Downloaded 32 times


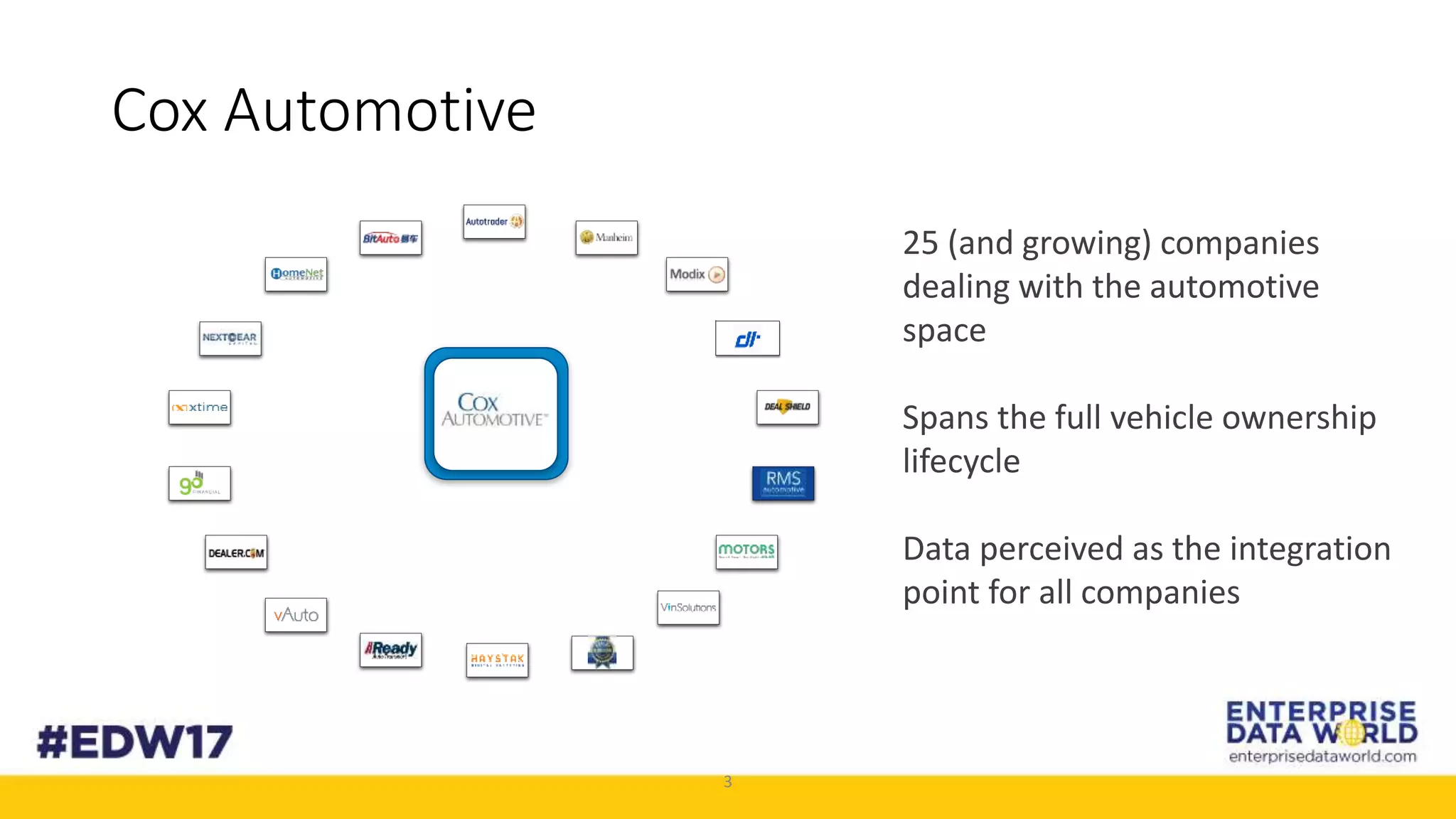
