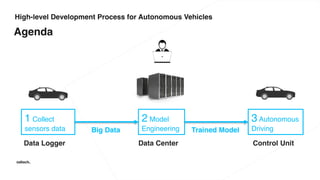

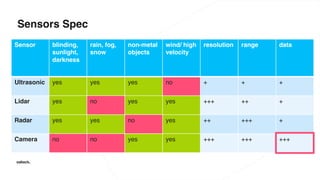
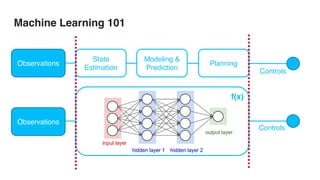














The document discusses various advancements in distributed deep learning using platforms like Hadoop and TensorFlow, illustrating their applications in image classification and AI performance compared to human capabilities. It reviews key developments in machine learning, covering historical milestones, data processing strategies, and computational improvements for training large models. Additionally, it touches on real-world case studies and highlights platforms for machine learning deployments such as Google AI and Uber's Michelangelo.






![[Paper Review] Continual learning with deep generative replay](https://cdn.slidesharecdn.com/ss_thumbnails/continuallearningwithdeepgenerativereplay-170529100241-thumbnail.jpg?width=640&height=640&fit=bounds)










![[PR12] You Only Look Once (YOLO): Unified Real-Time Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/yolo-170616085751-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]LightTrack: A Generic Framework for Online Top-Down Human Pose Tracking](https://cdn.slidesharecdn.com/ss_thumbnails/200124dlseminar-200124001212-thumbnail.jpg?width=640&height=640&fit=bounds)