Downloaded 281 times





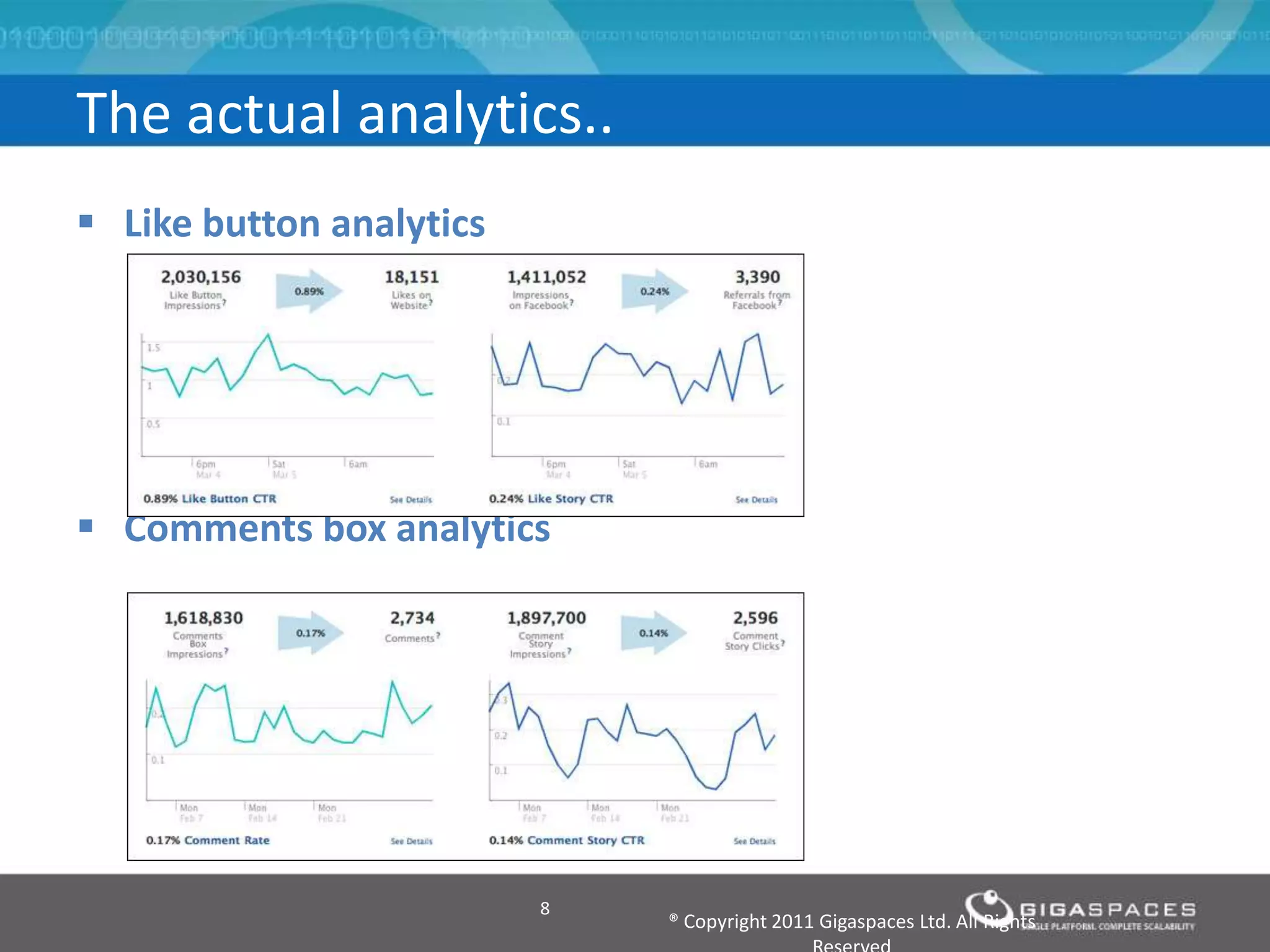
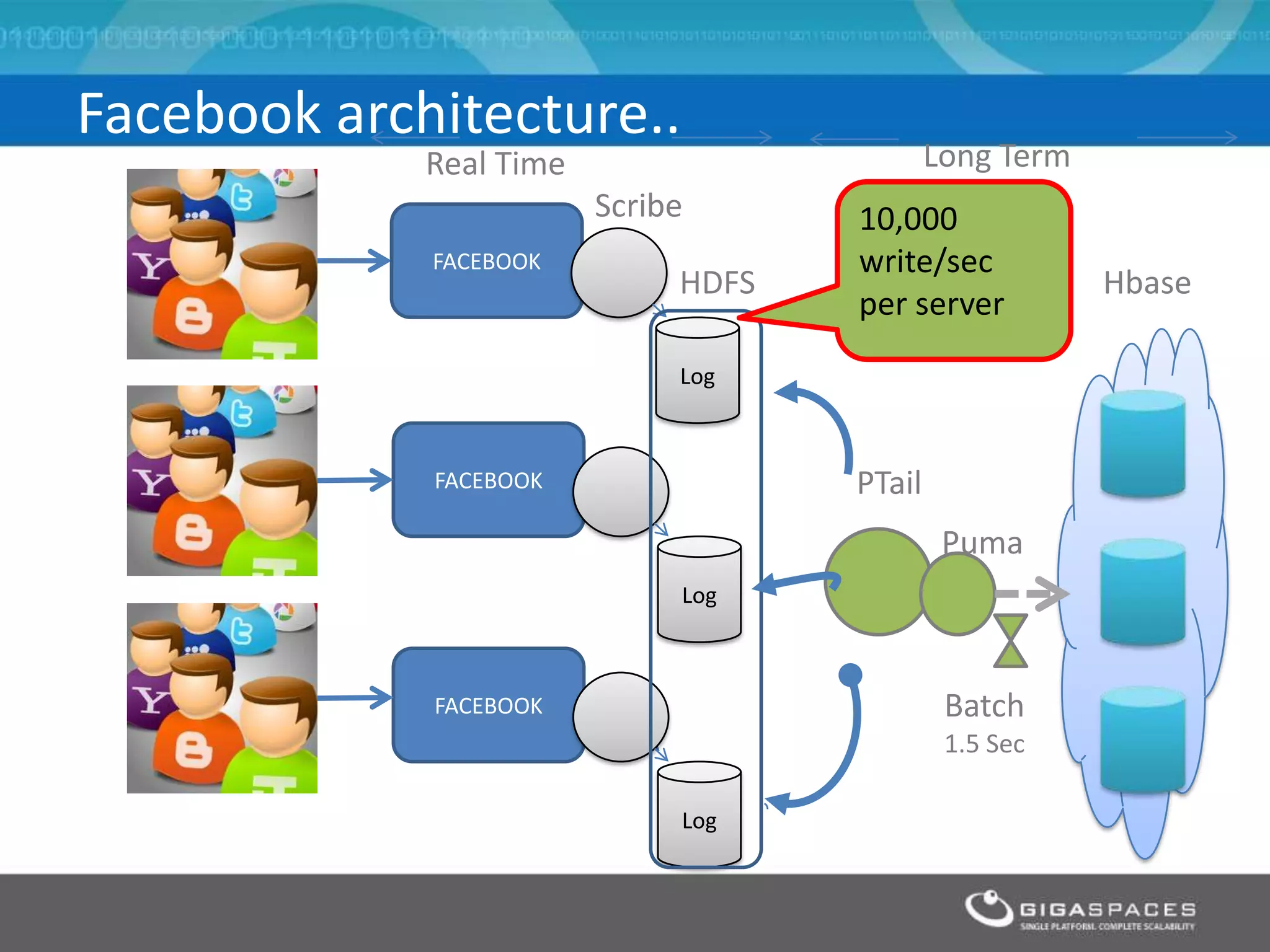

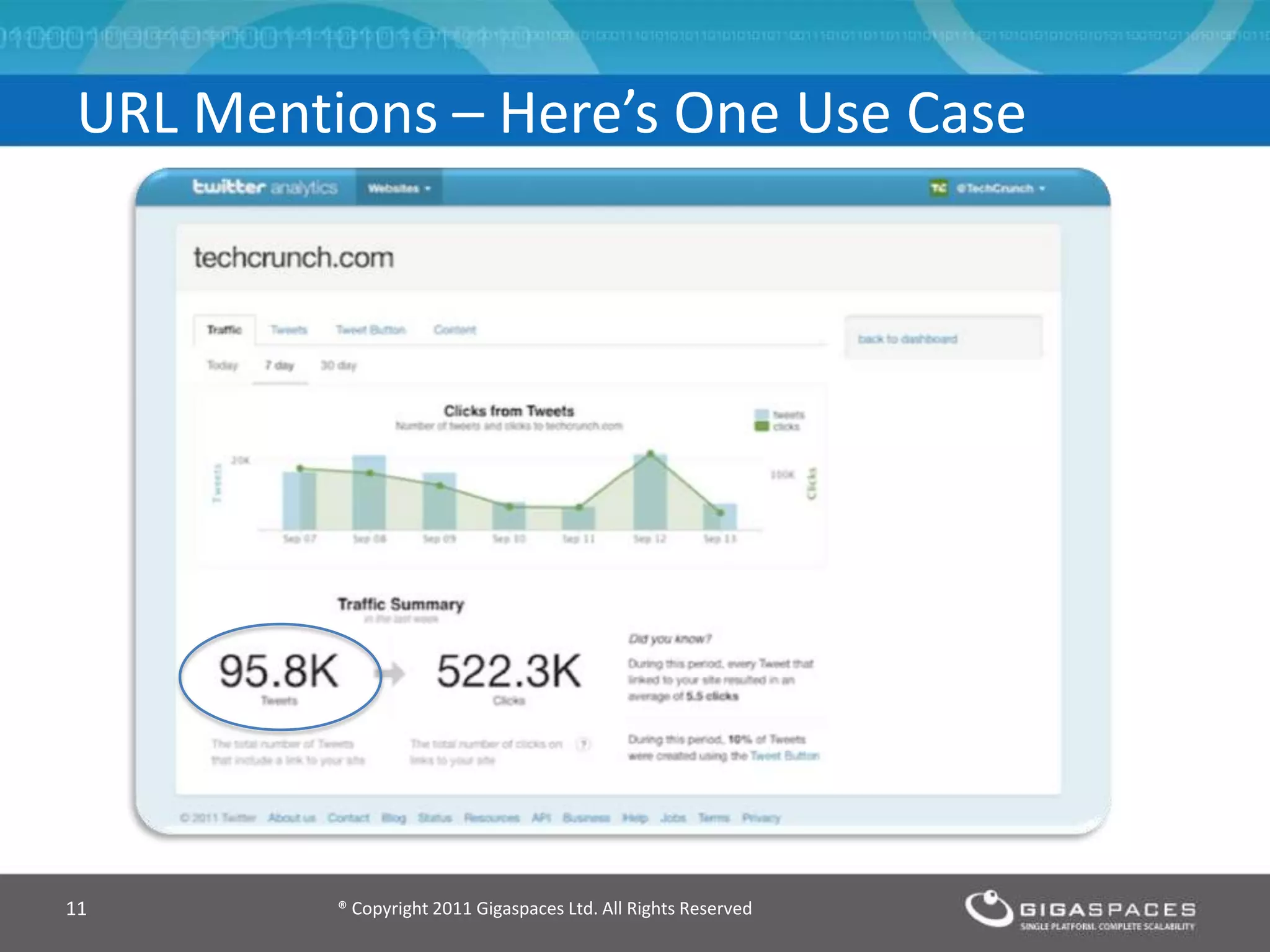
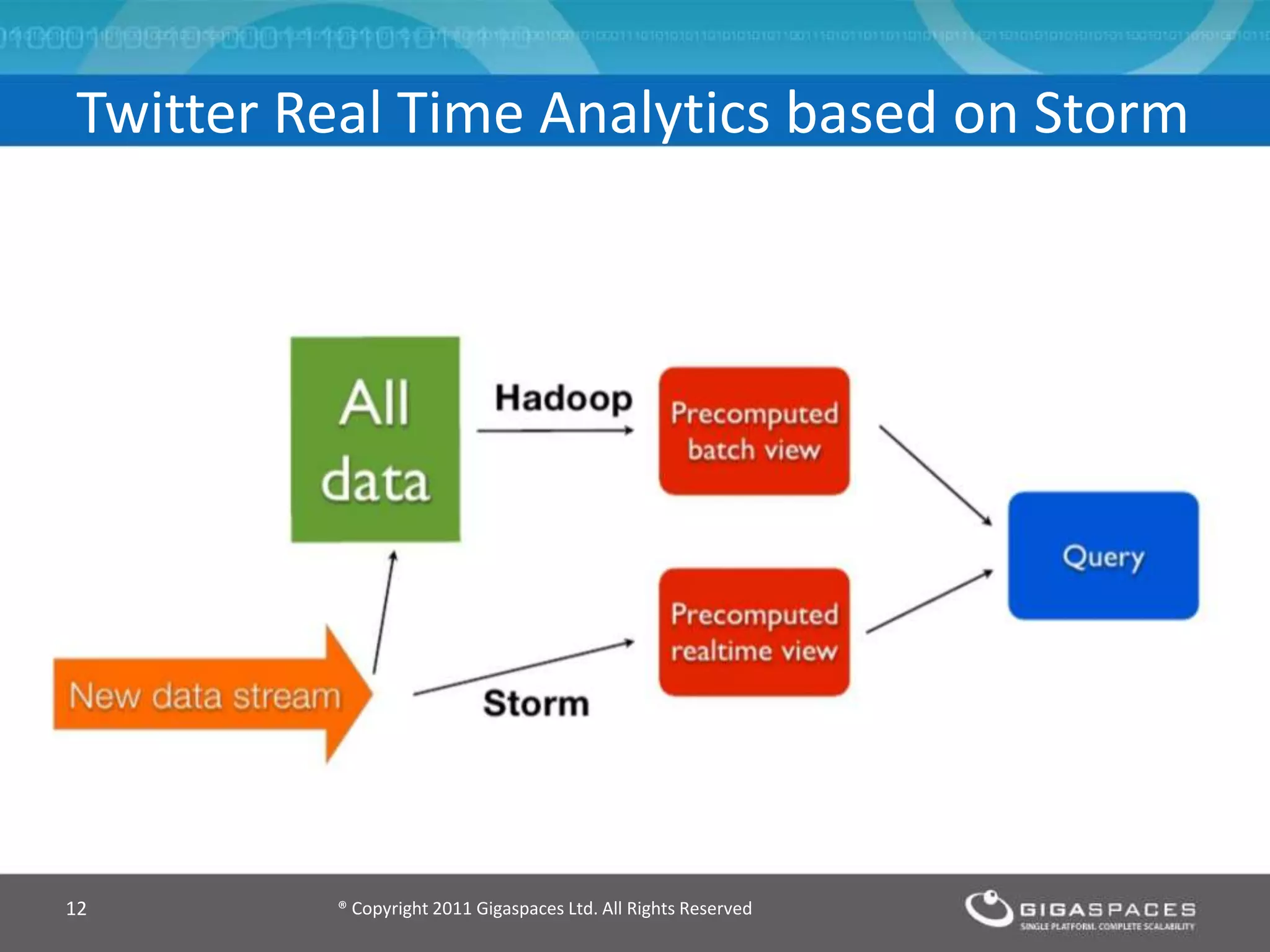


