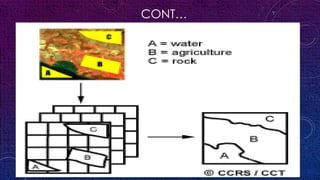
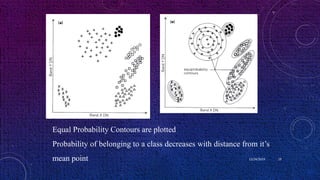
This document discusses image classification and analysis techniques. It describes supervised classification where an analyst identifies training areas to classify pixels based on spectral information. Unsupervised classification uses clustering algorithms to automatically group spectrally similar pixels without training areas. Common classification procedures include supervised classification using training areas, unsupervised classification using clustering, and hybrid methods. Maximum likelihood and minimum distance are described as supervised classification algorithms.