




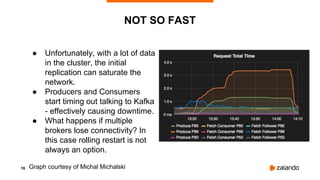
![14
What about if a Kafka broker cannot properly communicate with
ZooKeeper?
WHAT WENT WRONG?
This happened sometimes when our broker temporarily partitioned and
reconnected with ZooKeeper.
Broker would end up caching an old zkVersion. This would then prevent
ISR-modifying operations from completing.
Good news though, this bug should be resolved from 1.1.0 on!
[KAFKA-2729]](https://image.slidesharecdn.com/zalandoninahanzlikovakafkasummitfinal-180429220500/85/War-Stories-DIY-Kafka-14-320.jpg)







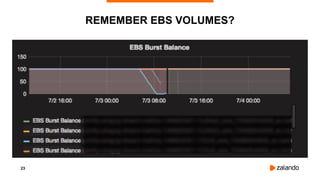














Zalando, Europe's largest online fashion retailer, utilizes Apache Kafka for data-driven insights and operations, emphasizing technological autonomy among its teams. The document outlines challenges faced in Kafka implementation, including data loss and connectivity issues with Zookeeper, as well as strategies for effective monitoring and backup solutions. Key improvements discussed include avoiding reliance on simple broker replication for persistence and utilizing frameworks like Kafka Connect and Burry for efficient data management and backups.