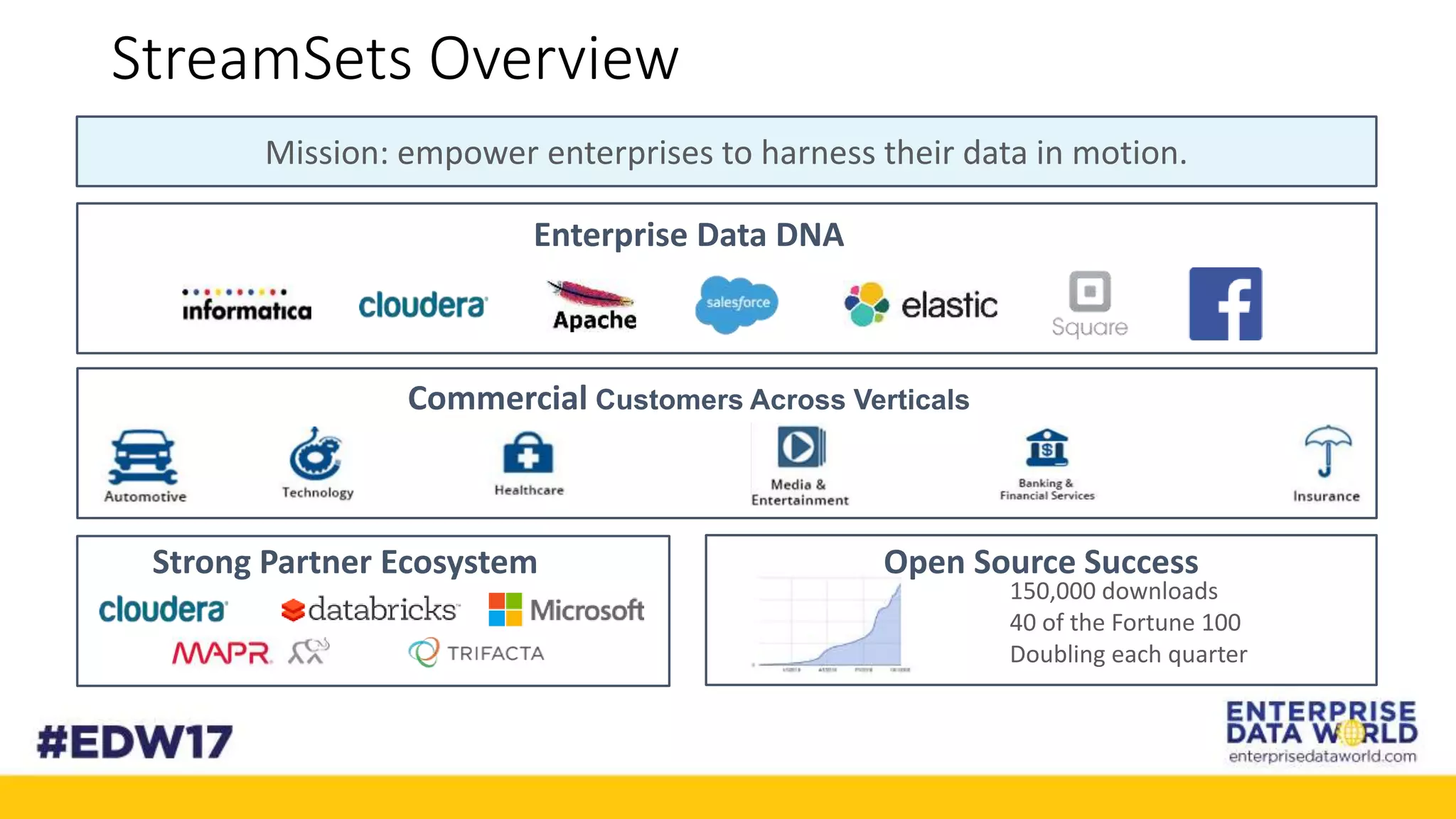
