Downloaded 37 times





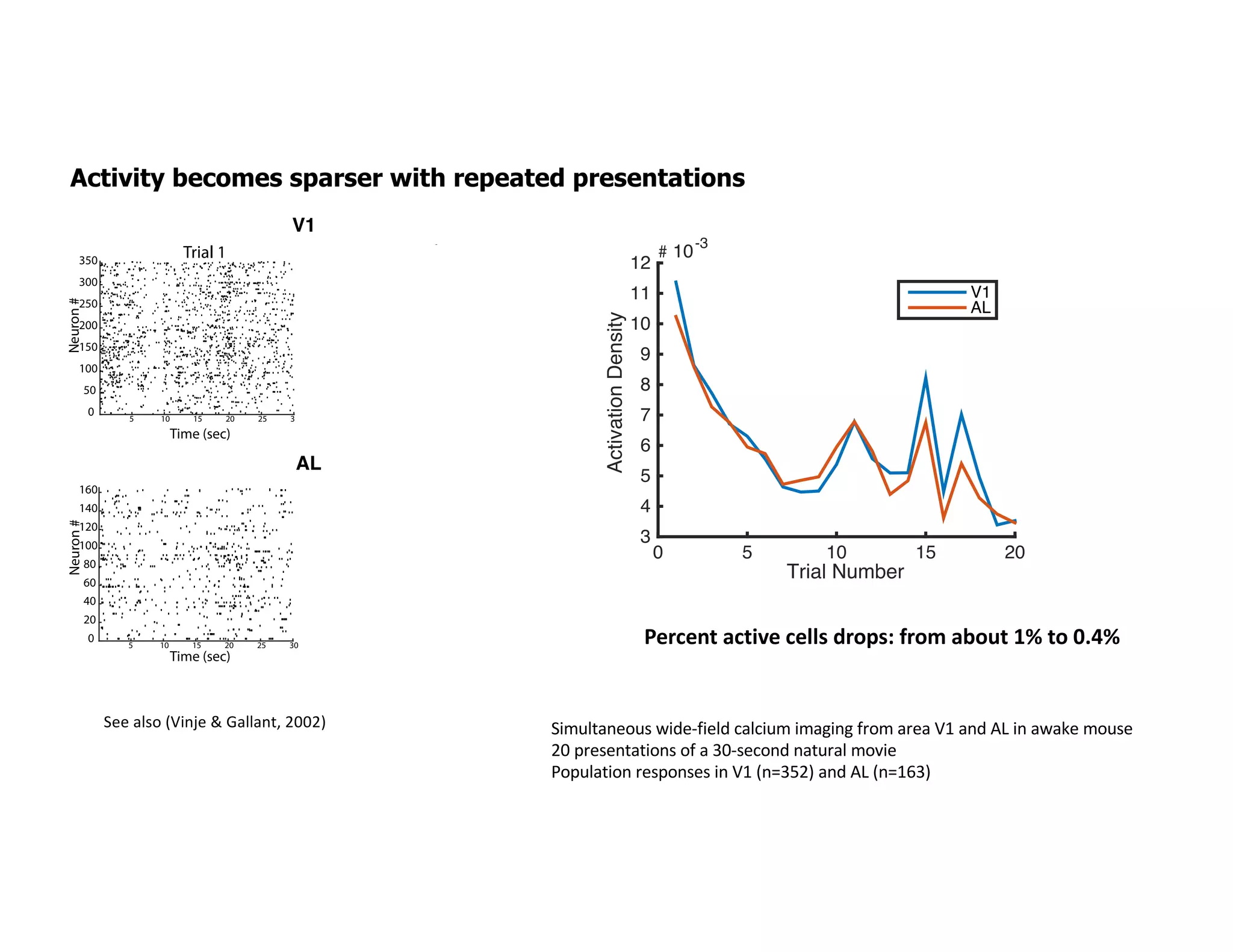

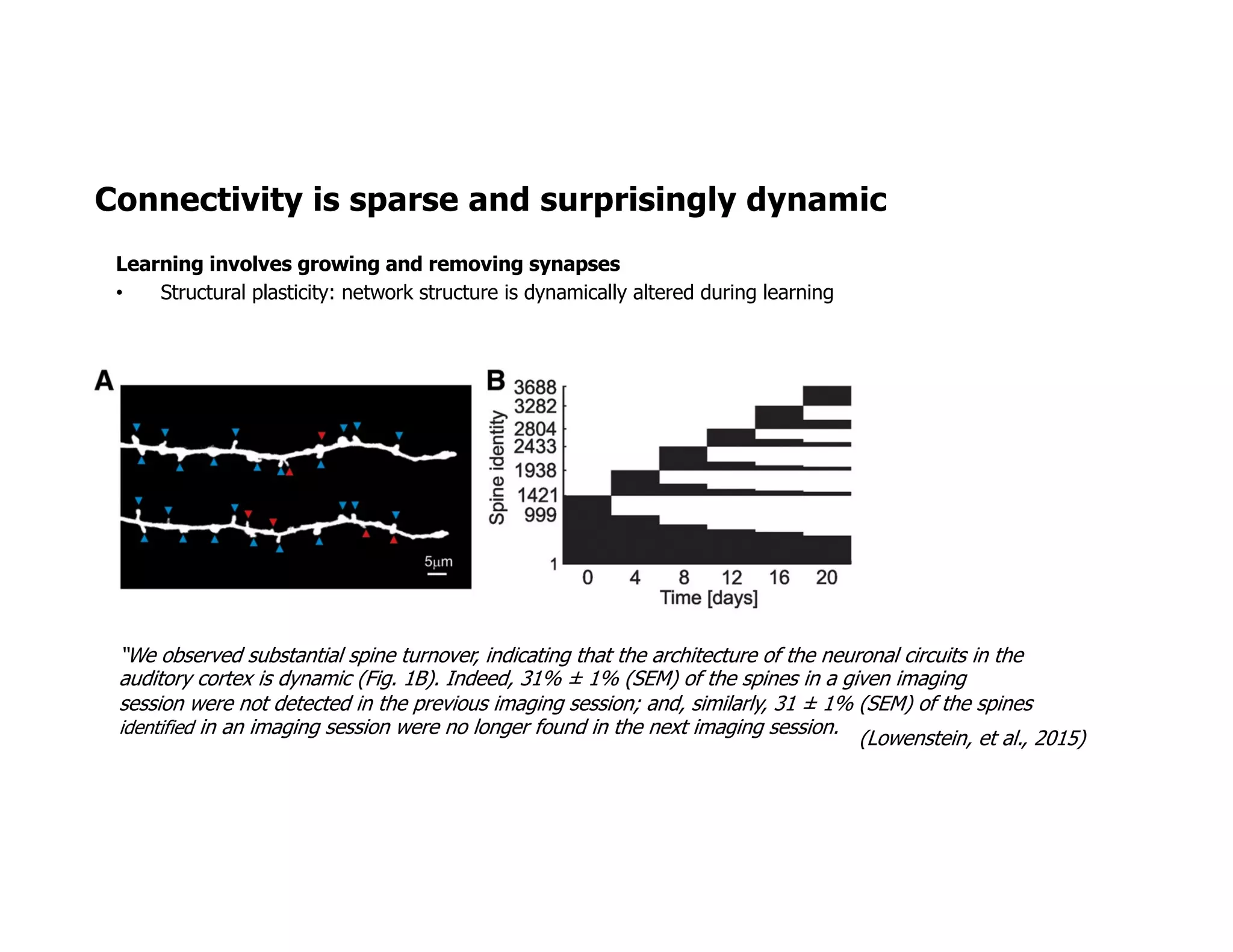

