Download as PDF, PPTX

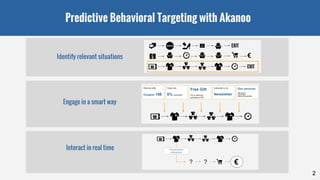









![Main class, main function
15
Pattern composition
Main class:
class SequenceRDDFunctions(
database: RDD[(SessionId, Pattern)]
)
Main function:
def mineFrequentPatterns(
patternGenerator: PatternGenerator,
minSupFraction: Double = 0.05
): List[PatternWithOccRddAndSupport]
Pattern
case class Pattern(
elements: Seq
[ItemSet]
)
val p = Pattern(
elements: Seq(a, d, c)
)
ItemSet
case class ItemSet(
items: Seq[Item])
val a = ItemSet(items =
Seq(item1)
)
Item
case class Item(
letter: Letter)
val item1 = Item(
letter =
pageTypeOverviewLetter
)
Letter type Letter = Int
val pageTypeOverviewLetter:
Letter = 1](https://image.slidesharecdn.com/prefixspanwithspark-151125163911-lva1-app6891/85/PrefixSpan-With-Spark-at-Akanoo-15-320.jpg)
![From Session to Pattern (1 / 2)
16
{
"SessionID":"49624d7e",
...
},
{
"pageType":"overview",
...
},
{
"pageType":"product",
...
},
{
"pageType":"checkout",
...
},
Session
(json)
Visit
case class Visit(
session: Session,
viewList: List[View]
…
)
case class View (
viewId: String,
time: Long,
pageType: PageType,
…)
val a: View = View(
viewId= "view-id",
pageType = PageType.OVERVIEW,
...
val d: View = View(
viewId= "view-id",
pageType = PageType.PRODUCT,
...
)
val c: View = View(
viewId= "view-id",
pageType = PageType.CHECKOUT,
...
)
)
Views](https://image.slidesharecdn.com/prefixspanwithspark-151125163911-lva1-app6891/85/PrefixSpan-With-Spark-at-Akanoo-16-320.jpg)

![Towards a database of patterns
Creating a pattern from a visit
def generatePattern(visit: Visit):
Pattern = {
val itemSets = visit.map { (view) =>
val itemSet =
pageTypeLetterForView(view)
.map(Item)
.map(ItemSet)
}
Pattern(itemSets)
}
Creating databse ...
… which is an RDD[(SessionId, Pattern)
def mapToPattern(visits: Seq(Visit)): RDD[(SessionId,
Pattern)] = {
visits.map(
visit =>
(visit.session.sessionId,generatePattern(visit)))
}](https://image.slidesharecdn.com/prefixspanwithspark-151125163911-lva1-app6891/85/PrefixSpan-With-Spark-at-Akanoo-18-320.jpg)
![Main class, main function
19
Input params
Main class:
class SequenceRDDFunctions(
database: RDD[(SessionId, Pattern)]
)
Main function:
def mineFrequentPatterns(
patternGenerator: PatternGenerator,
minSupFraction: Double = 0.05
): List[PatternWithOccRddAndSupport]
patternGenerator
a function that lets us grab
the alphabet
minSupFraction: Double
= 0.05
a pattern is frequent if it
occurrs in at least 5% of all
database patterns](https://image.slidesharecdn.com/prefixspanwithspark-151125163911-lva1-app6891/85/PrefixSpan-With-Spark-at-Akanoo-19-320.jpg)
![Main class, main function
20
Main class:
class SequenceRDDFunctions(
database: RDD[(SessionId, Pattern)]
)
Main function:
def mineFrequentPatterns(
patternGenerator: PatternGenerator,
minSupFraction: Double = 0.05
): List[PatternWithOccRddAndSupport]
case class PatternWithOccRddAndSupport(pattern:
Pattern, occRdd: RDD[(SessionId, Occ)], support: Long)
type Occ = Seq[(ItemSetIndex, ItemIndex)]
pattern 1 (a)
example SessionId Occurrence
< a (a b c) (a c) > 1 (0,0), (1,0), (2,0)
< (a d) c > 2 (0,0)
< (e f) (a b) > 3 (1,0)
Support 3
Output
List[PatternWithOccRddAndSupport]
One list item for each length 1 of
frequent patterns](https://image.slidesharecdn.com/prefixspanwithspark-151125163911-lva1-app6891/85/PrefixSpan-With-Spark-at-Akanoo-20-320.jpg)
![How frequent patterns are found (1/6)
1. Calculate the occurrence table of the baseLetters
def occurrencesOfBaseLetters(baseLetter: Letter): RDD[(SessionId, Occ)] = {
database.mapValues(sessionPattern => {
sessionPattern.occurrence(Item(baseLetter))
})
}
case class Pattern(elements: Seq[ItemSet]) {
def occurrence(item: Item): Occ = {
elements.zipWithIndex.filter({
case (itemSet, itemSetIndex) => itemSet.contains(item)
})
.map({ case (itemSet, itemSetIndex) =>
(itemSetIndex, itemSet.indexOf(item))
})}
}
Reminder:
type Occ = Seq[(ItemSetIndex, ItemIndex)]](https://image.slidesharecdn.com/prefixspanwithspark-151125163911-lva1-app6891/85/PrefixSpan-With-Spark-at-Akanoo-21-320.jpg)


