Download as PDF, PPTX













![Mainframe Integra?on, Offloading and Replacement with Apache KaAa – @KaiWaehner - www.kai-waehner.de
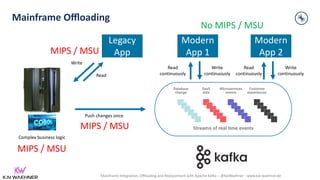
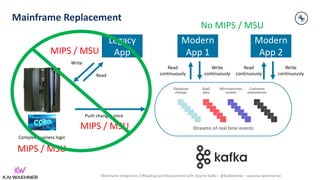
https://www.confluent.io/customers/rbc/
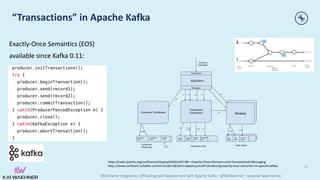
“… rescue data off of the mainframe, in a cloud native, microservice-
based fashion … [to] … significantly reduce the reads on the mainframe,
saving RBC fixed infrastructure costs (OPEX). RBC stayed compliant with
bank regulations and business logic, and is now able to create new
applications using the same event-based architecture.”](https://image.slidesharecdn.com/kaiwaehner-210927180016/85/Mainframe-Integration-Offloading-and-Replacement-with-Apache-Kafka-Kai-Waehner-Confluent-14-320.jpg)





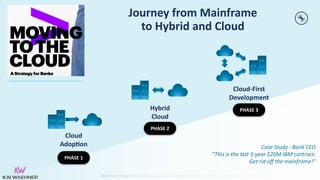
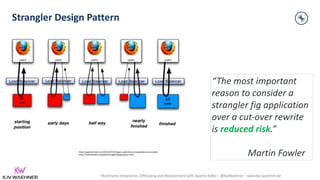
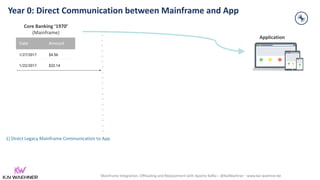
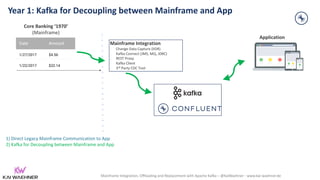
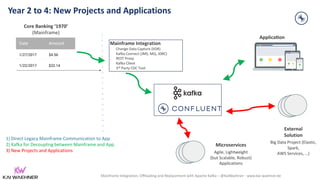
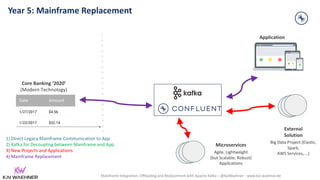



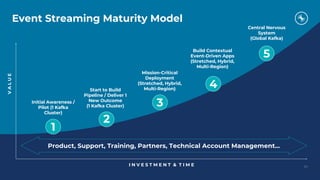
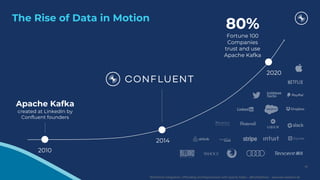
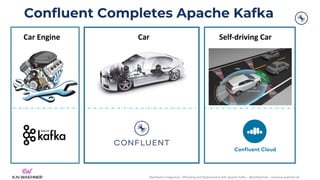



The document discusses the integration, offloading, and replacement of mainframe systems using Apache Kafka, emphasizing the challenges and use cases for its implementation in financial services. It highlights how modern organizations depend on mainframes while advocating for a transition to cloud-native and hybrid infrastructure to enhance flexibility and efficiency. Key topics include disaster recovery strategies, data in motion, and various integration options between mainframes and modern applications.