Downloaded 16 times


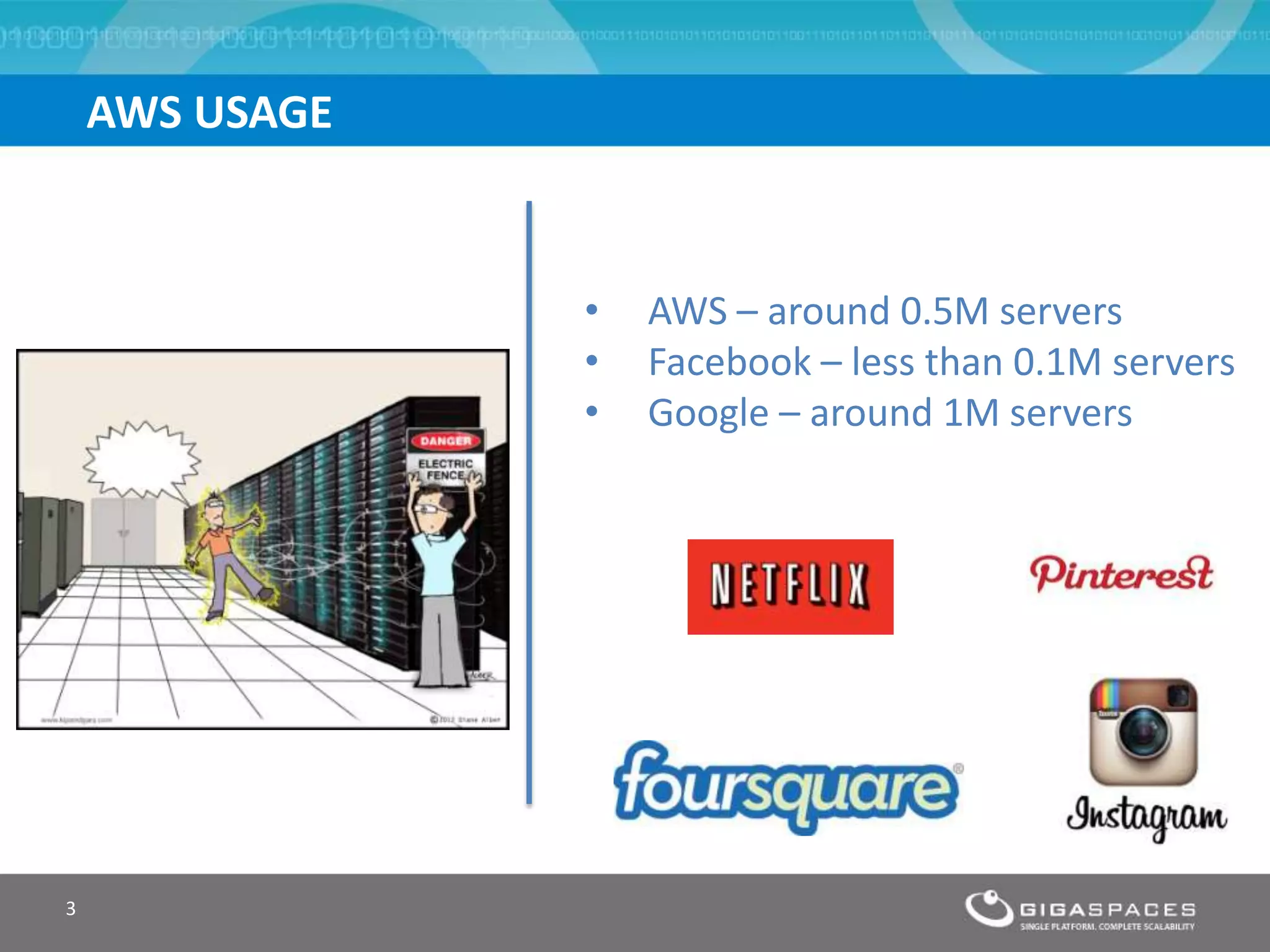



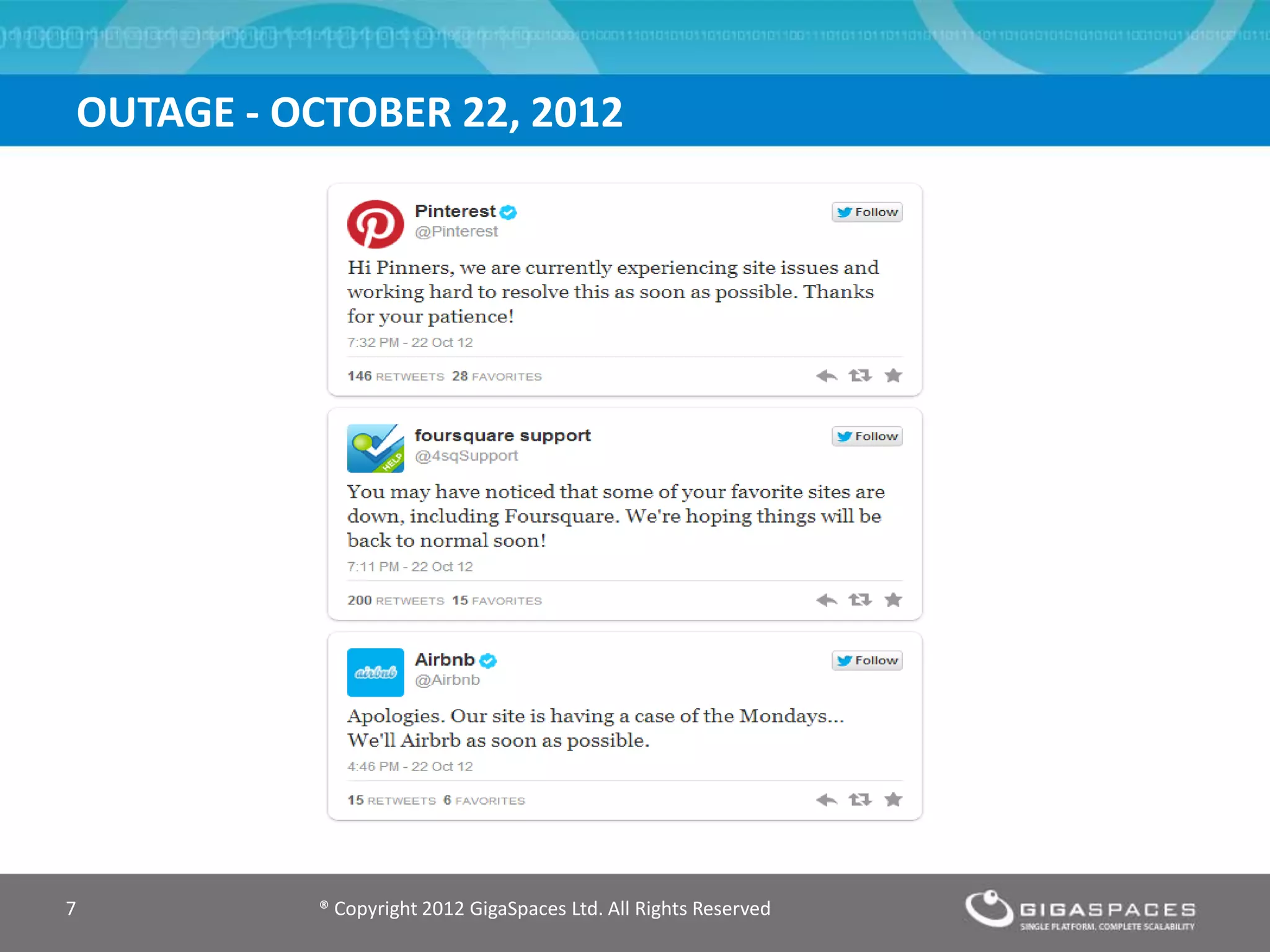
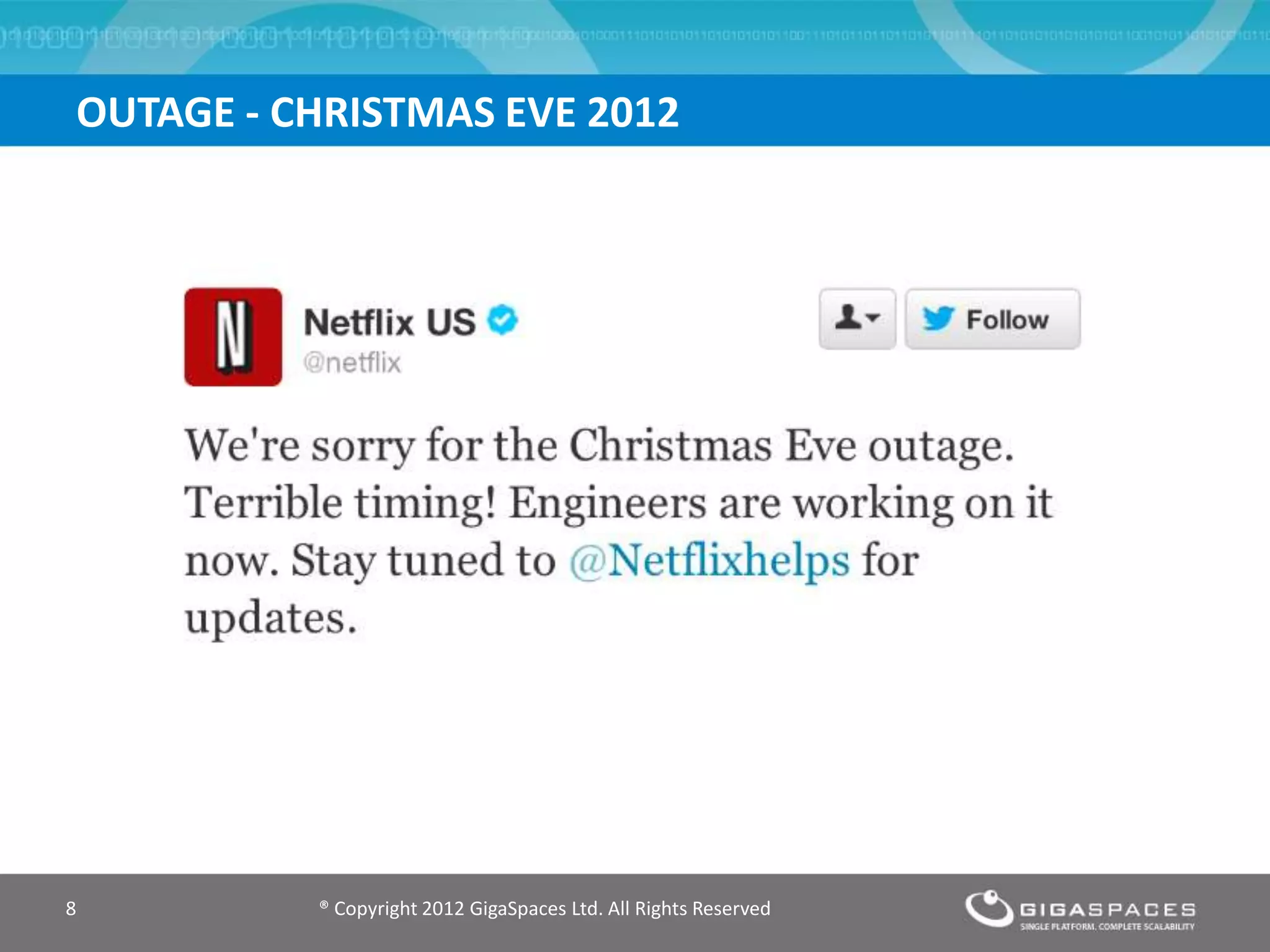










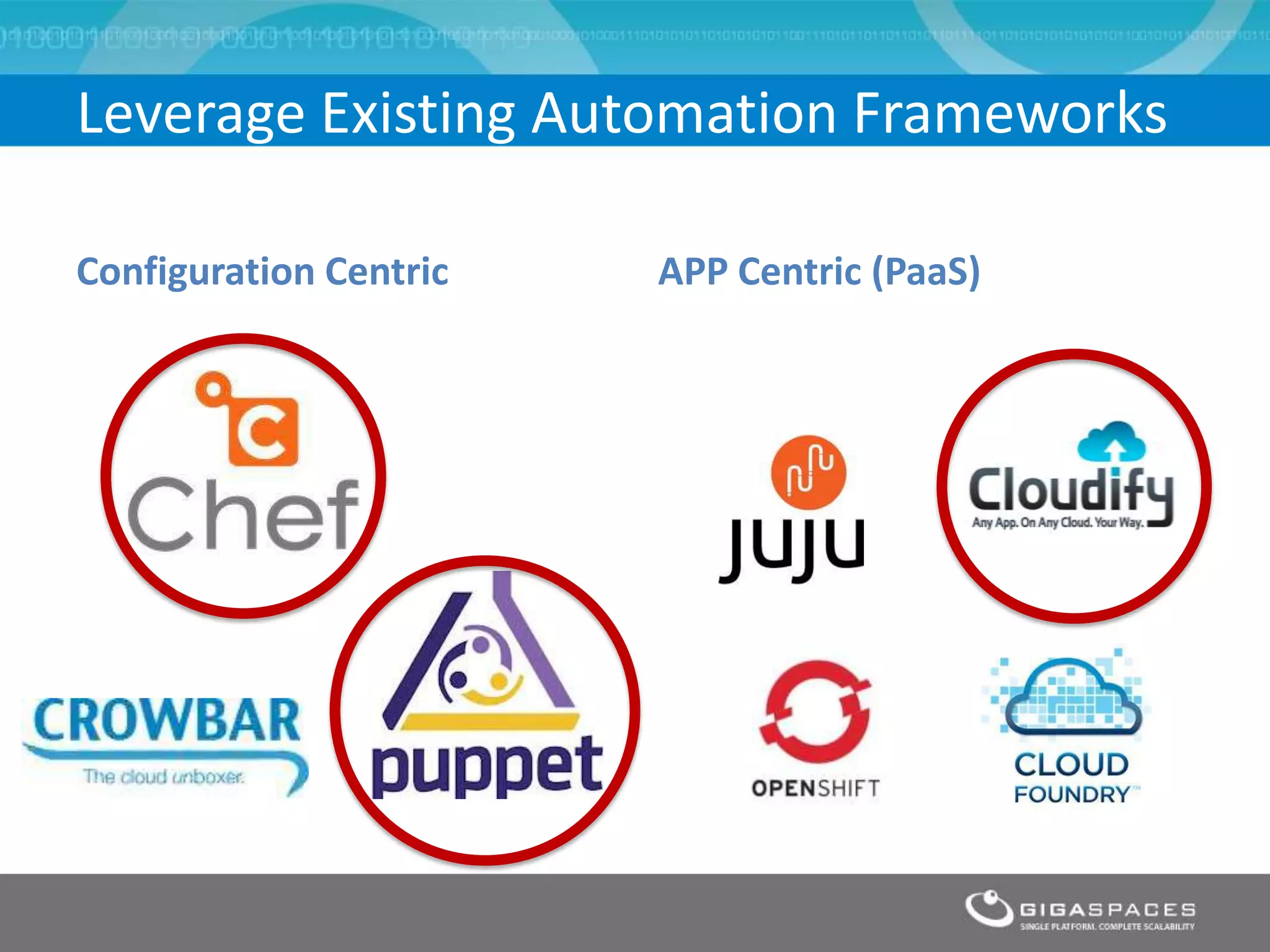