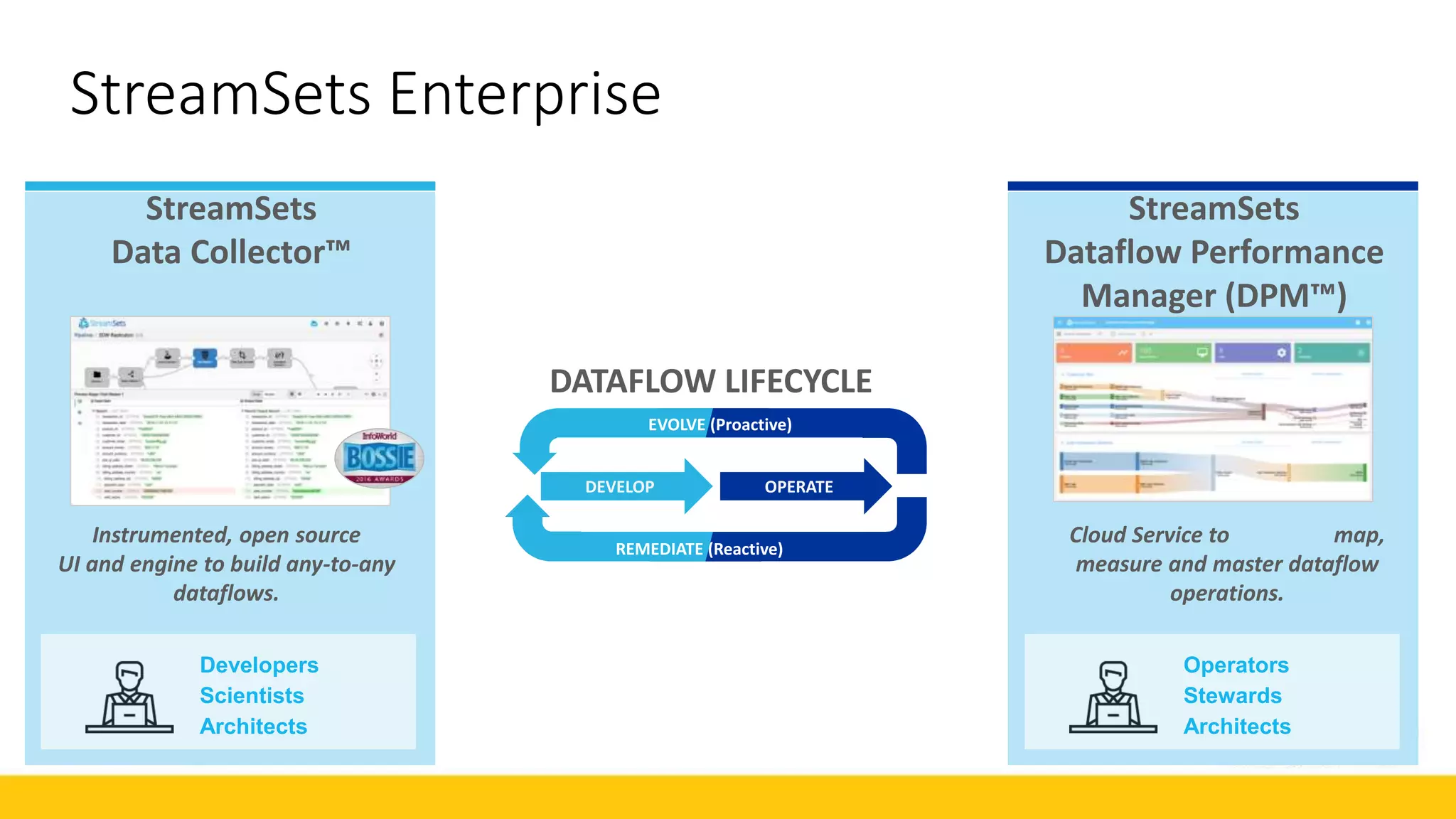



