Downloaded 63 times



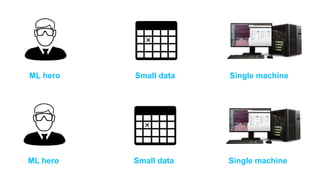


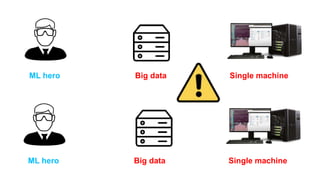
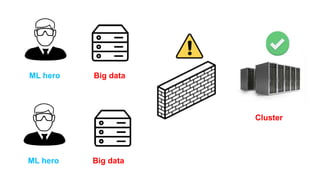
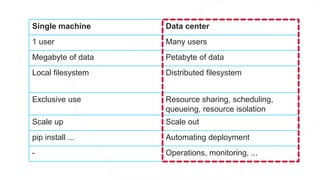


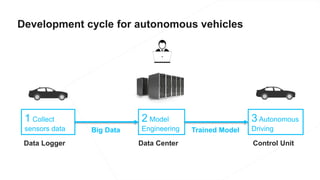


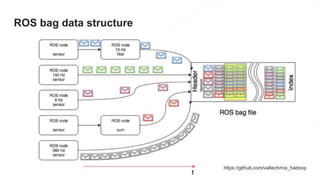
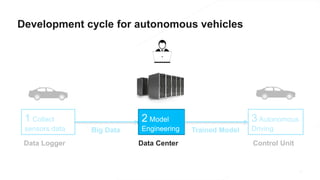
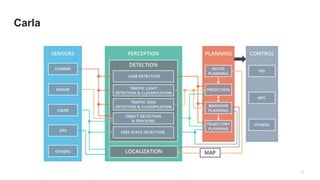
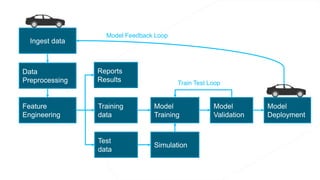
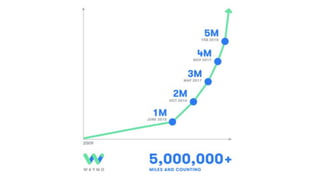
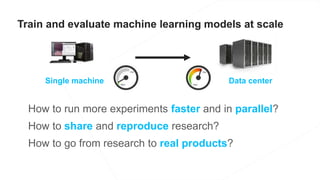
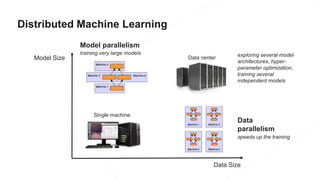
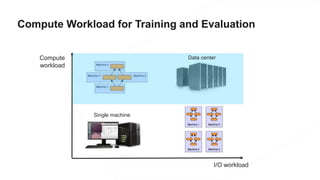
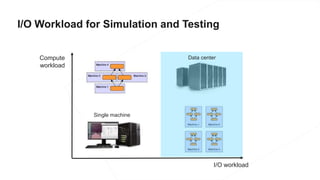

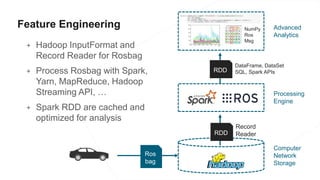
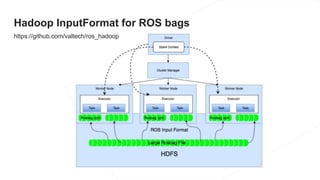
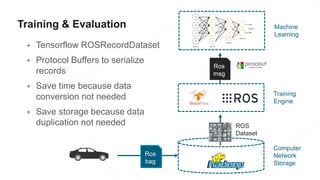
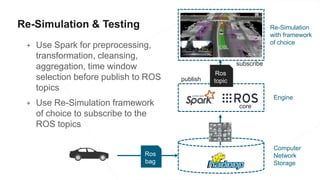


The document discusses the end-to-end machine learning pipeline, emphasizing the management of data and the use of various technologies like ROS and Hadoop for autonomous vehicle development. It explores aspects of data collection, model training, simulation, and deployment, highlighting the importance of distributed machine learning and resource management in handling large datasets. Additionally, it introduces the Flux open machine learning stack, which supports efficient experimentation and collaboration in machine learning projects.



































