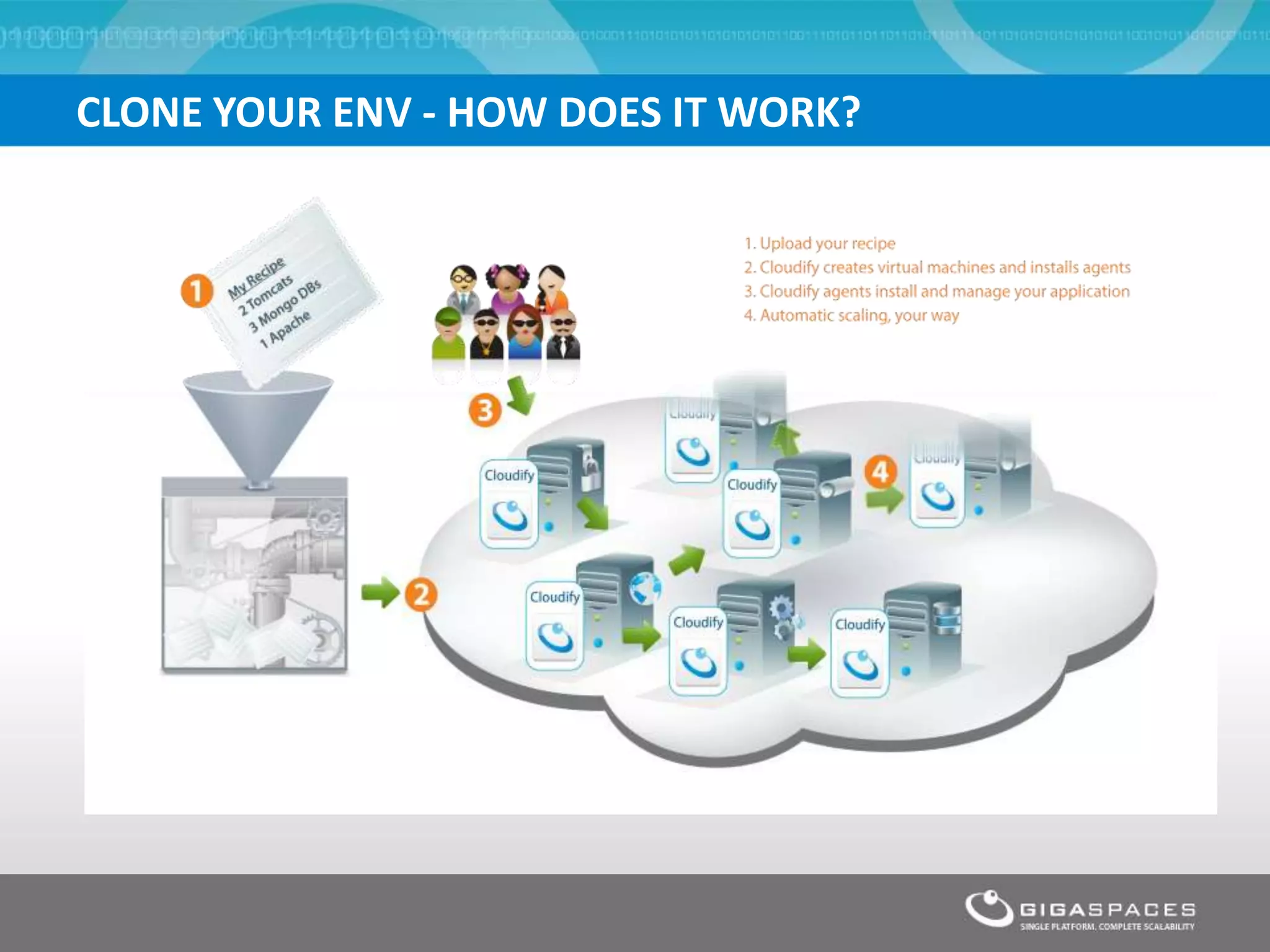
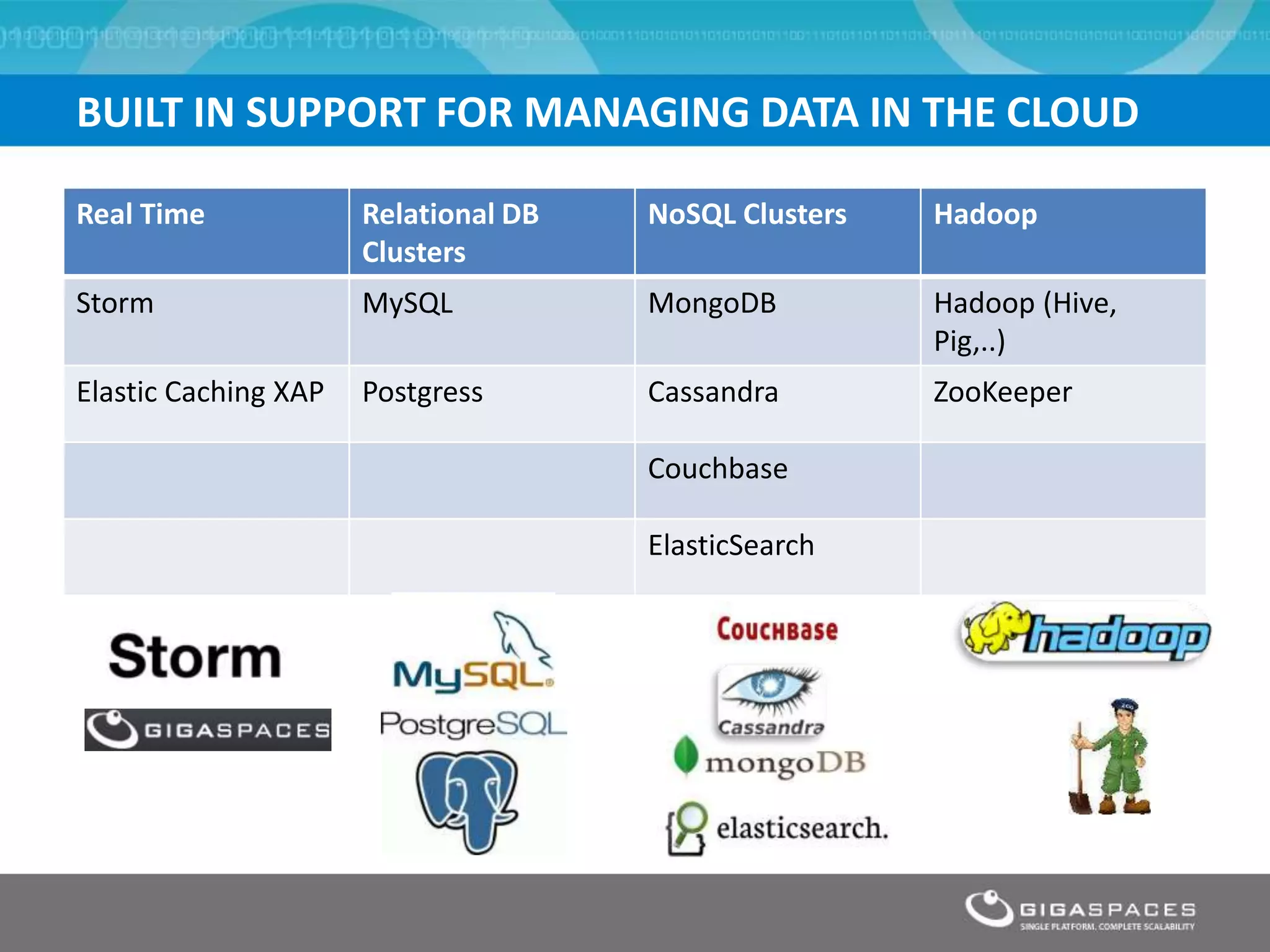

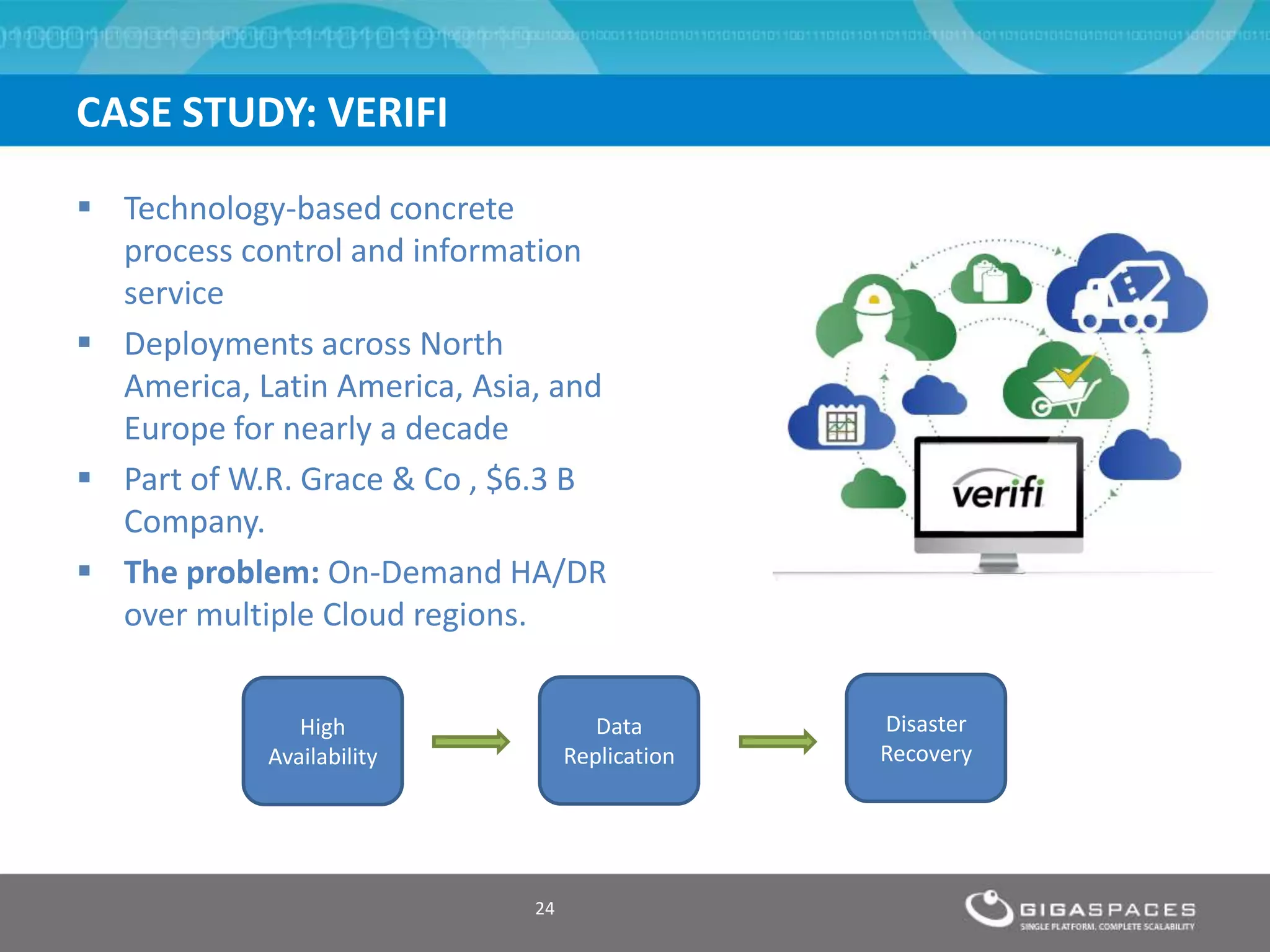
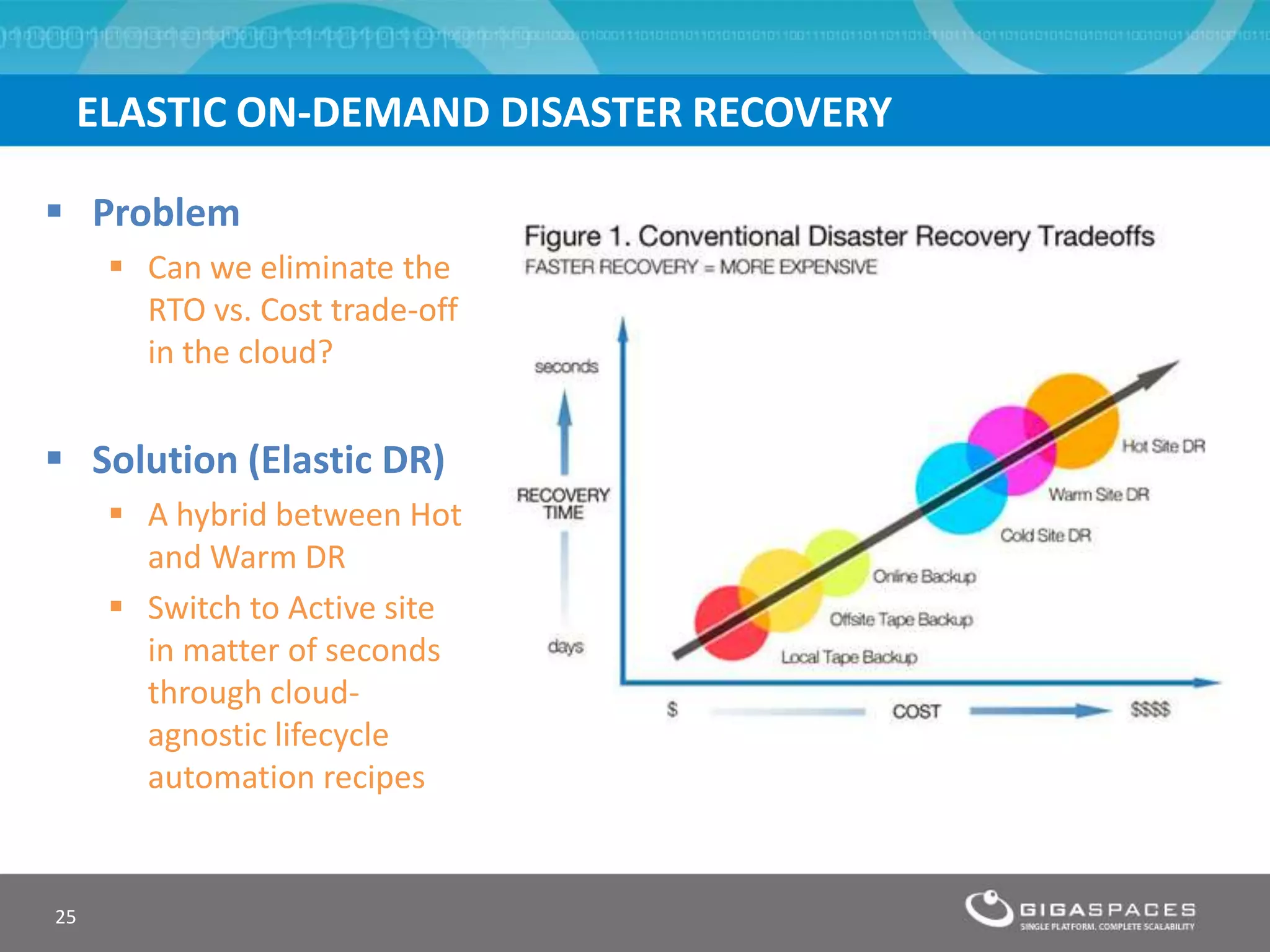
