Downloaded 69 times





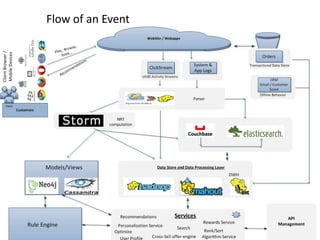









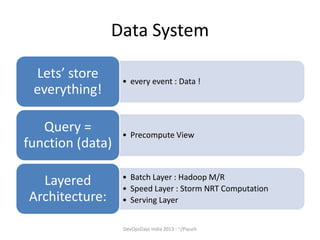
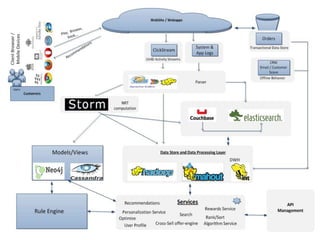





The document discusses the importance of centralized event collection and analysis using a big data platform. It describes the challenges faced by MakeMyTrip in analyzing huge amounts of data from various sources. Centralized logging of structured event data from all systems and applications is recommended to enable effective log analysis, troubleshooting, and personalizing the user experience. A data service platform is needed to integrate data from different sources and power real-time and batch processing for analytics and insights.
























![How does Riak compare to Cassandra? [Cassandra London User Group July 2011]](https://cdn.slidesharecdn.com/ss_thumbnails/cassandralondonugjuly2011-110720110309-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





















