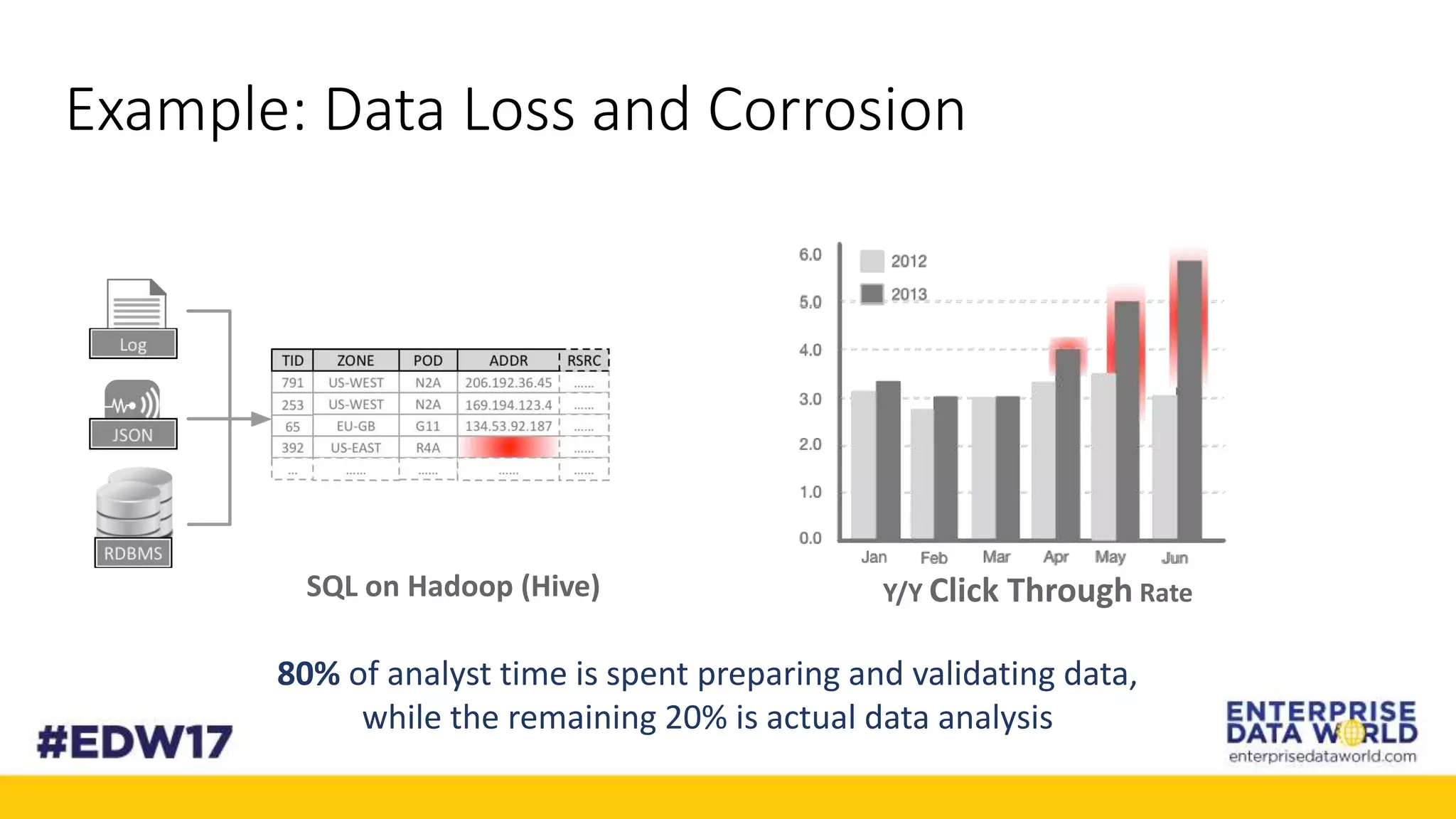