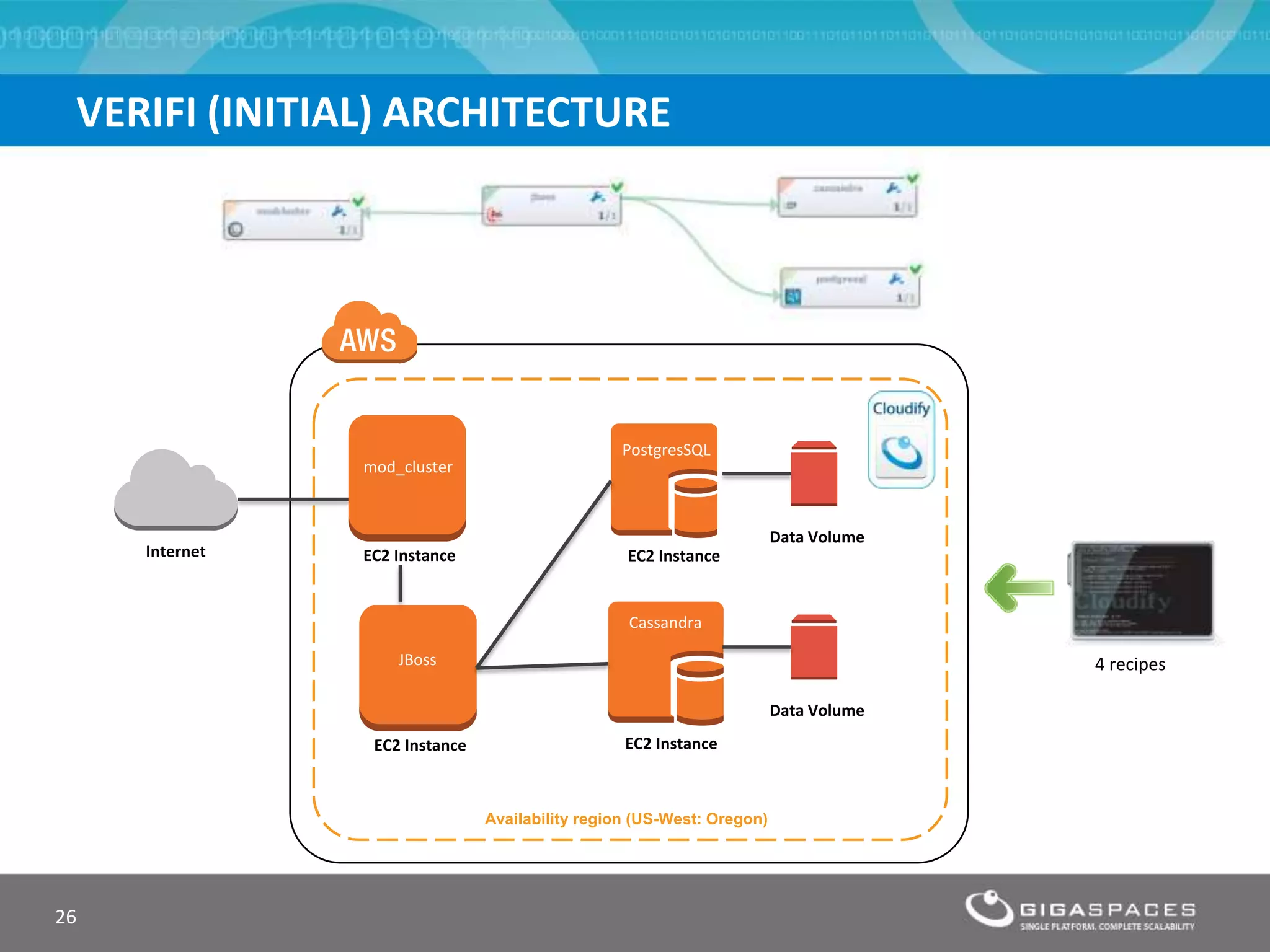
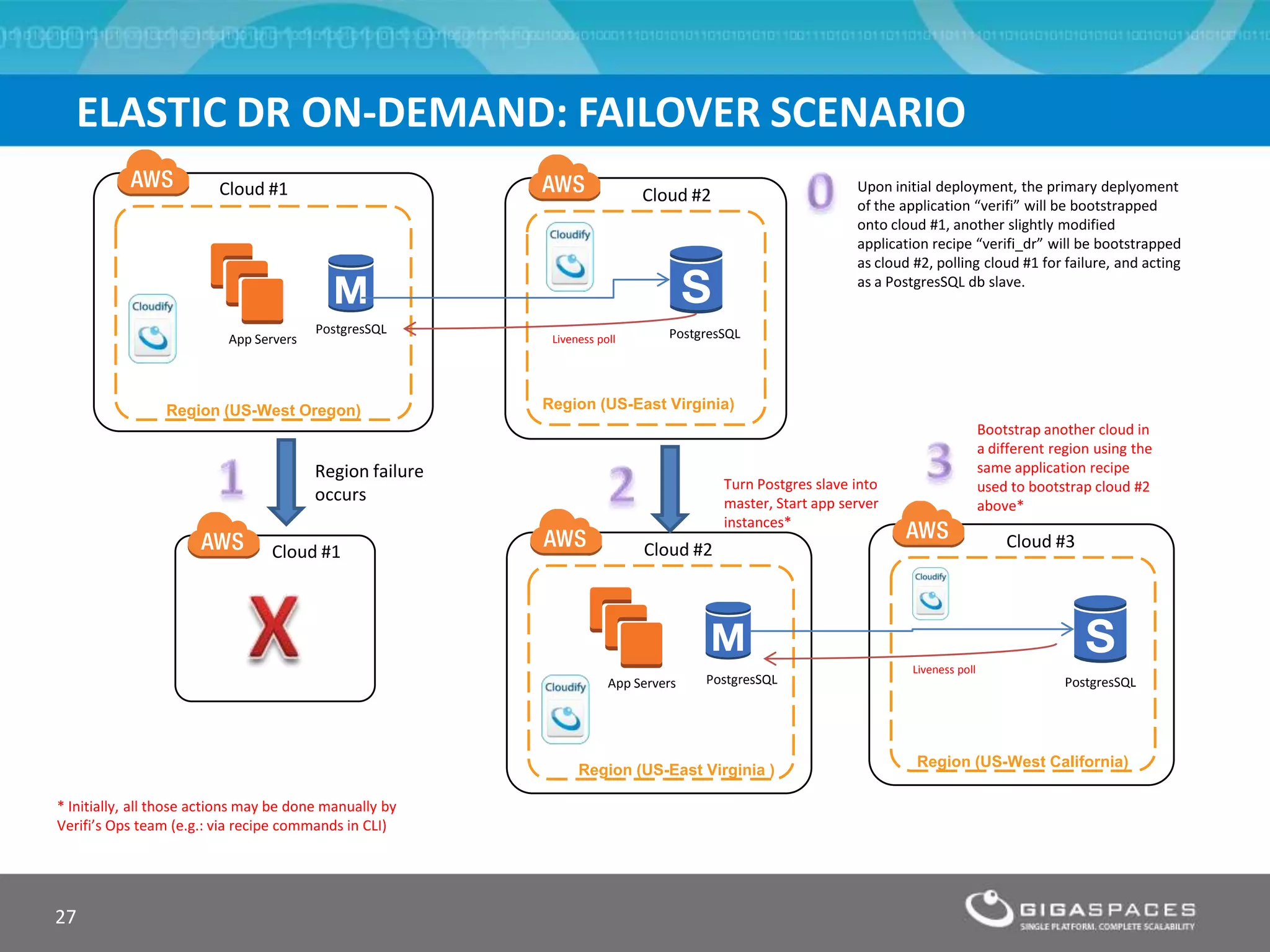
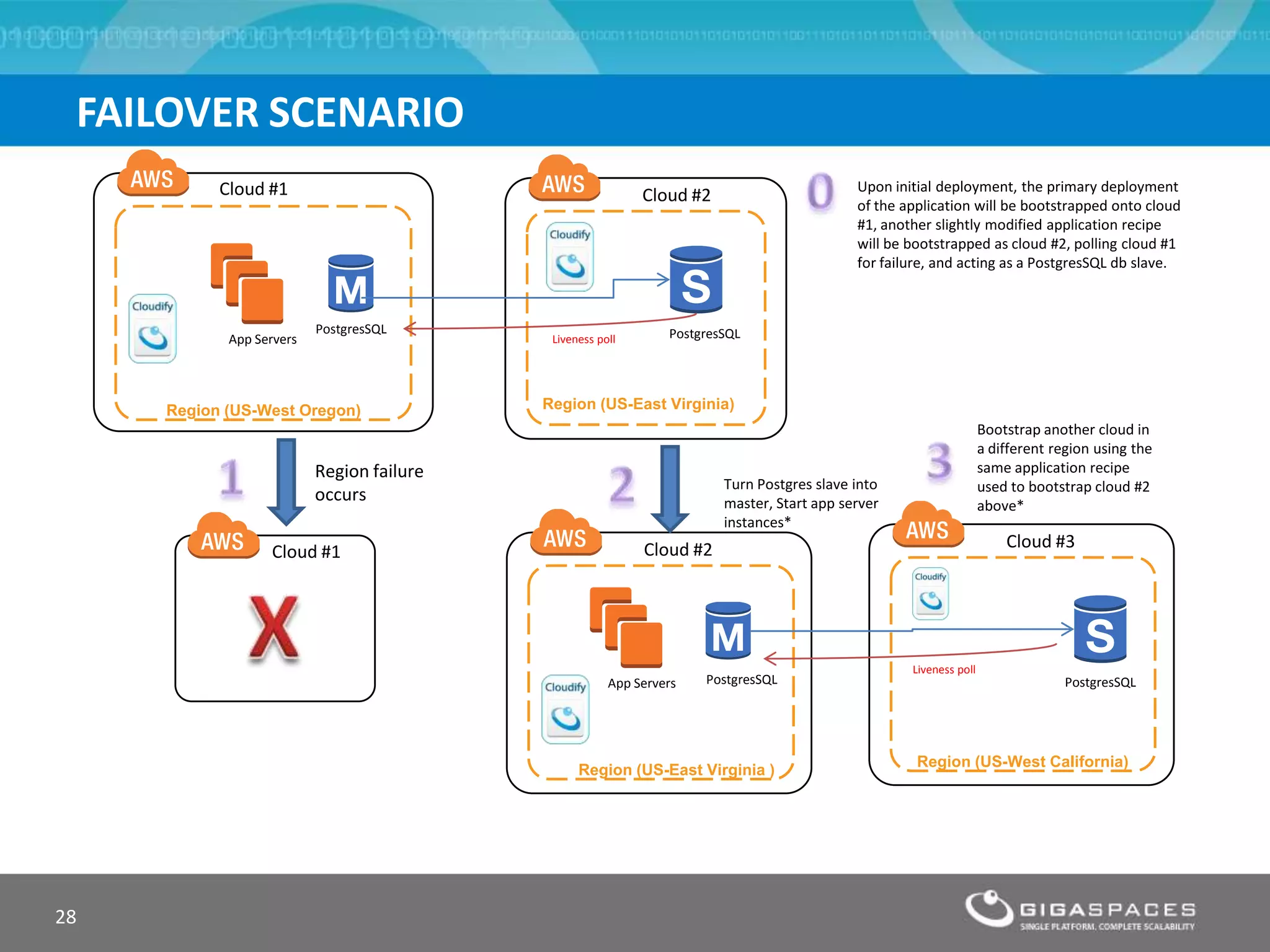
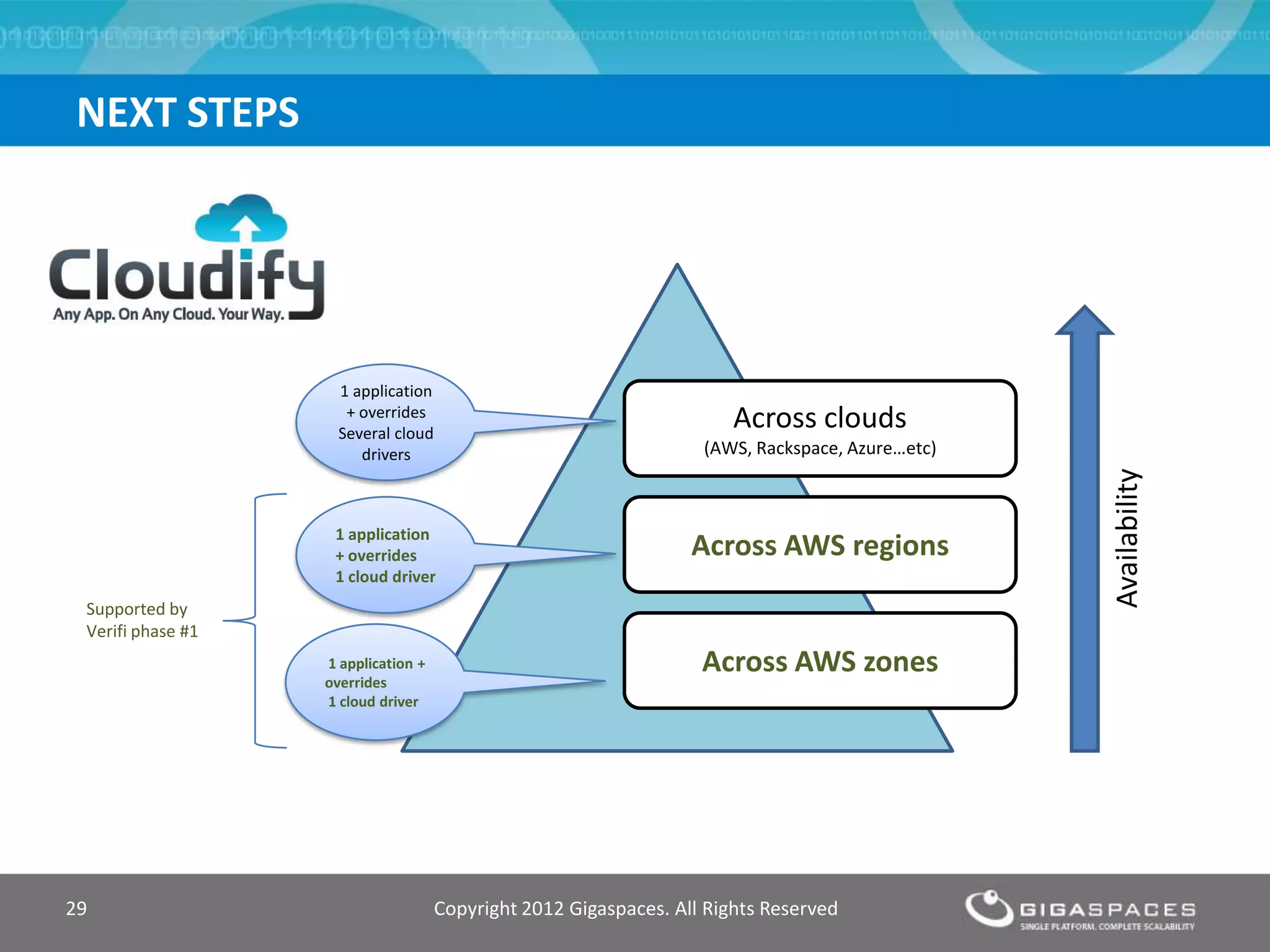
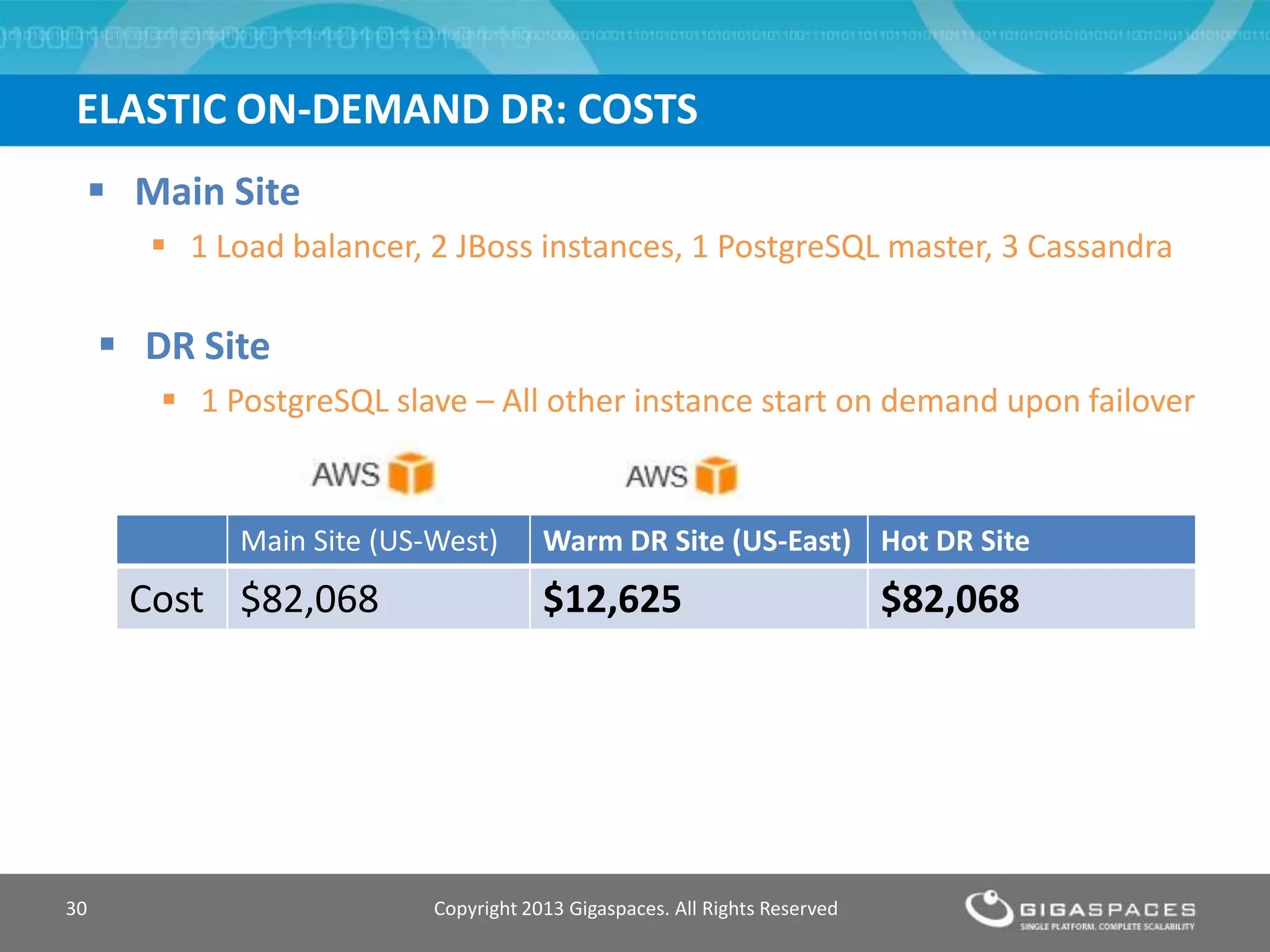
