Downloaded 29 times




















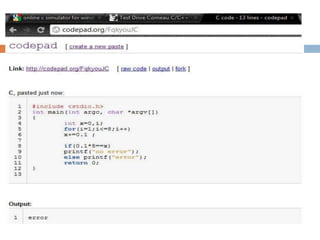
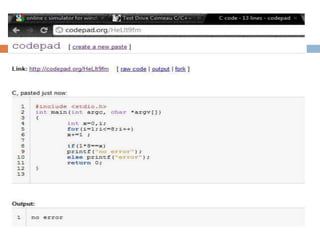





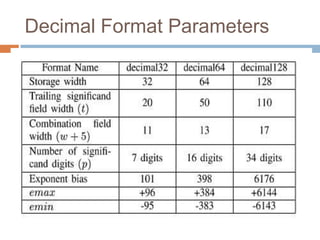


To represent a binary floating-point number as an exact fraction, the number of decimal digits needed depends on the precision of the binary floating-point format. Higher precision formats like double precision may require on the order of 15-17 decimal digits. To represent a binary floating-point number reversibly so that it can be converted back to the same binary value, the number of decimal digits needed depends on the precision as well as the desired rounding mode. For double precision numbers using round-to-nearest rounding, about 16-17 decimal digits are typically needed.










































