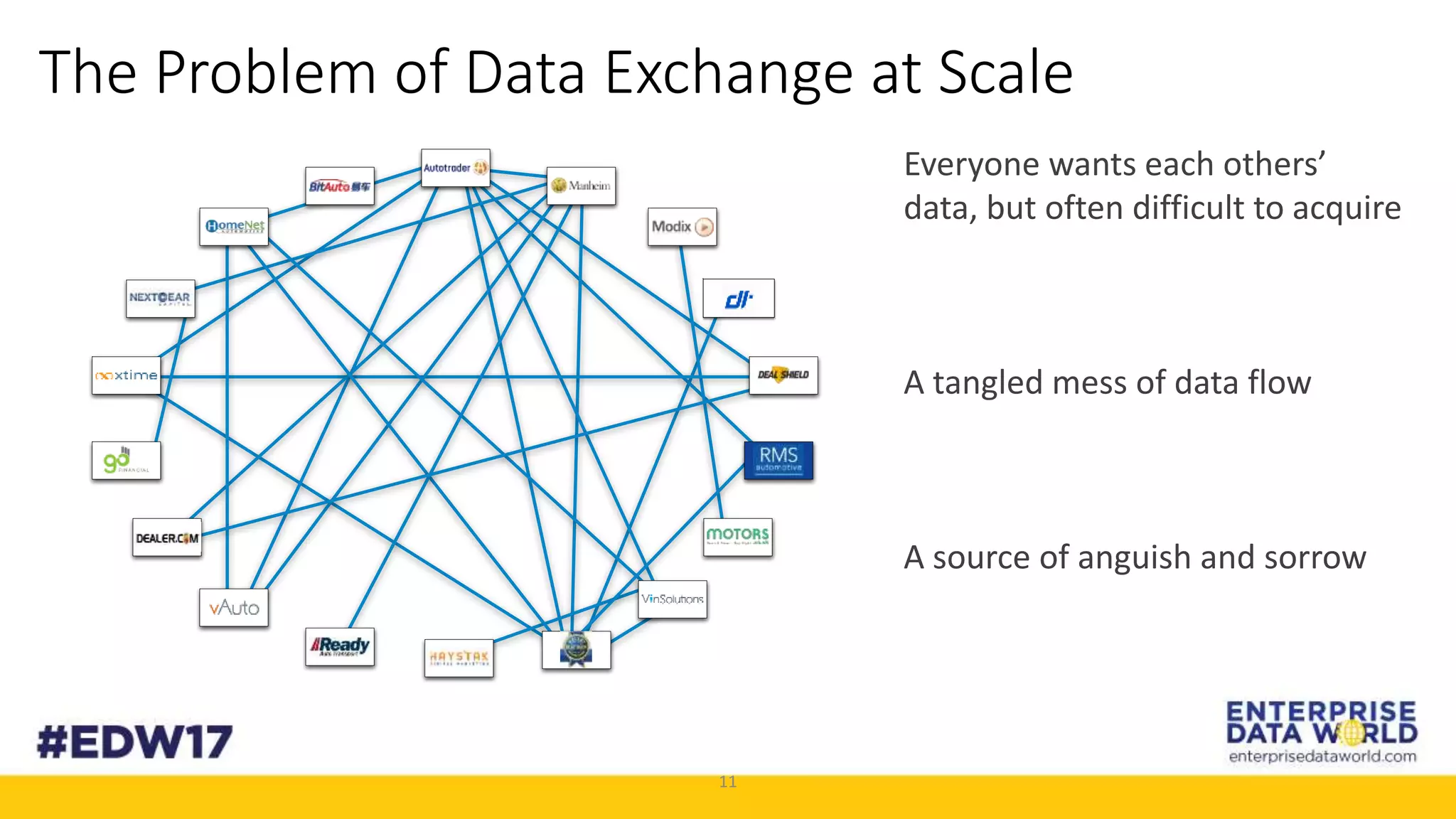