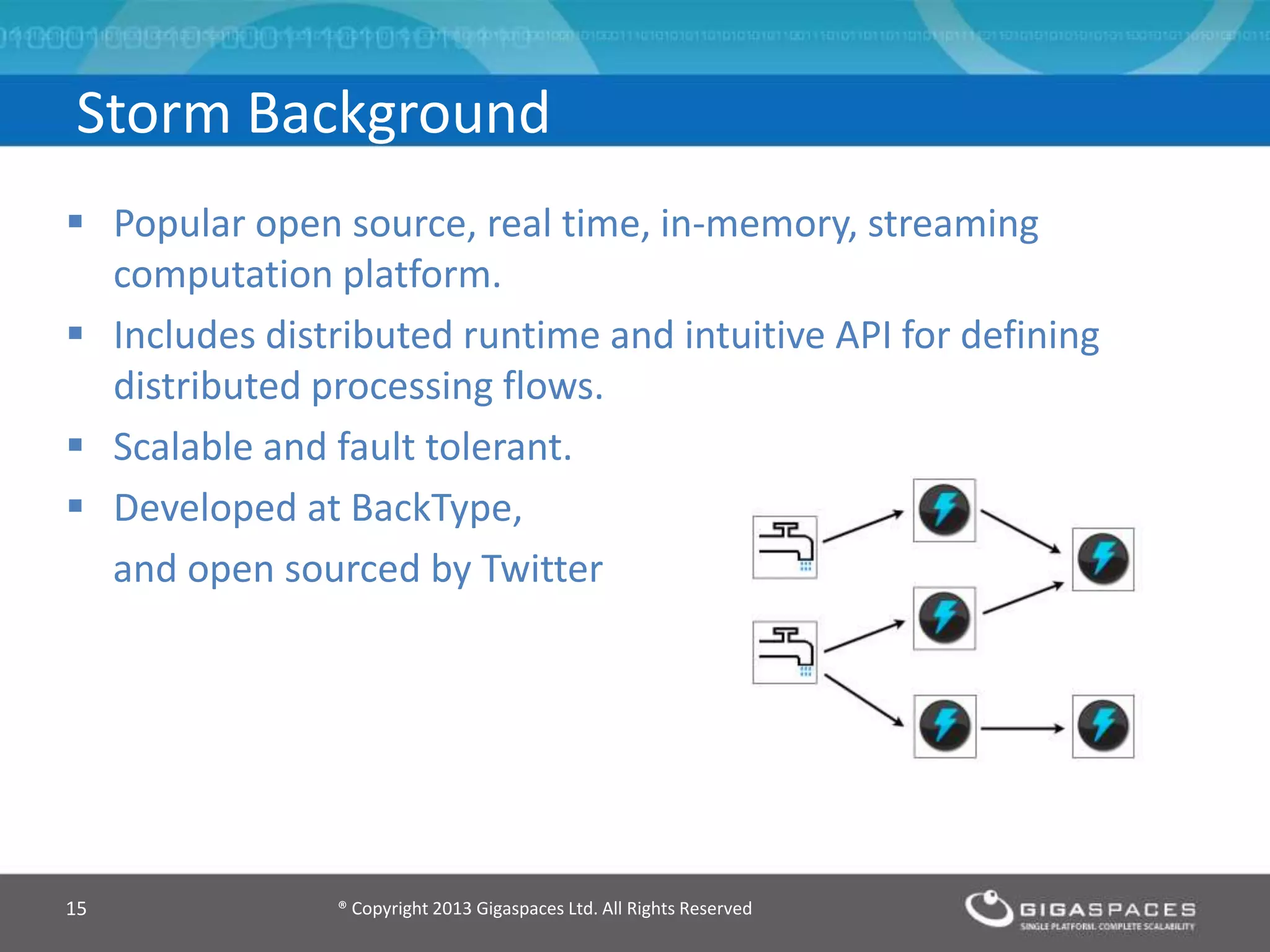
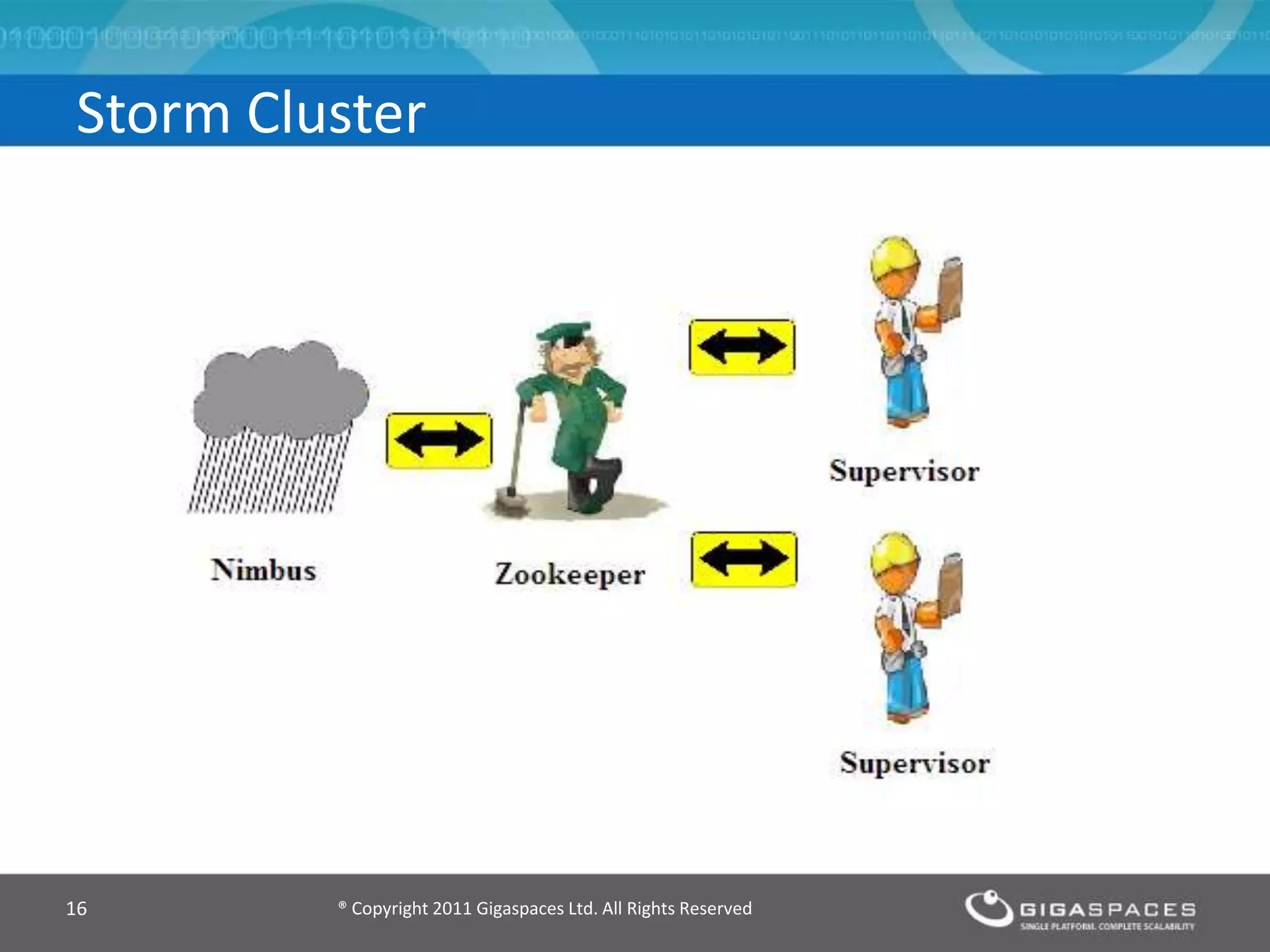
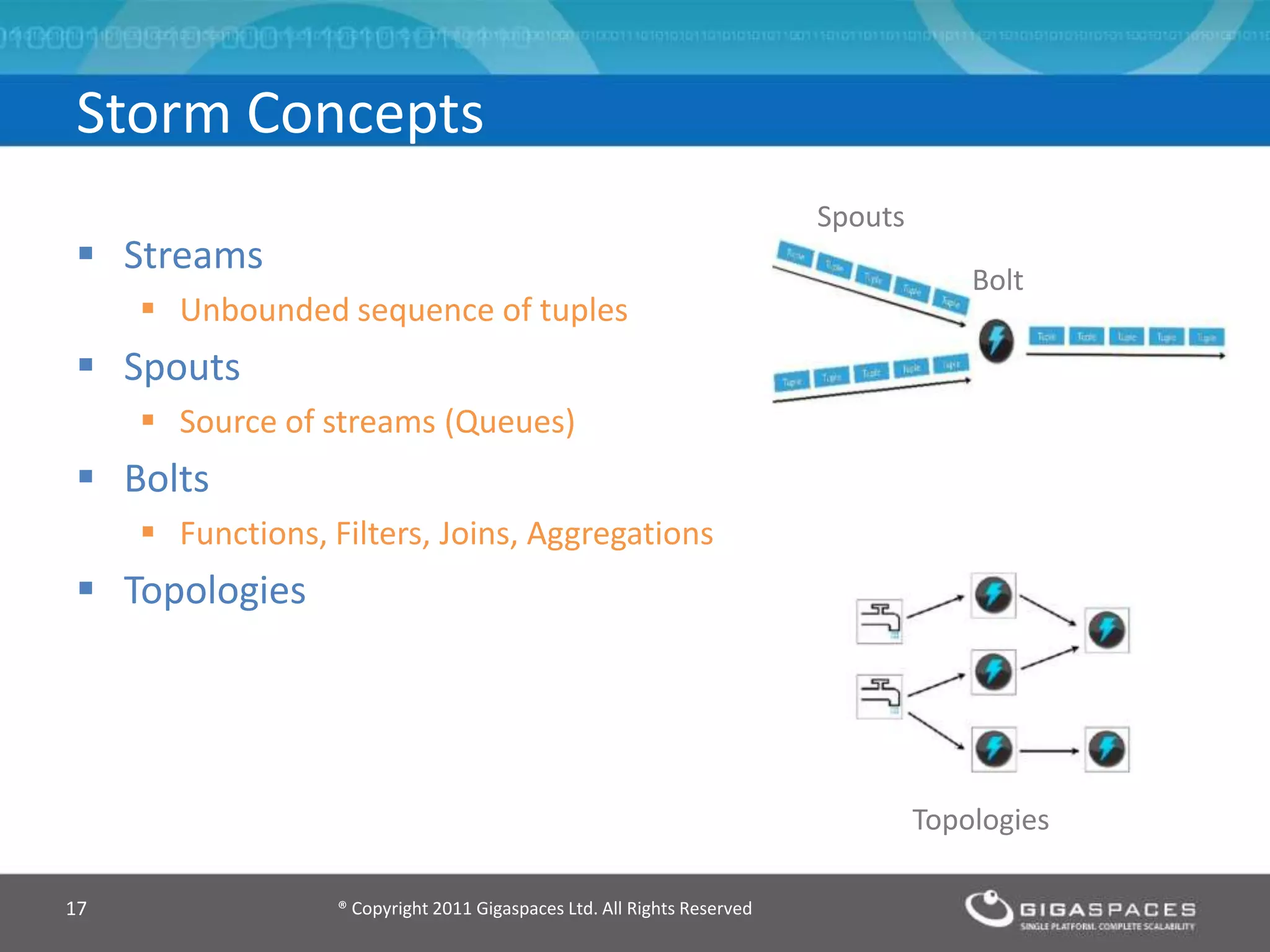
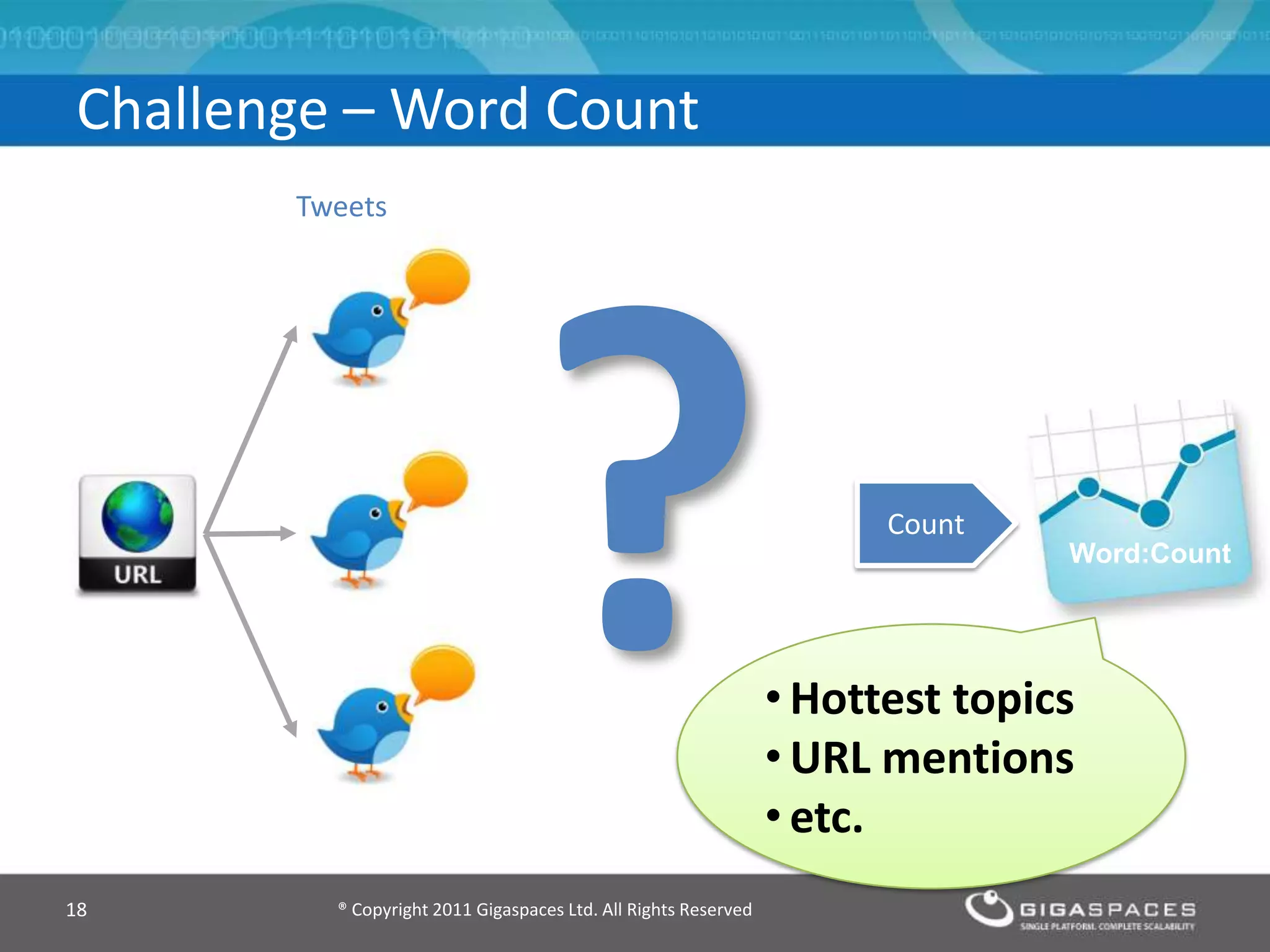