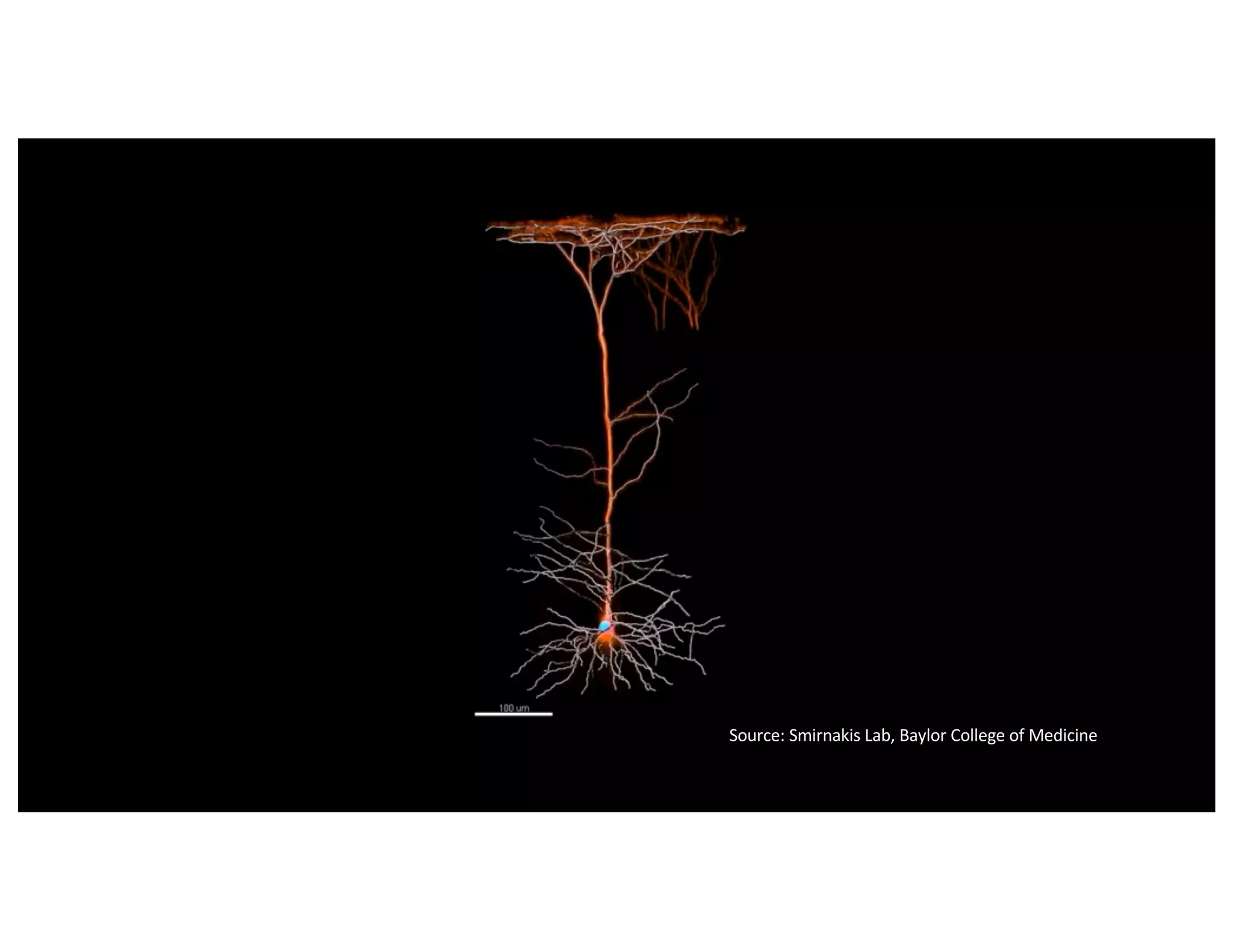
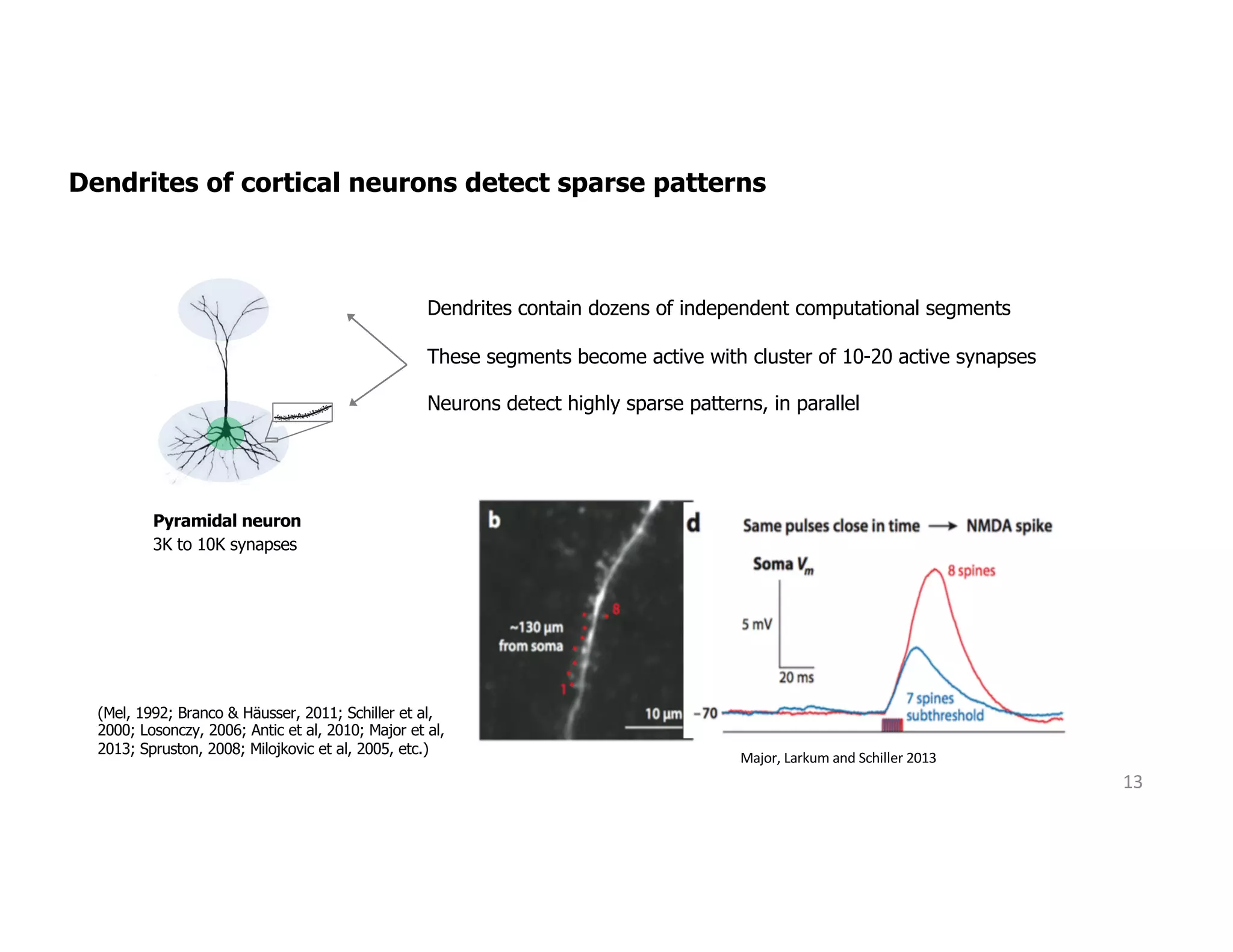
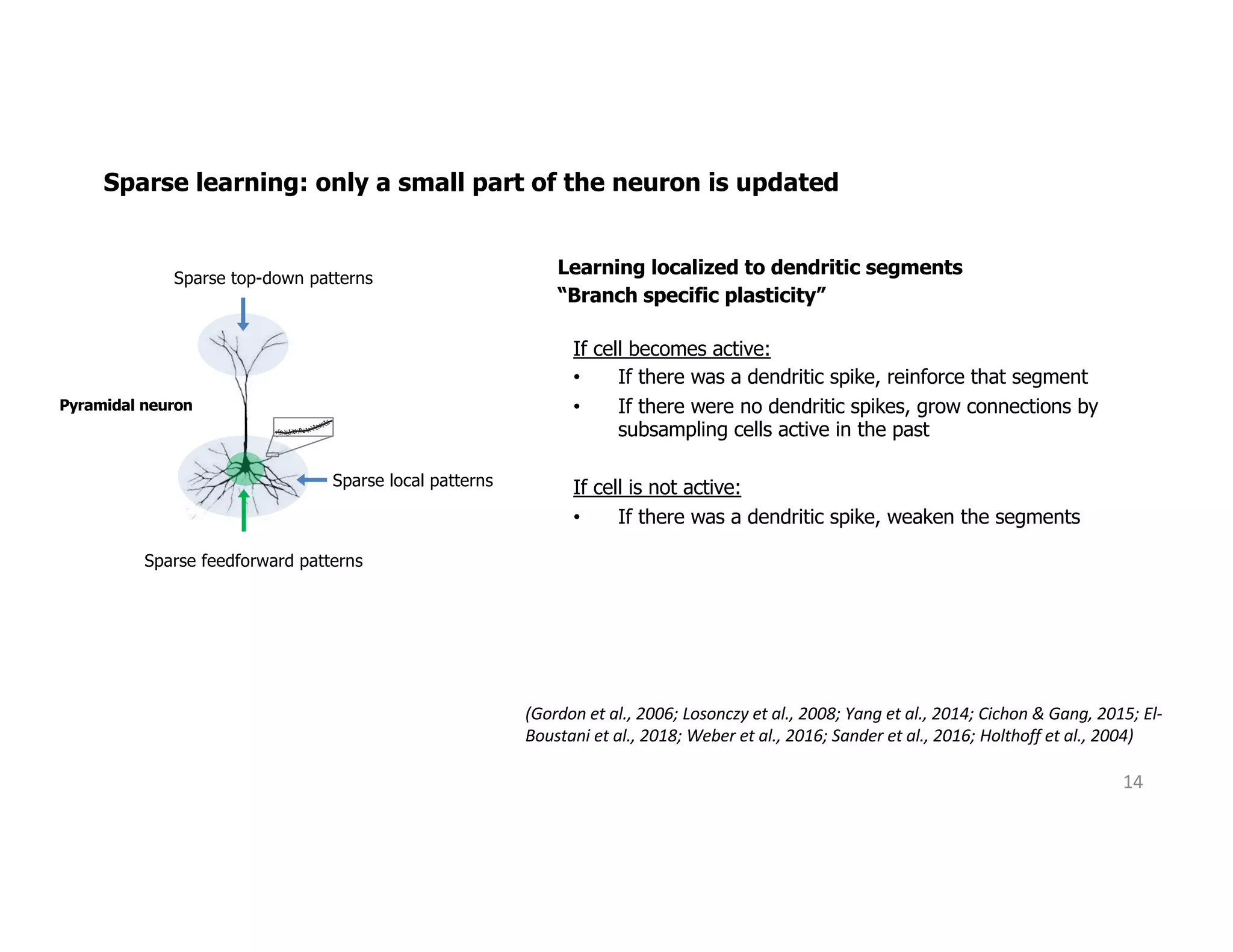


