Downloaded 20 times






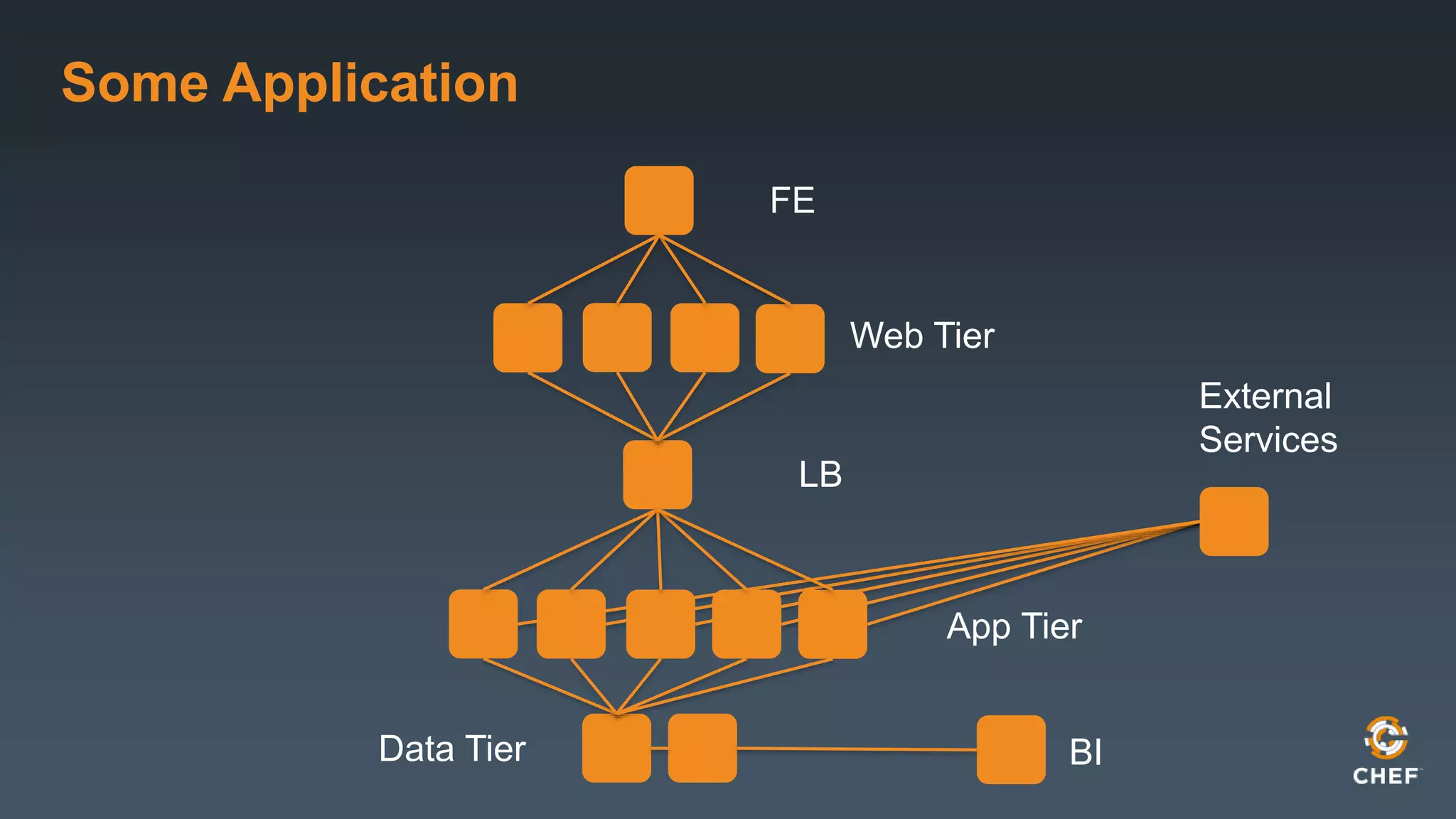


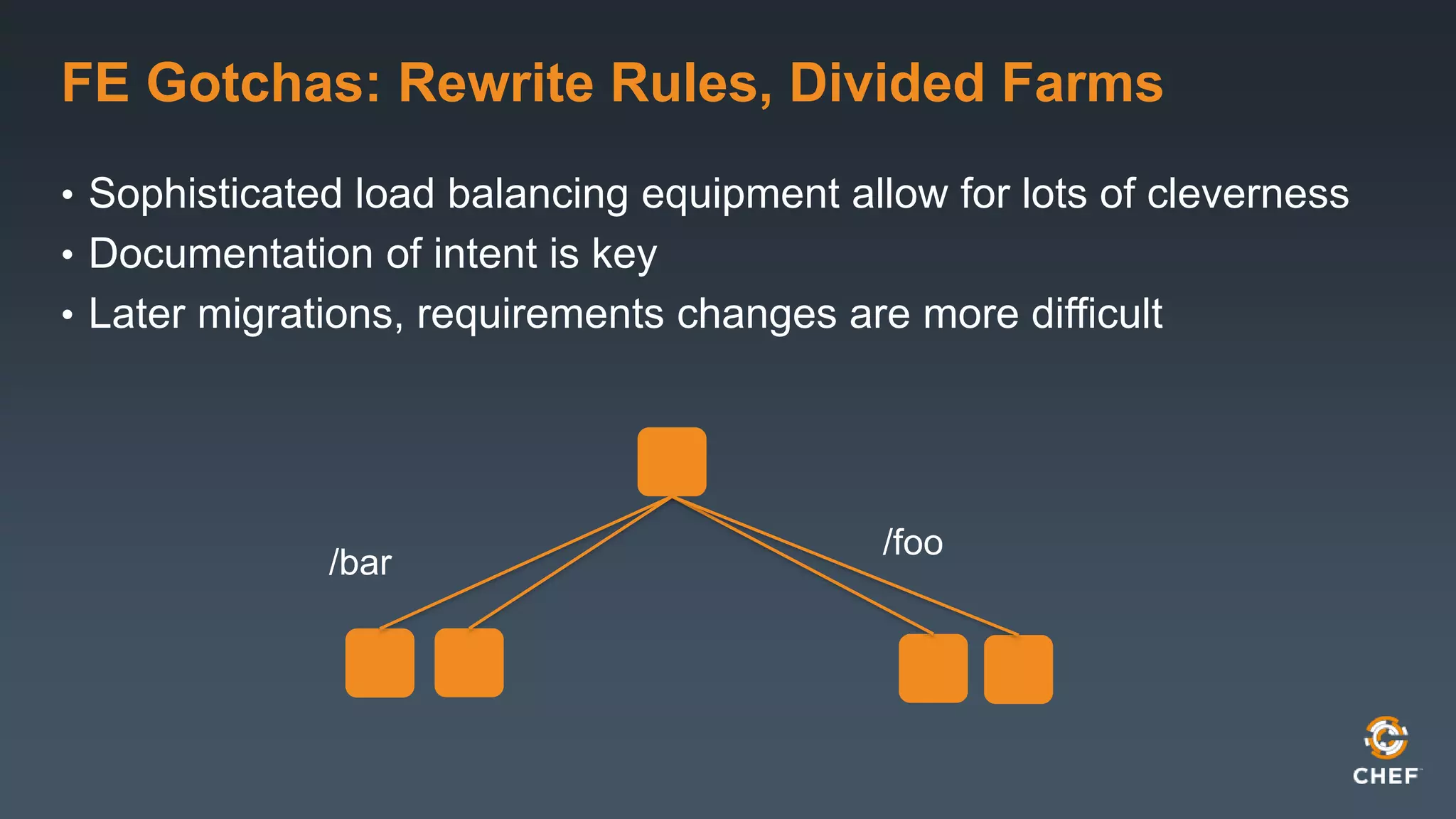













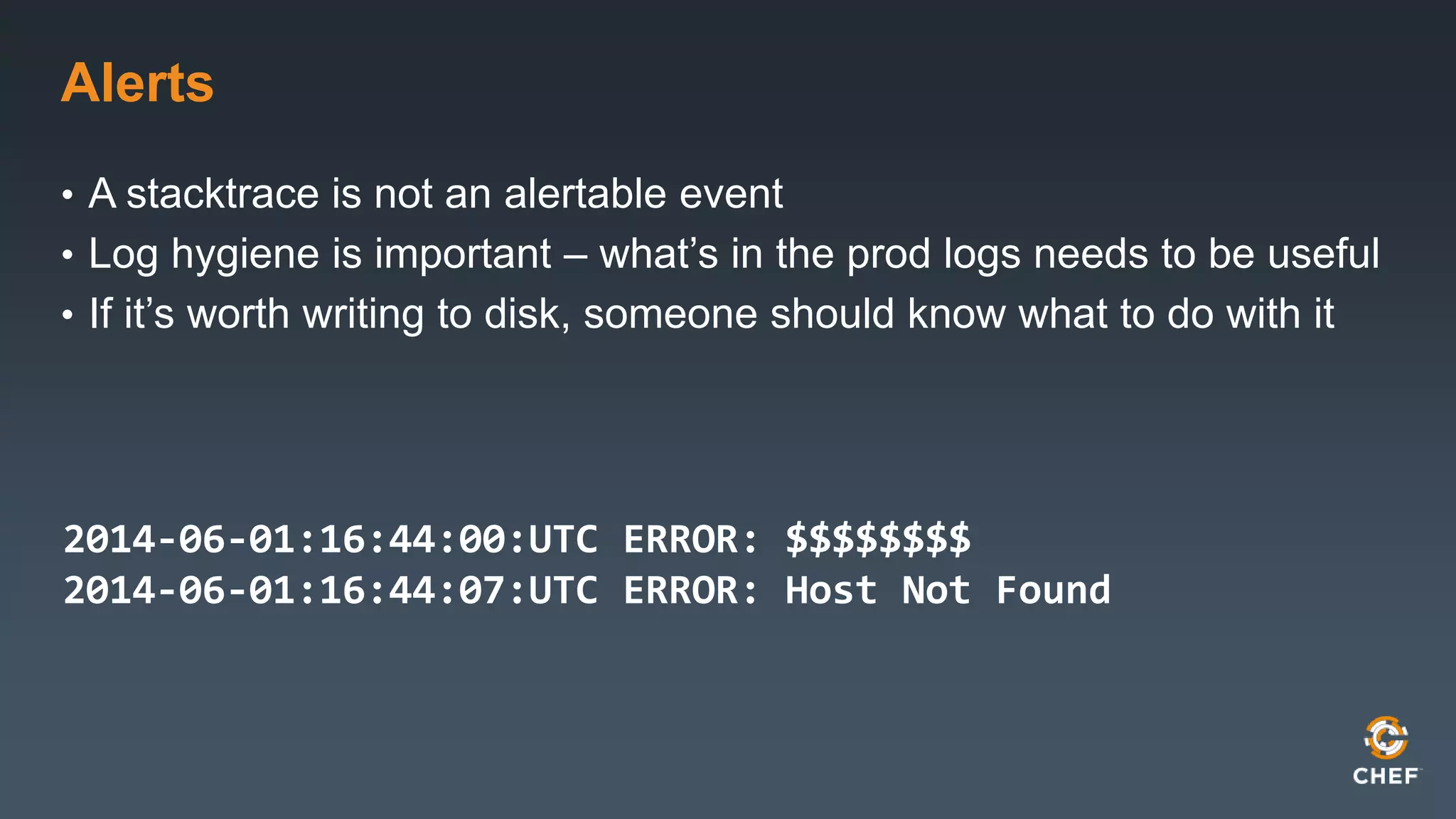















This document outlines best practices for conducting design reviews. It recommends reviewing applications layer by layer to understand deployment, operations, releases and outages. It provides a checklist of topics to cover including technologies, configurations, dependencies, monitoring, backups and contact information. Regular design reviews help operations teams understand new projects and provide input to support deployments and ongoing management.