![How frequent patterns are found (4/6)
2. Calculate the occurrence tables of (n+1)-Patterns from n-Patterns
// based on pattern of length n, identifies frequent patterns of length n+1 by appending and assembling frequent letters
def getNextFrequentPatterns(previousPattern: Pattern, previousPatternOccurrences: RDD[(SessionId, Occ)]): List
[PatternWithOccRddAndSupport] = {
val appendedFreqPatterns = frequentBaseLettersAndOcccurences.par.map(baseLetterAndOccs => {
//make <a b> + <b> => <a b b>
val nextPattern = previousPattern ++ baseLetterAndOccs.pattern
// joins occurrences of previous pattern and any letter
val joinedOccurrences: RDD[(SessionId, (Occ, Occ))] = previousPatternOccurrences.join(baseLetterAndOccs.occurrences)
// returns occurrences of new pattern
val nextPatternOccurrences: RDD[(SessionId, Occ)] = joinedOccurrences.mapAppendedOccPairToOcc()
PatternWithOccRddAndSupport(nextPattern, nextPatternOccurrences, nextPatternOccurrences.countSupport())
}) // only leaves pattern with enough support
.filter(_.support >= minSup).toList
appendedFreqPatterns
}](https://image.slidesharecdn.com/prefixspanwithspark-151125163911-lva1-app6891/85/PrefixSpan-With-Spark-at-Akanoo-24-320.jpg)
![How frequent patterns are found (5/6)
2. Calculate the occurrence tables of (n+1)-Patterns from n-Patterns
// based on pattern of length n, identifies frequent patterns of length n+1 by appending and assembling frequent letters
def getNextFrequentPatterns(previousPattern: Pattern, previousPatternOccurrences: RDD[(SessionId, Occ)]): List
[PatternWithOccRddAndSupport] = {
…
// prefix OCC, suffix OCC
val joinedOccurrences: RDD[(SessionId, (Occ, Occ))] = previousPatternOccurrences.join(baseLetterAndOccs.occurrences)
// returns occurrences of new pattern
val nextPatternOccurrences: RDD[(SessionId, Occ)] = joinedOccurrences.mapAppendedOccPairToOcc()
...
def mapAppendedOccPairToOcc(): RDD[(SessionId, Occ)] = {
self.mapValues((occPair: (Occ, Occ)) => {
// occP = occ(<a b>) , occS = occ(<c>)
val (occPrefix, occSuffix) = occPair
PseudoProjection.pseudoProjectionAppend(occPrefix, occSuffix)
})
}
joinedOccurrences example entry:
<ac> append <a>
<ac> - prefixOcc: [(1,0), (2,1)]
<a> - suffixOcc: [(0,0), (1,0), (2,0)]
-> (2,0)](https://image.slidesharecdn.com/prefixspanwithspark-151125163911-lva1-app6891/85/PrefixSpan-With-Spark-at-Akanoo-25-320.jpg)
![How frequent patterns are found (6/6)
2. Calculate the occurrence tables of (n+1)-Patterns from n-Patterns
def pseudoProjectionAppend(prefixOcc: Occ, suffixOcc: Occ): Occ =
suffixOcc.filter({ case (suffixItemSetIndex, suffixItemIndex) =>
// suffix occurrence after first occurrence of prefix
suffixItemSetIndex > prefixOcc.map(
{ case (prefixItemSetIndex, _) => prefixItemSetIndex }).min
})
def mapAppendedOccPairToOcc(): RDD[(SessionId, Occ)] = {
self.mapValues((occPair: (Occ, Occ)) => {
// occP = occ(<a b>) , occS = occ(<c>)
val (occPrefix, occSuffix) = occPair
PseudoProjection.pseudoProjectionAppend(occPrefix, occSuffix)
})
}
joinedOccurrences example entry:
<ac> append <a>
<ac> - prefixOcc: [(1,0), (2,1)]
<a> - suffixOcc: [(0,0), (1,0), (2,0)]
-> (2,0)](https://image.slidesharecdn.com/prefixspanwithspark-151125163911-lva1-app6891/85/PrefixSpan-With-Spark-at-Akanoo-26-320.jpg)
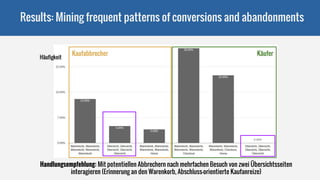


The document discusses the application of the PrefixSpan algorithm for sequential pattern mining using Spark, focusing on predictive behavioral targeting. It highlights the identification of frequent patterns from clickstream data and provides a detailed implementation approach for mining these patterns to understand buyer behaviors. The content includes examples and definitions of patterns, itemsets, and classes necessary for effectively applying the algorithm.






![[系列活動] Data exploration with modern R](https://cdn.slidesharecdn.com/ss_thumbnails/dataexplorationwithmodernr1221-161219044516-thumbnail.jpg?width=640&height=640&fit=bounds)










































![[DSC Europe 25] Egor Krasheninnikov - The Control Stack: Building Guardrails ...](https://cdn.slidesharecdn.com/ss_thumbnails/3lzcz7hxqmo51mtalv4u-the-control-stack-260119101520-ea90841a-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Milovan Jovicic - Beyond AI's Reach: The Enduring Value of Ev...](https://cdn.slidesharecdn.com/ss_thumbnails/pyeij0hurgwq5jugmtnv-2-milovan-jovicic-beyond-ais-reach-the-enduring-value-of-evergreen-design-v2-260120105856-d6ee57e5-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Jovan Sumarac - Real-World Applications of Computer Vision in...](https://cdn.slidesharecdn.com/ss_thumbnails/fiksms22smcpopvvld03-jovan-sumarac-real-life-applications-of-computer-vision-in-automotive-systems-260120105855-de622abb-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Bojan Banjac - AI is always right when it comes to the matter...](https://cdn.slidesharecdn.com/ss_thumbnails/syoxtqierpydwxm5srcb-4-bojan-banjac-ai-is-always-right-when-it-comes-to-the-matters-of-taste-260119101519-694ee7d7-thumbnail.jpg?width=640&height=640&fit=bounds)

