Download to read offline






























































![C++ Concurrency in Action Study
C++ Korea
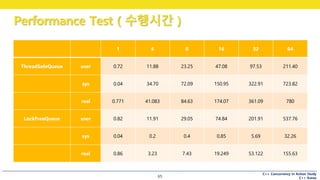
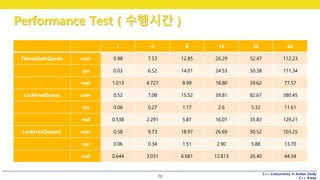
Performance Test ( 시나리오 )
63
TIME(1) BSD General Commands Manual TIME(1)
NAME
time -- time command execution
SYNOPSIS
time [-lp] utility
DESCRIPTION
The time utility executes and times utility. After the utility finishes, time writes the
total time elapsed, the time consumed by system overhead, and the time used to execute
utility to the standard error stream. Times are reported in seconds.
DoO@DooSeonui-MacBook-Air ~/Work/Study/Whatever/LockFreeQueue/build master ● time
shell 0.09s user 0.09s system 5% cpu 3.440 total
children 0.11s user 0.20s system 8% cpu 3.440 total
User User Mode 에서 CPU 를 사용한 시간
sysem Kernel Mode 에서 CPU 를 사용한 시간
total 총 CPU 를 사용한 시간](https://image.slidesharecdn.com/chapter07-160405123107/85/CppConcurrencyInAction-Chapter07-63-320.jpg)












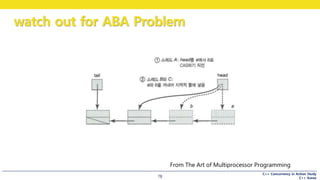
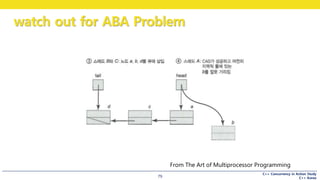

















This document discusses the implementation of a lock-free queue in C++. It begins with an overview of blocking vs non-blocking behavior and synchronization primitives like mutexes. It then presents the implementation of a single-producer, single-consumer lock-free queue using atomic operations. It shows how push and pop operations are performed concurrently without locking by atomically updating shared queue pointers. It also discusses techniques like helping other threads complete operations to ensure lock-free progress.


















![[系列活動] Data exploration with modern R](https://cdn.slidesharecdn.com/ss_thumbnails/dataexplorationwithmodernr1221-161219044516-thumbnail.jpg?width=640&height=640&fit=bounds)
















