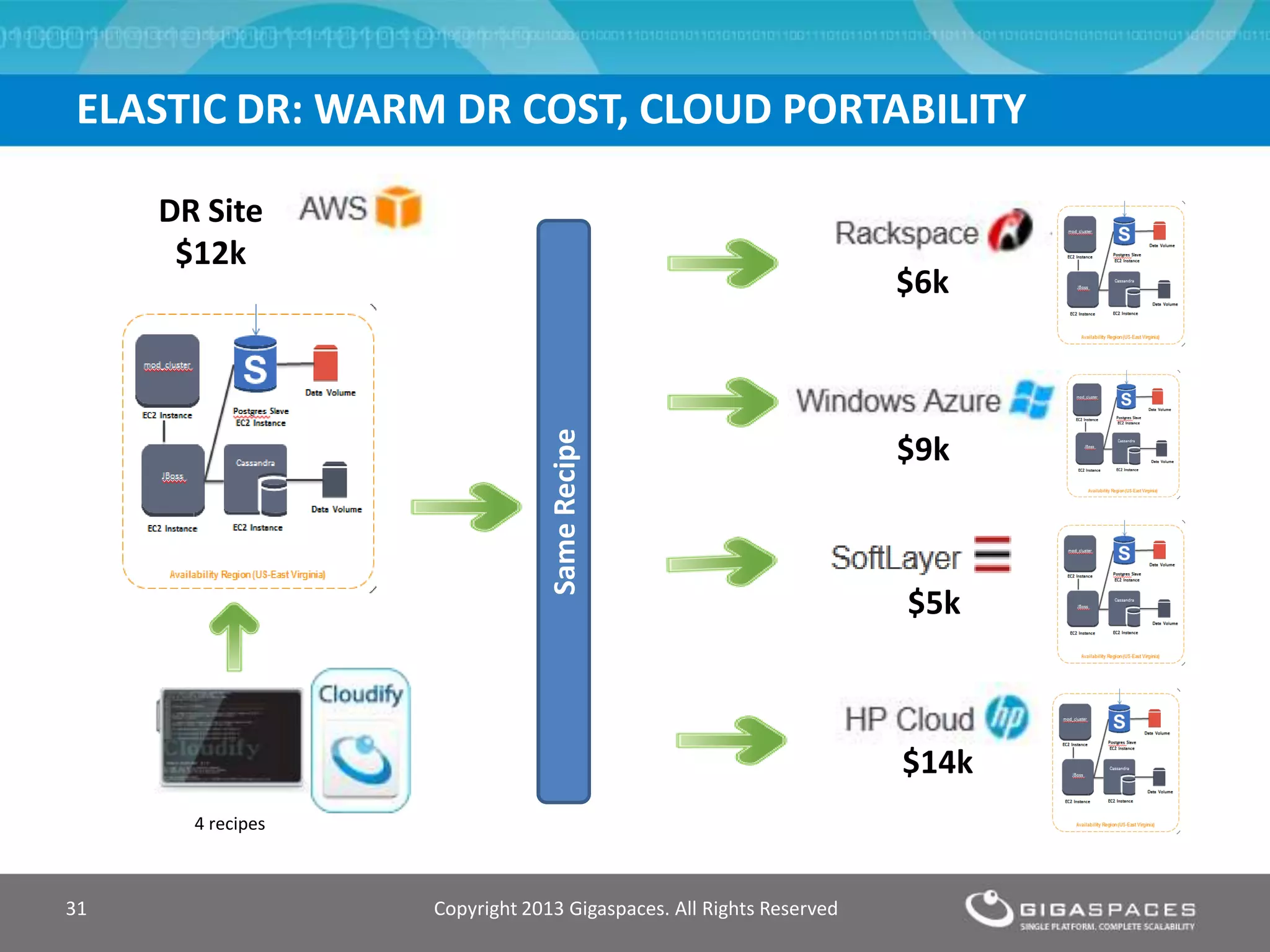
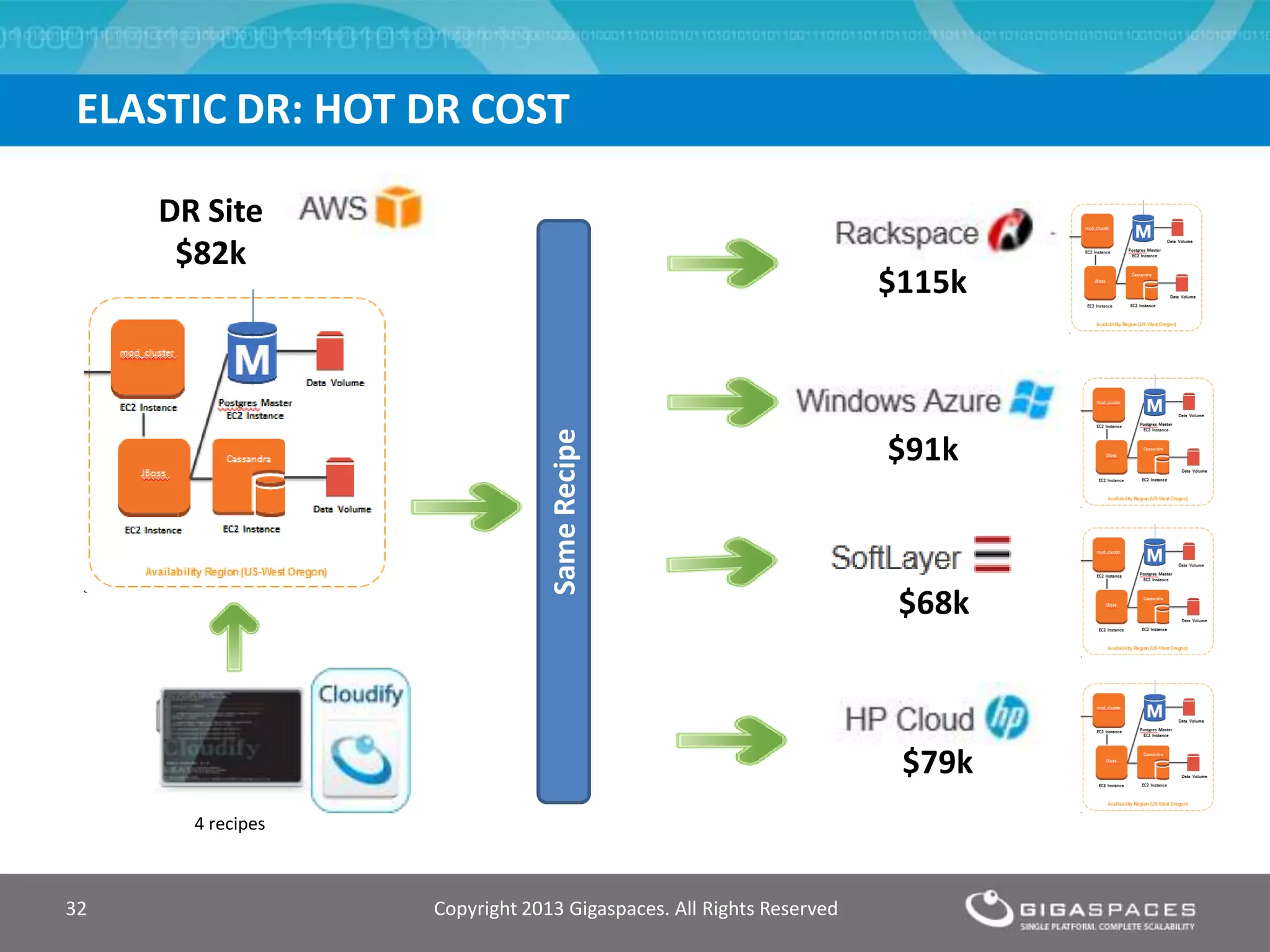



The document discusses outages on cloud platforms like AWS and strategies for disaster recovery. It notes that AWS has experienced several outages in 2011, 2012, and 2013, costing users millions per hour. To prepare for outages and enable fast disaster recovery, the document recommends having redundancy across multiple cloud regions and availability zones using automation and data replication. It presents a case study of a company that used the Cloudify platform to clone their application environment and database across different AWS regions, enabling failover between regions in seconds in the event of an outage. This approach significantly reduced recovery time objectives while keeping costs lower than maintaining a dedicated hot disaster recovery site.

















































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)