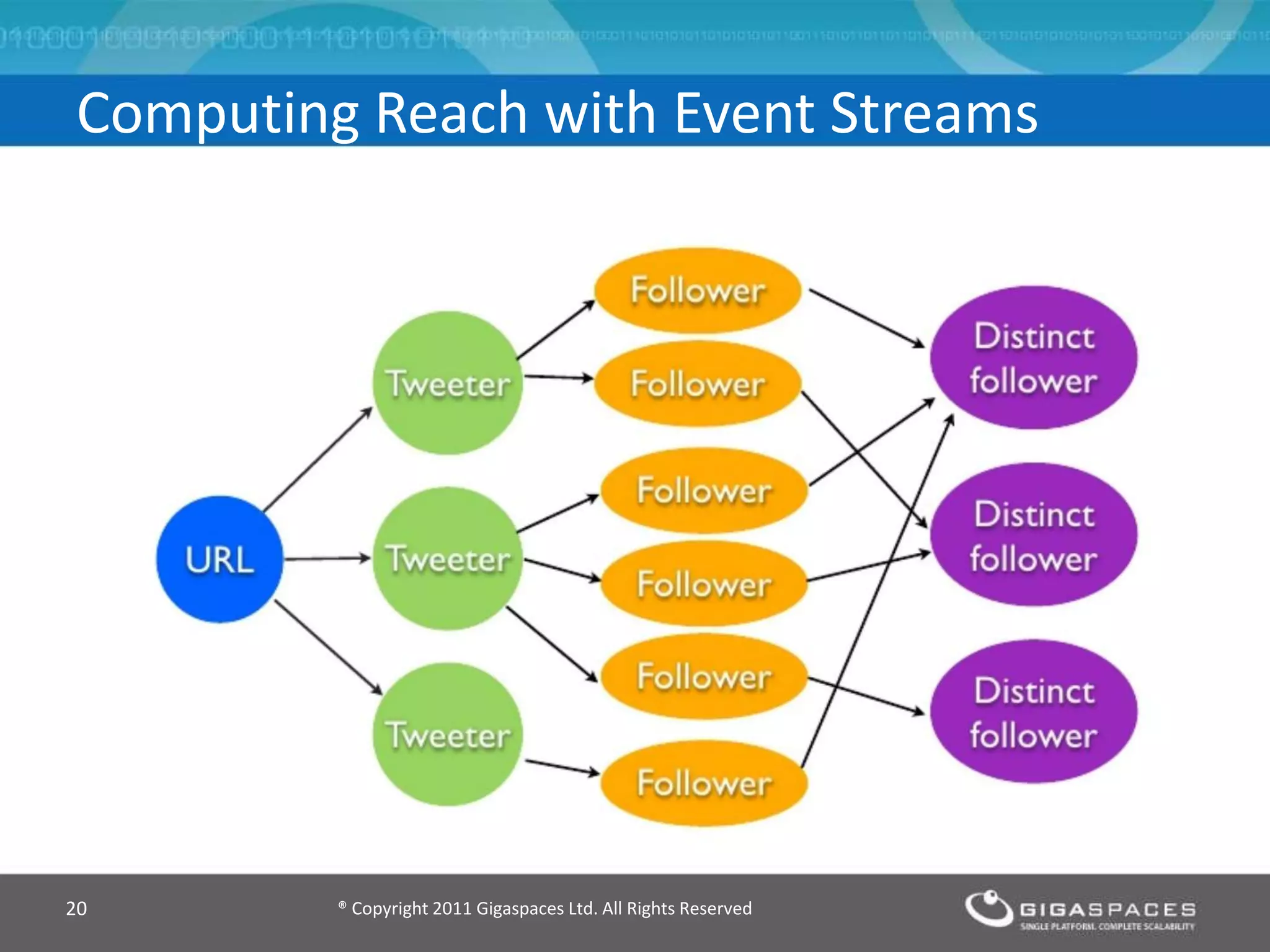

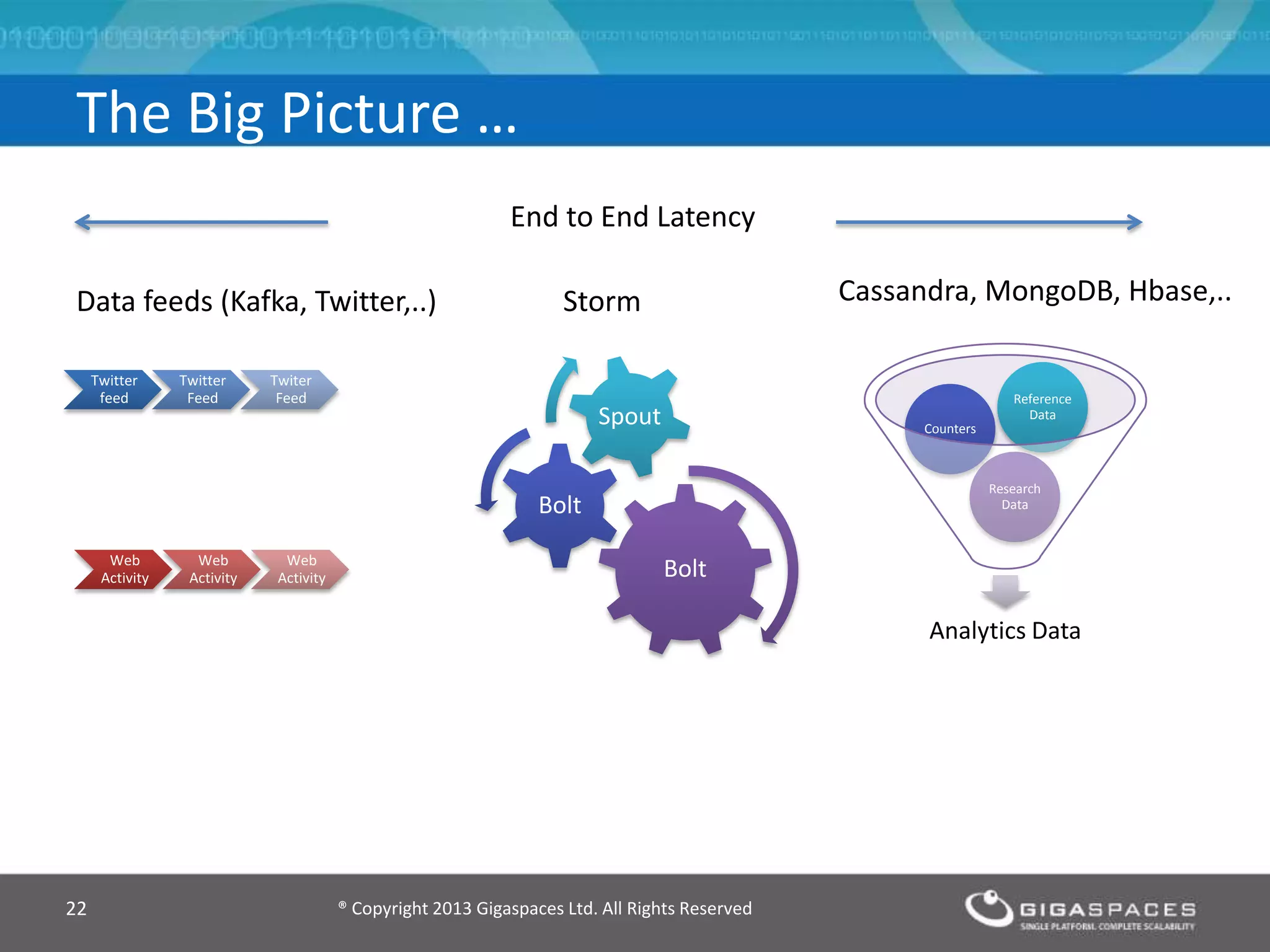



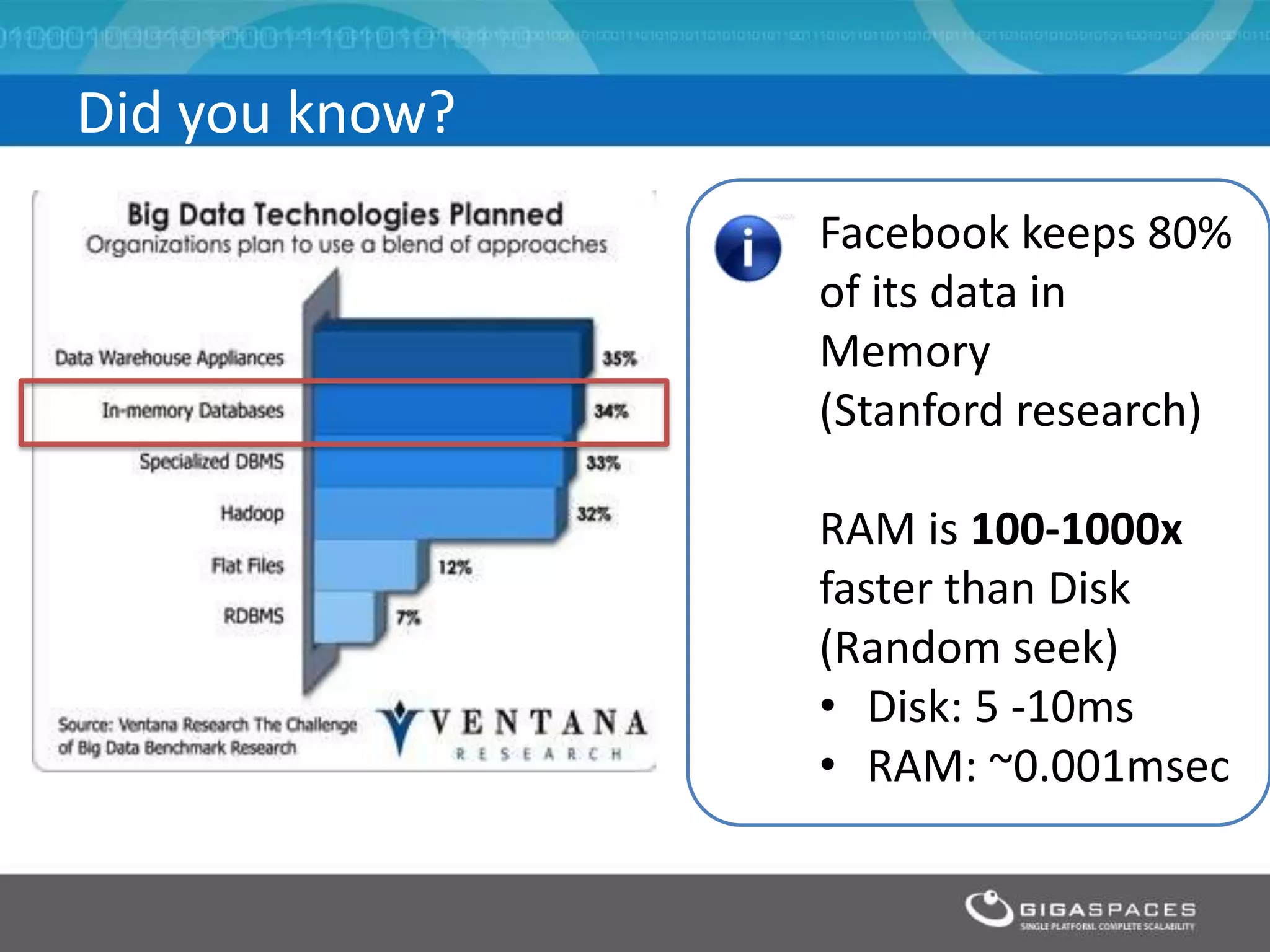
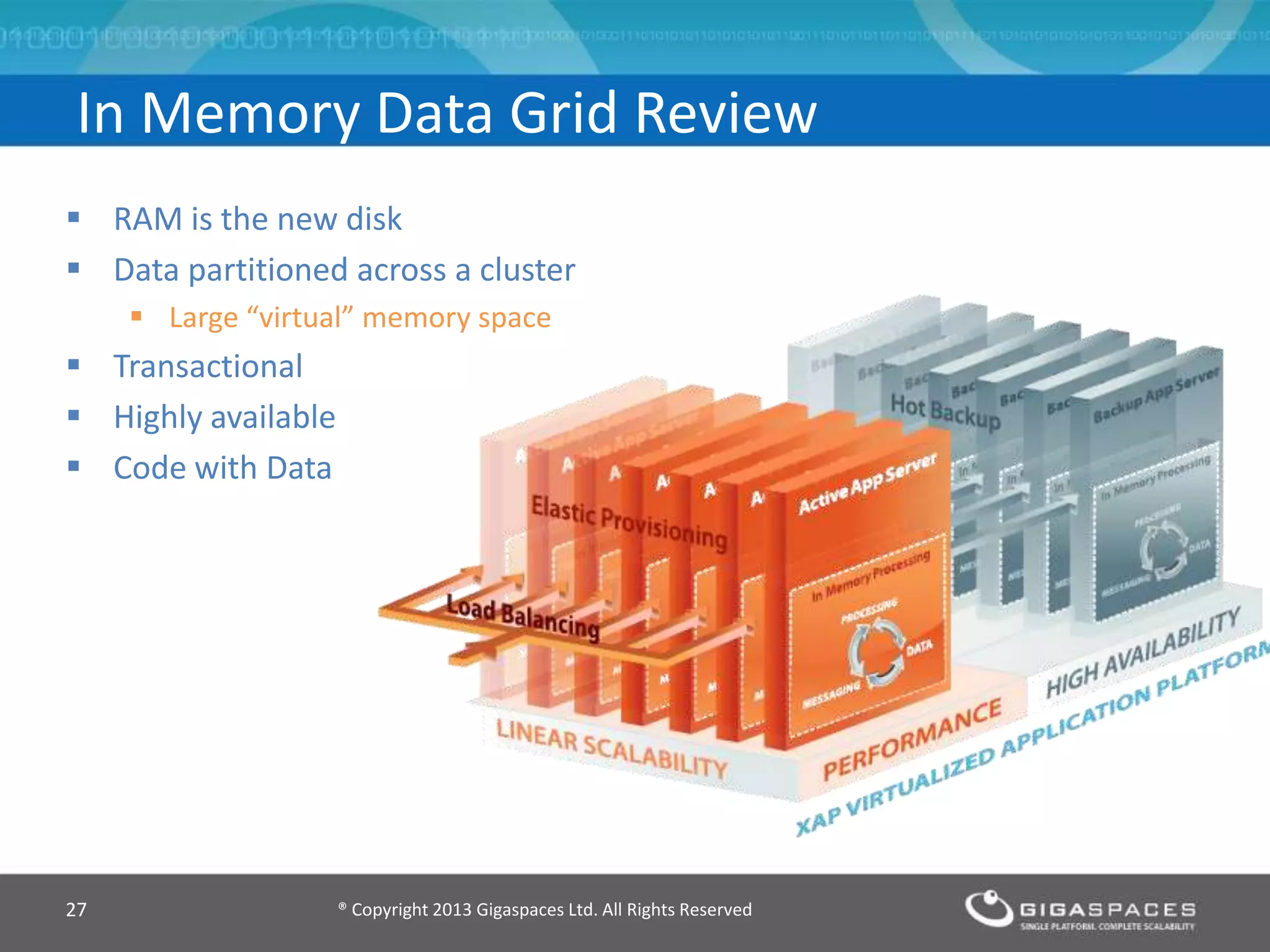