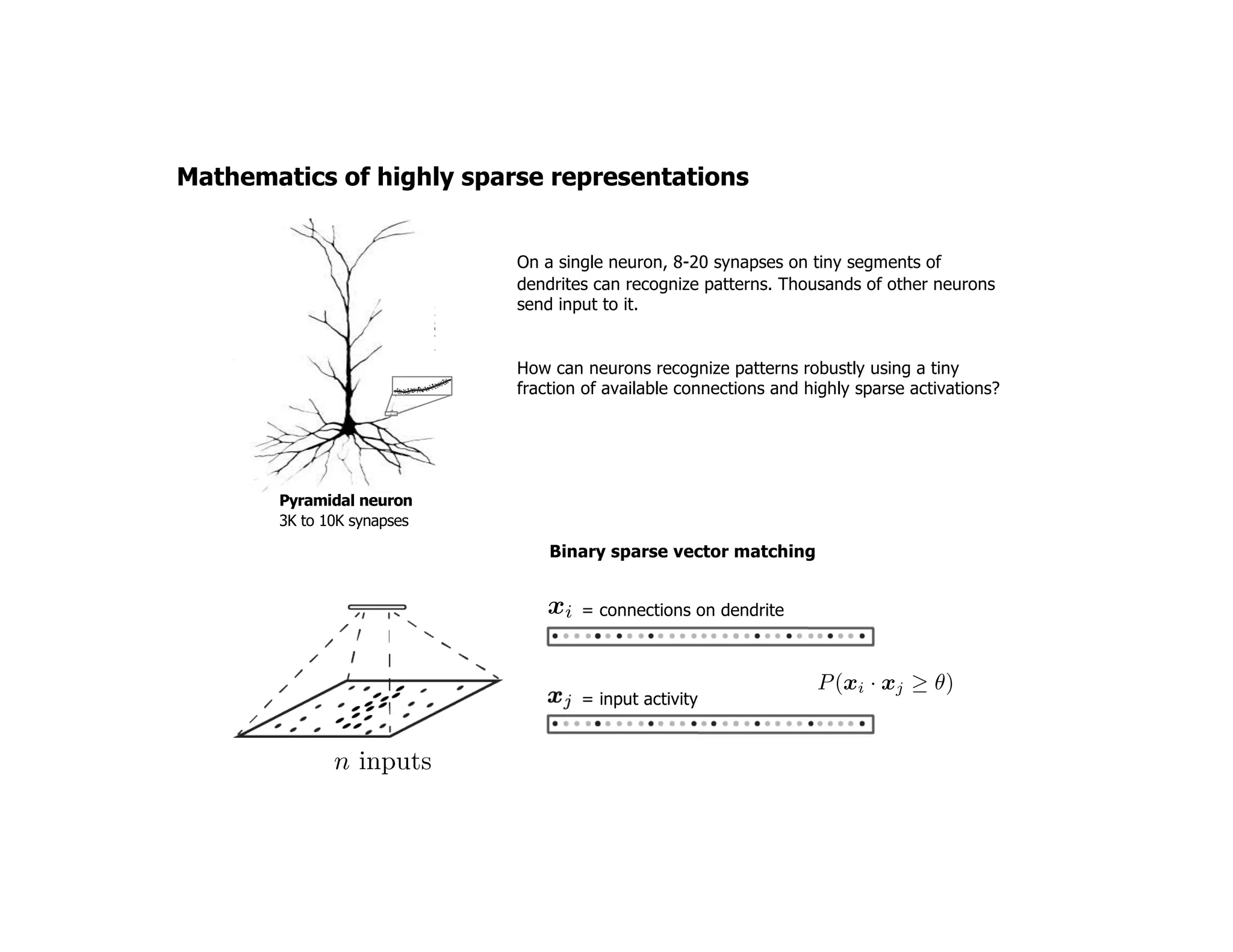

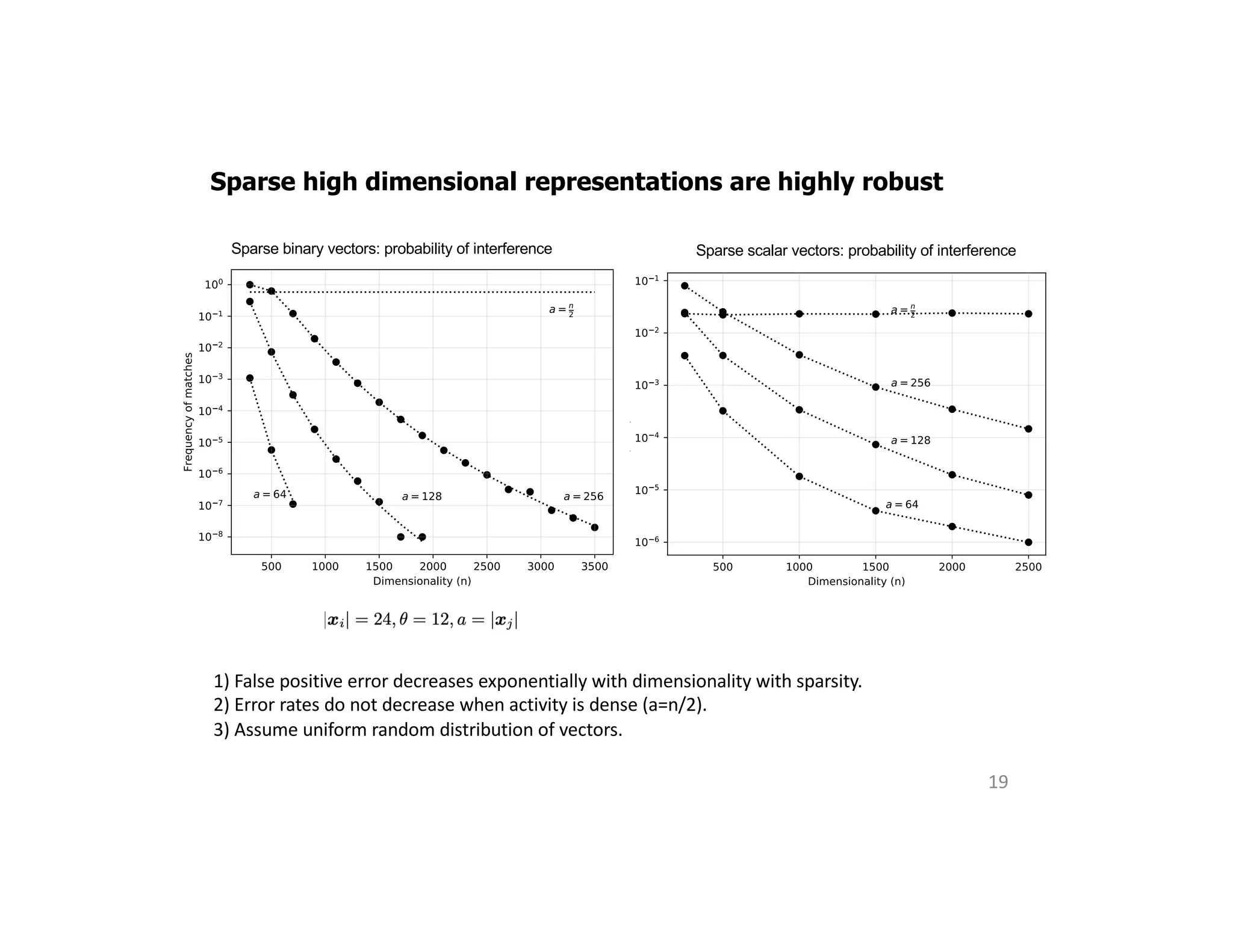


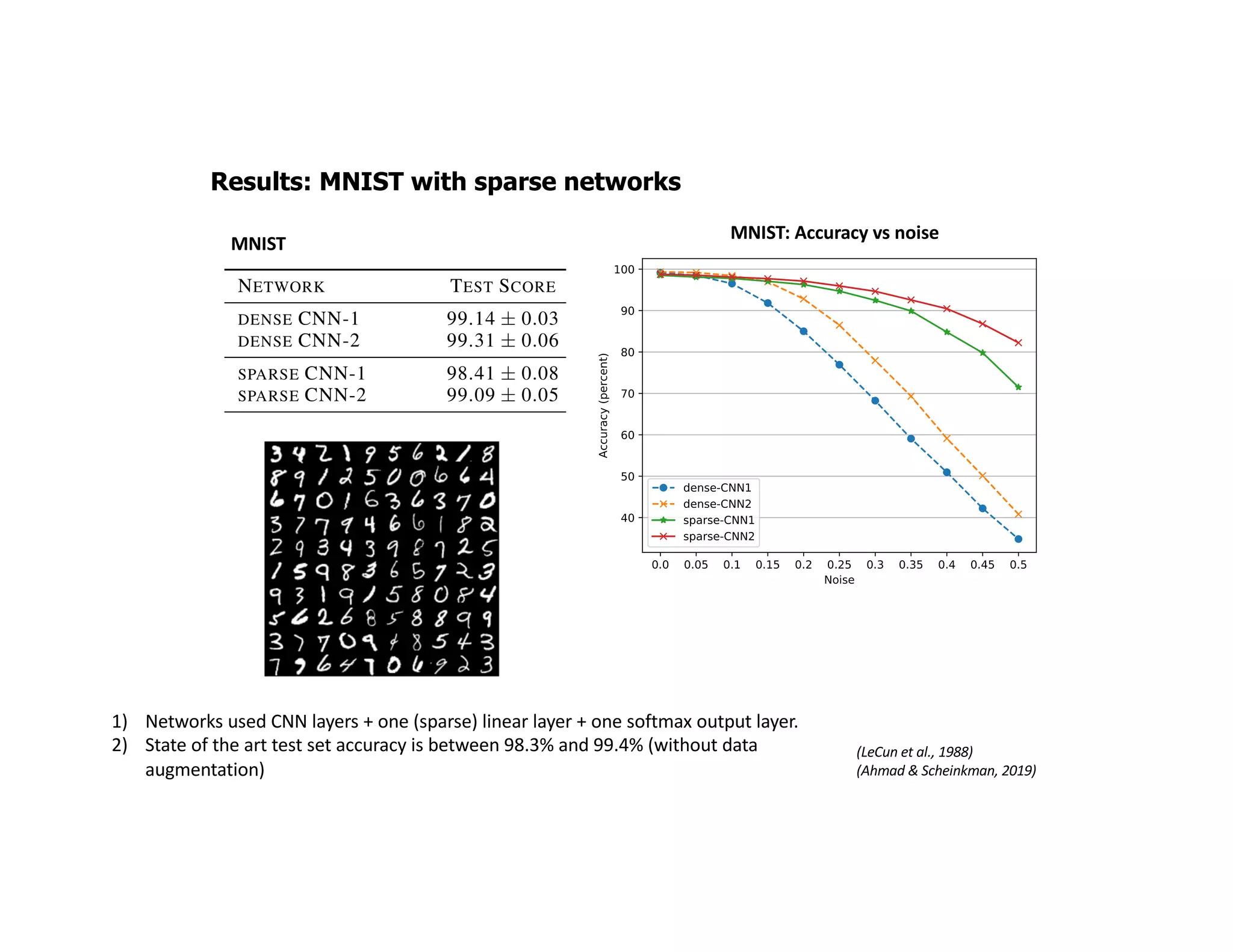