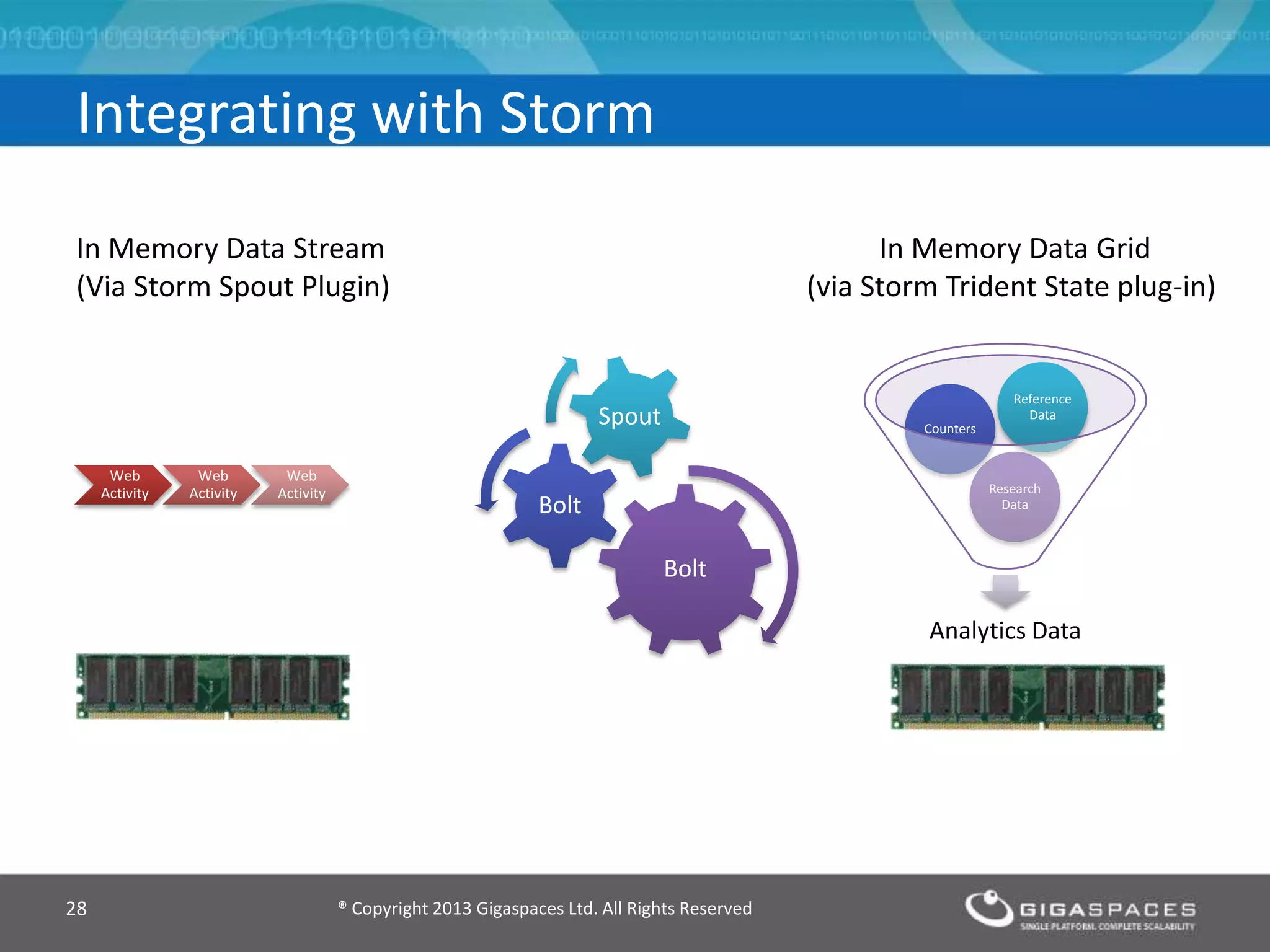
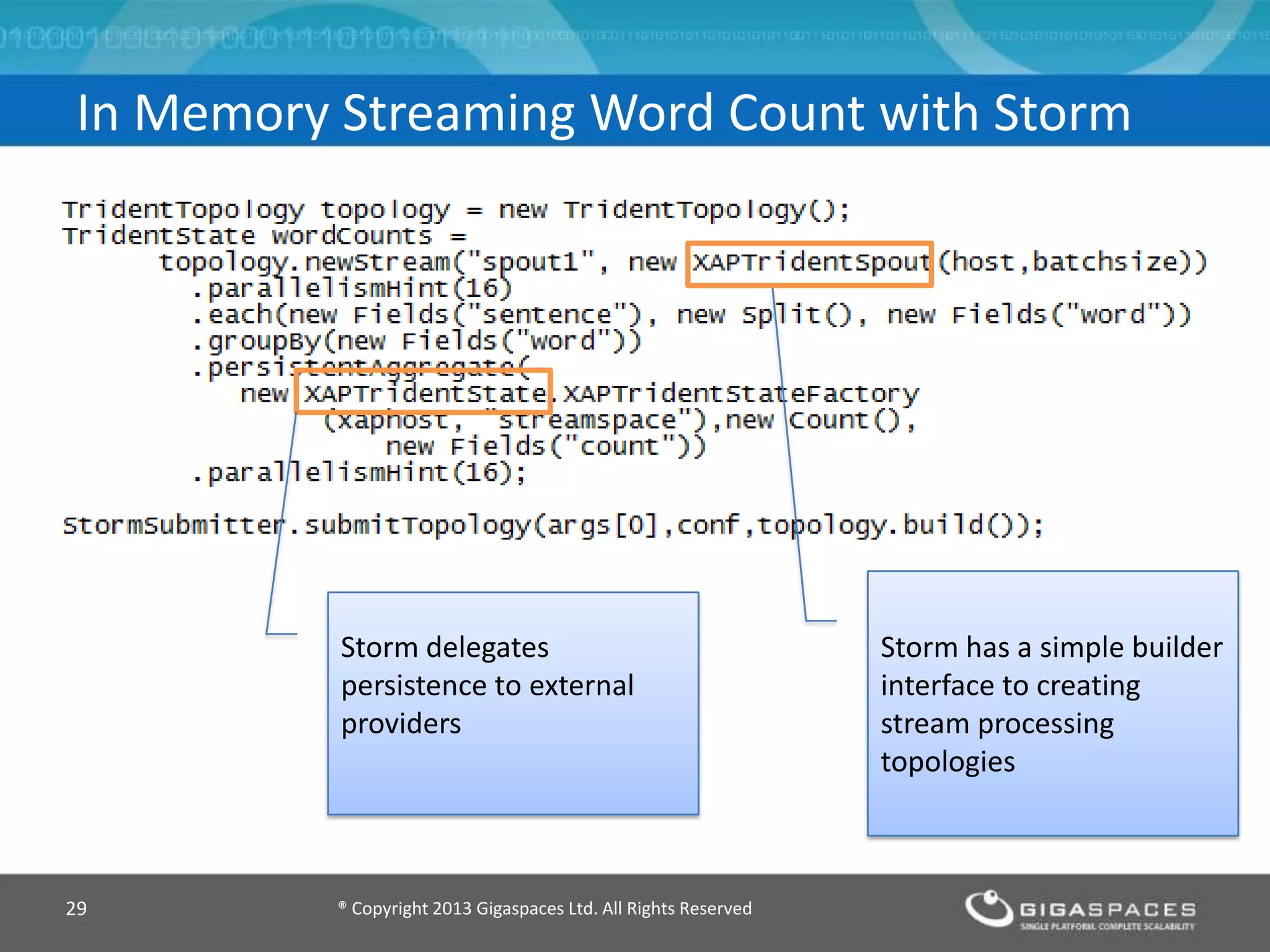
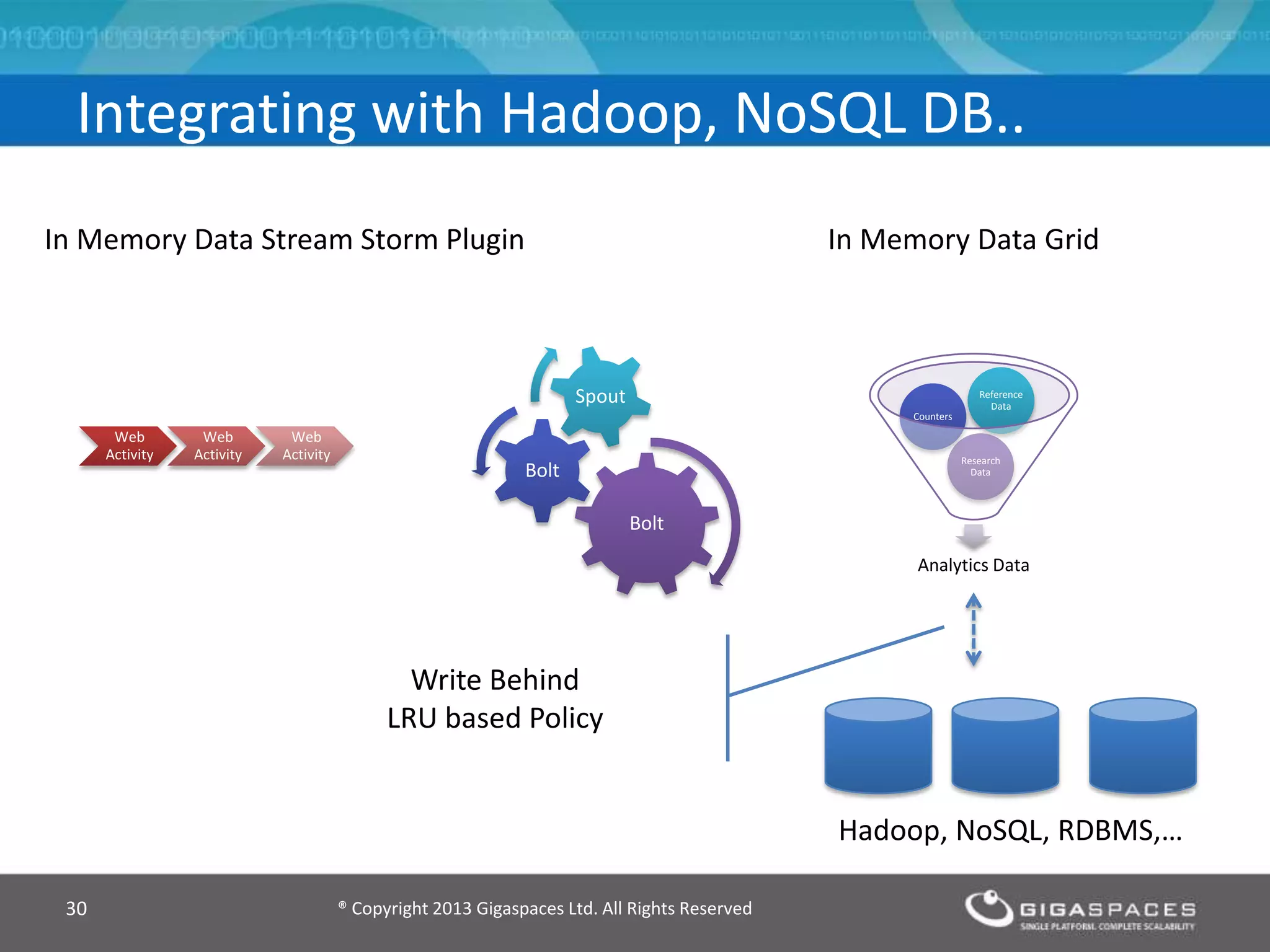
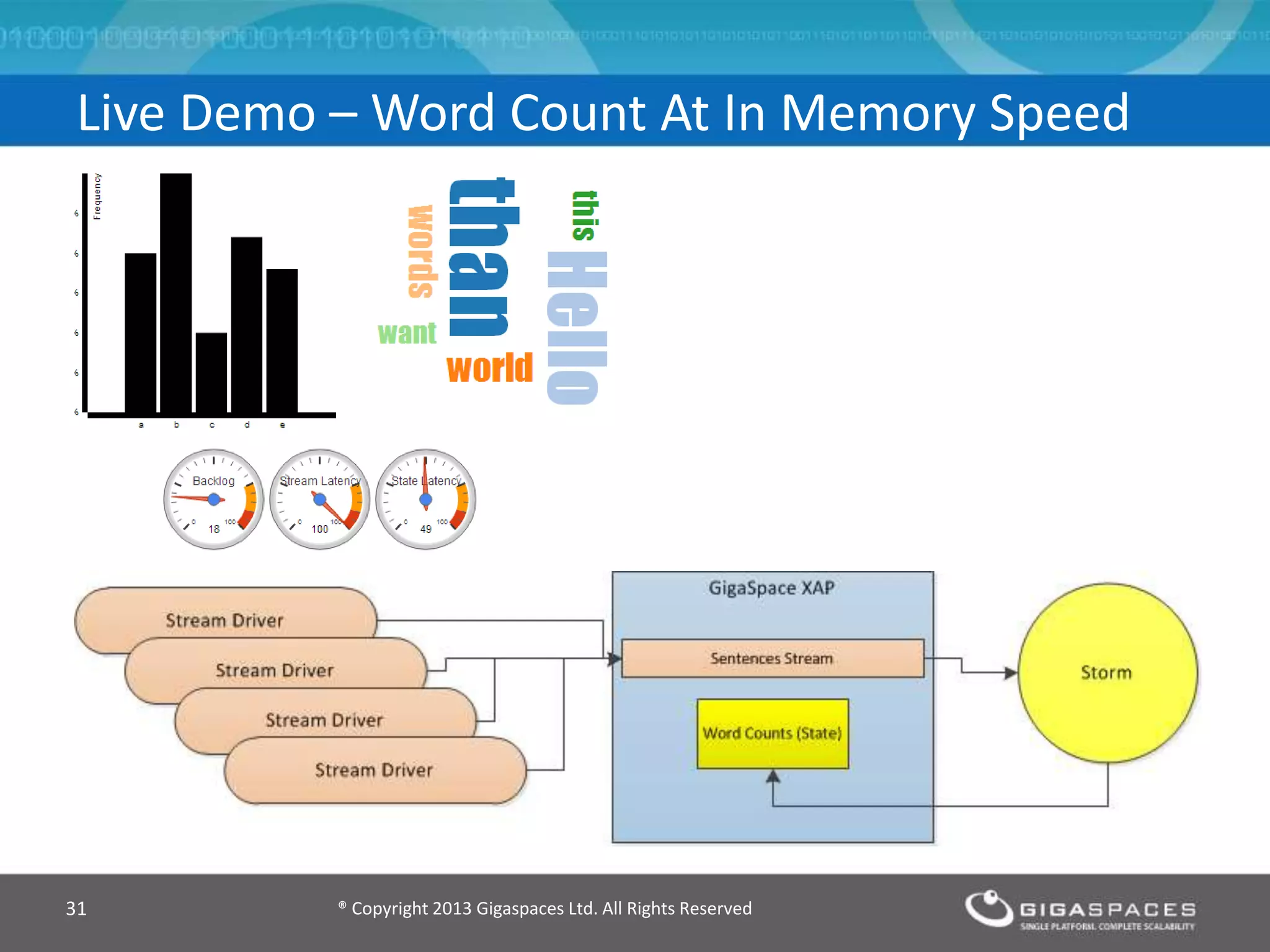
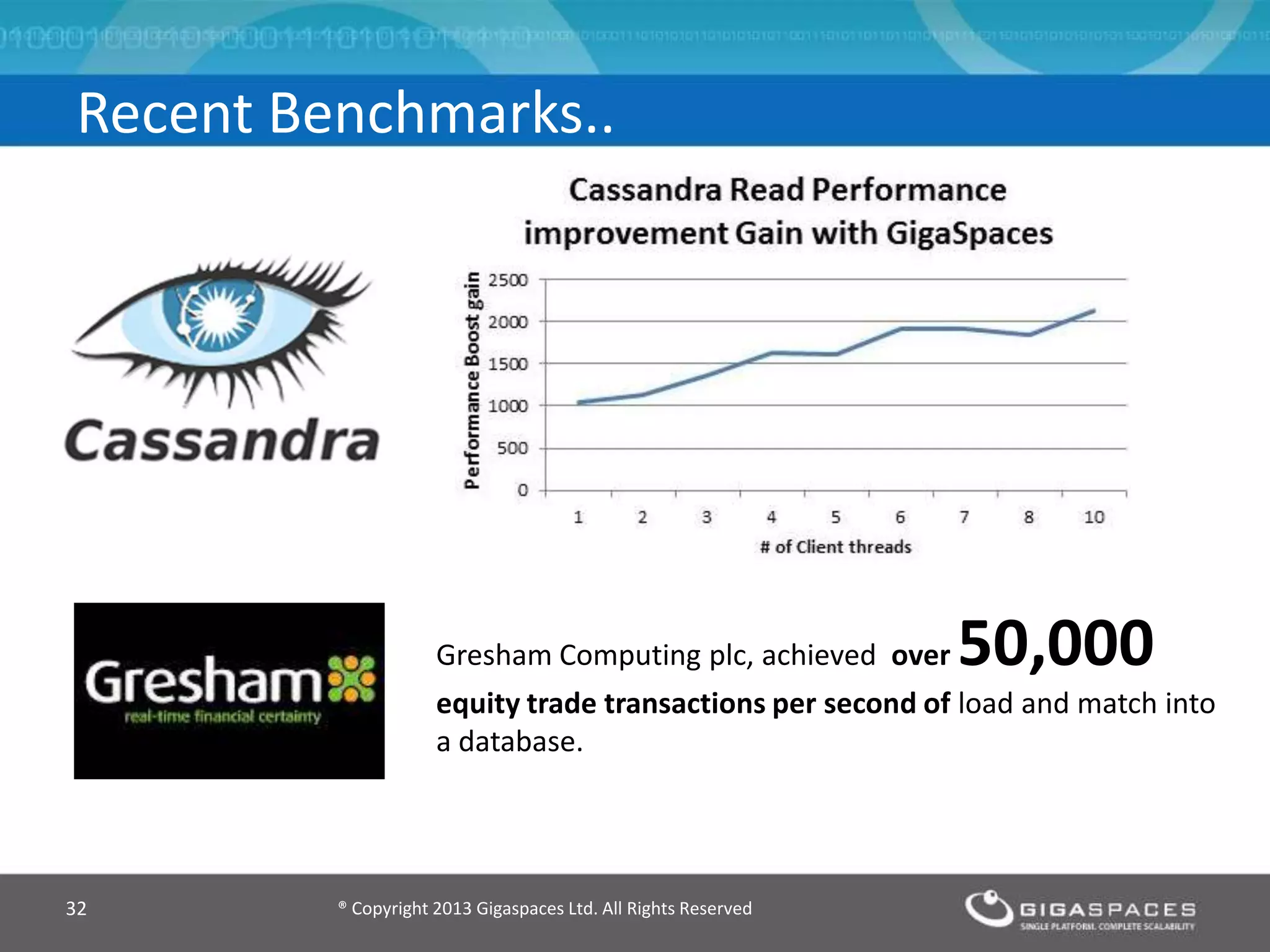



The document discusses real-time big data analytics using Storm, Cassandra, and in-memory computing, highlighting their applications in various fields such as social media and financial services. It contrasts the real-time analytics approaches of Facebook and Twitter, emphasizing Storm's capabilities for high-speed processing of streaming data. Additionally, it presents the advantages of in-memory data processing and explores the integration of Storm with various data sources and storage solutions.
























































































![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)





![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)