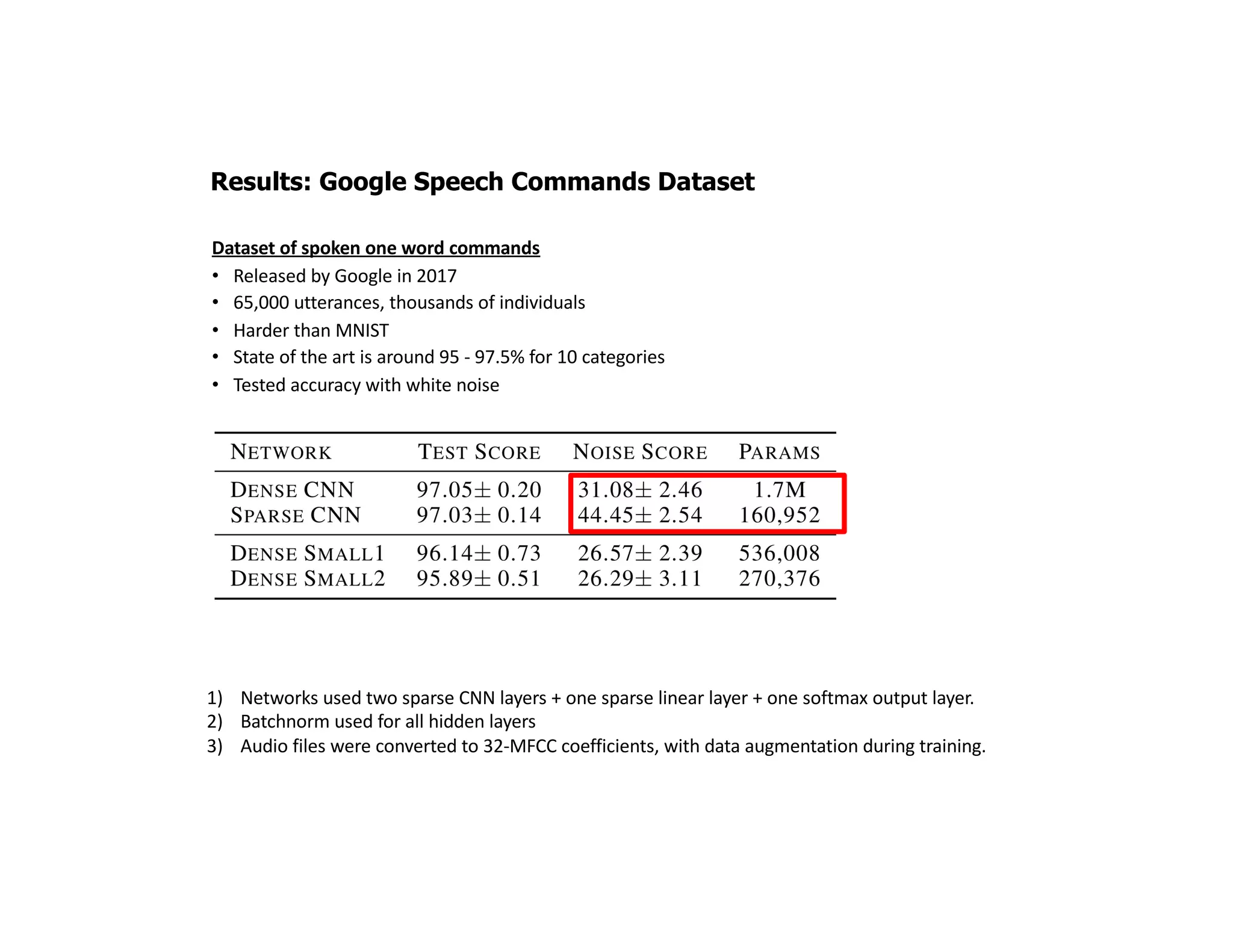


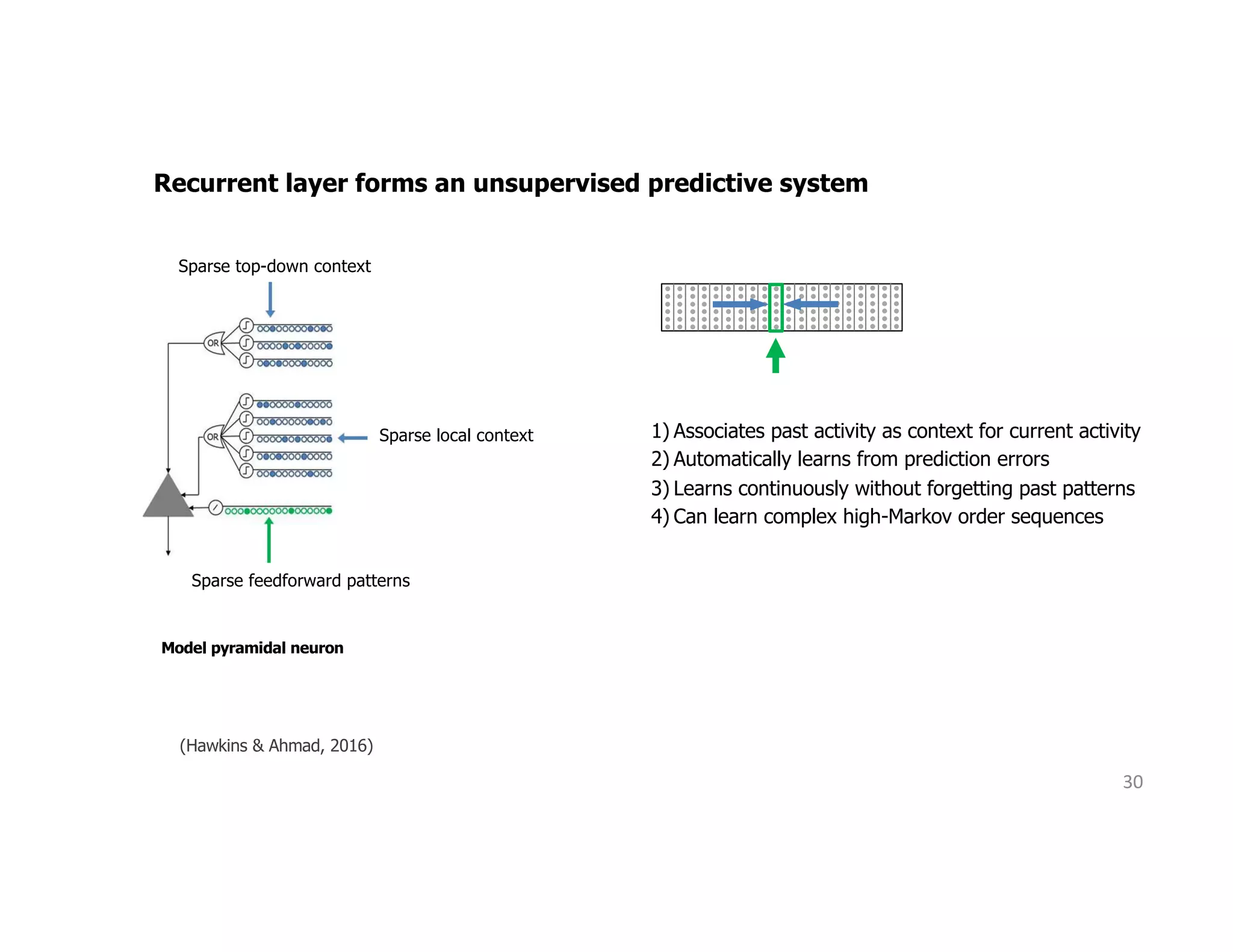

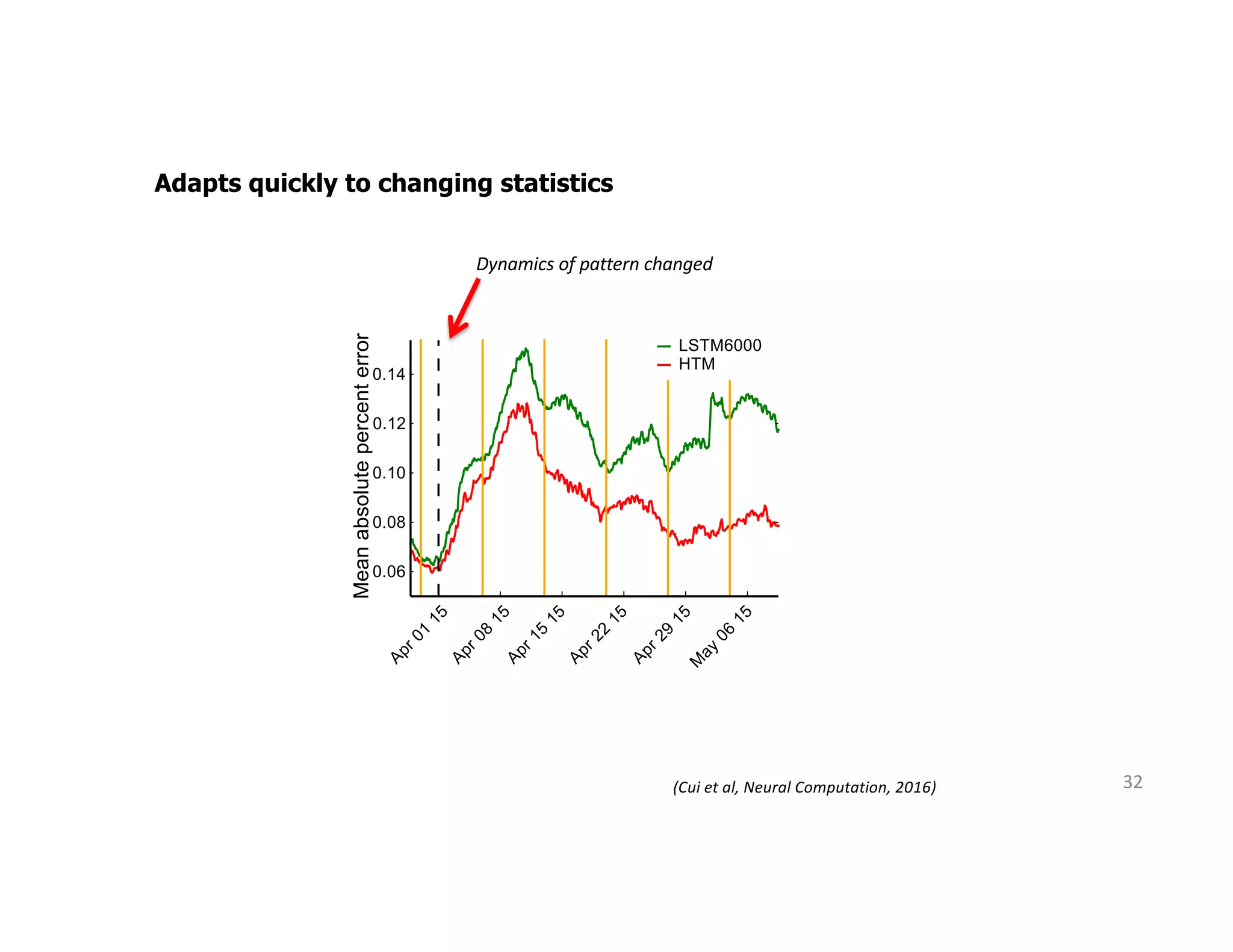





The document discusses the principles of sparsity in the neocortex and its implications for improving machine learning. It highlights three types of sparsity: population, lifetime, and connection sparsity, and emphasizes that a small percentage of neurons are active at any given time. The paper argues that understanding these principles can inform better AI techniques aimed at more efficient and robust systems.











































