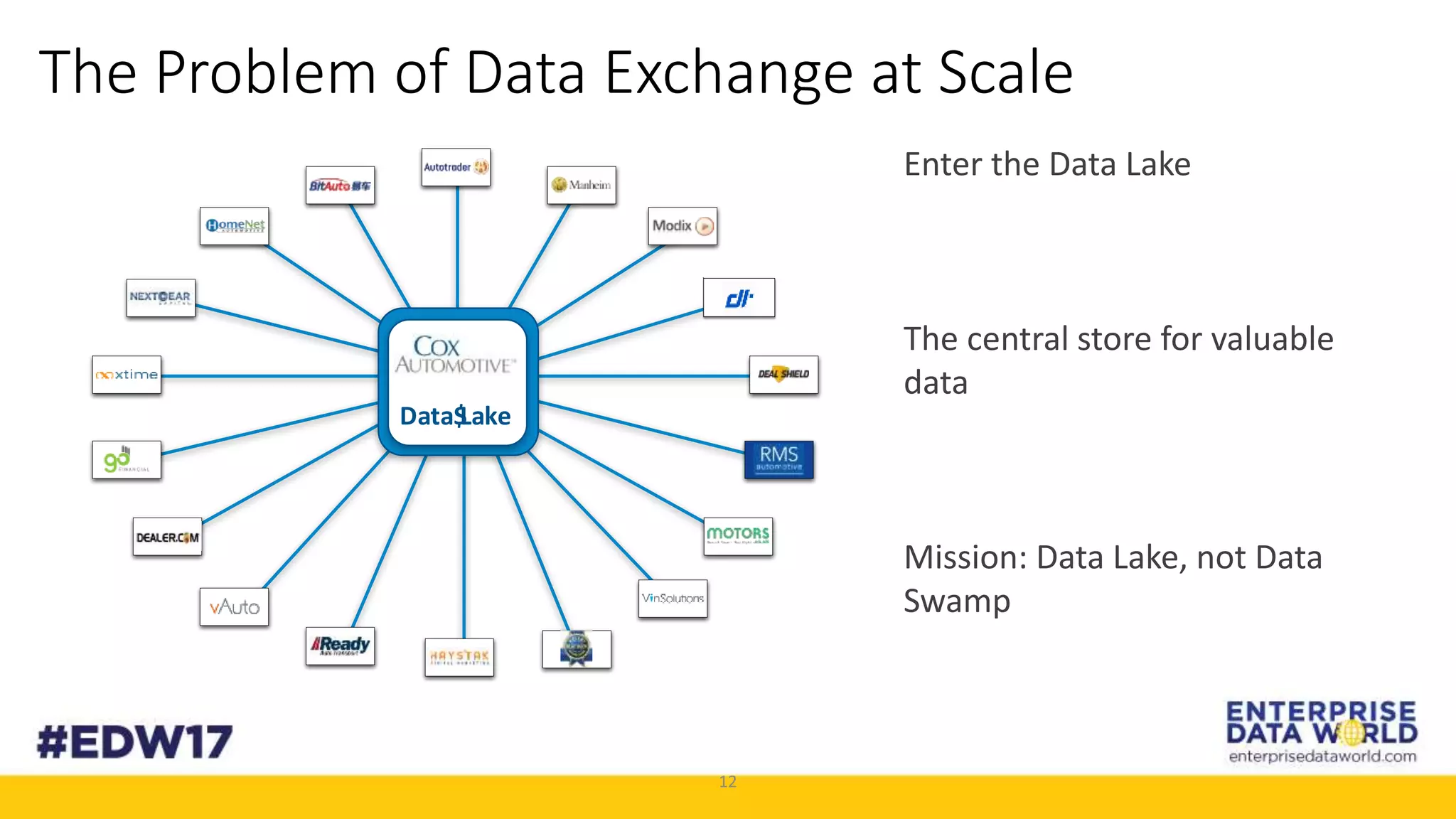

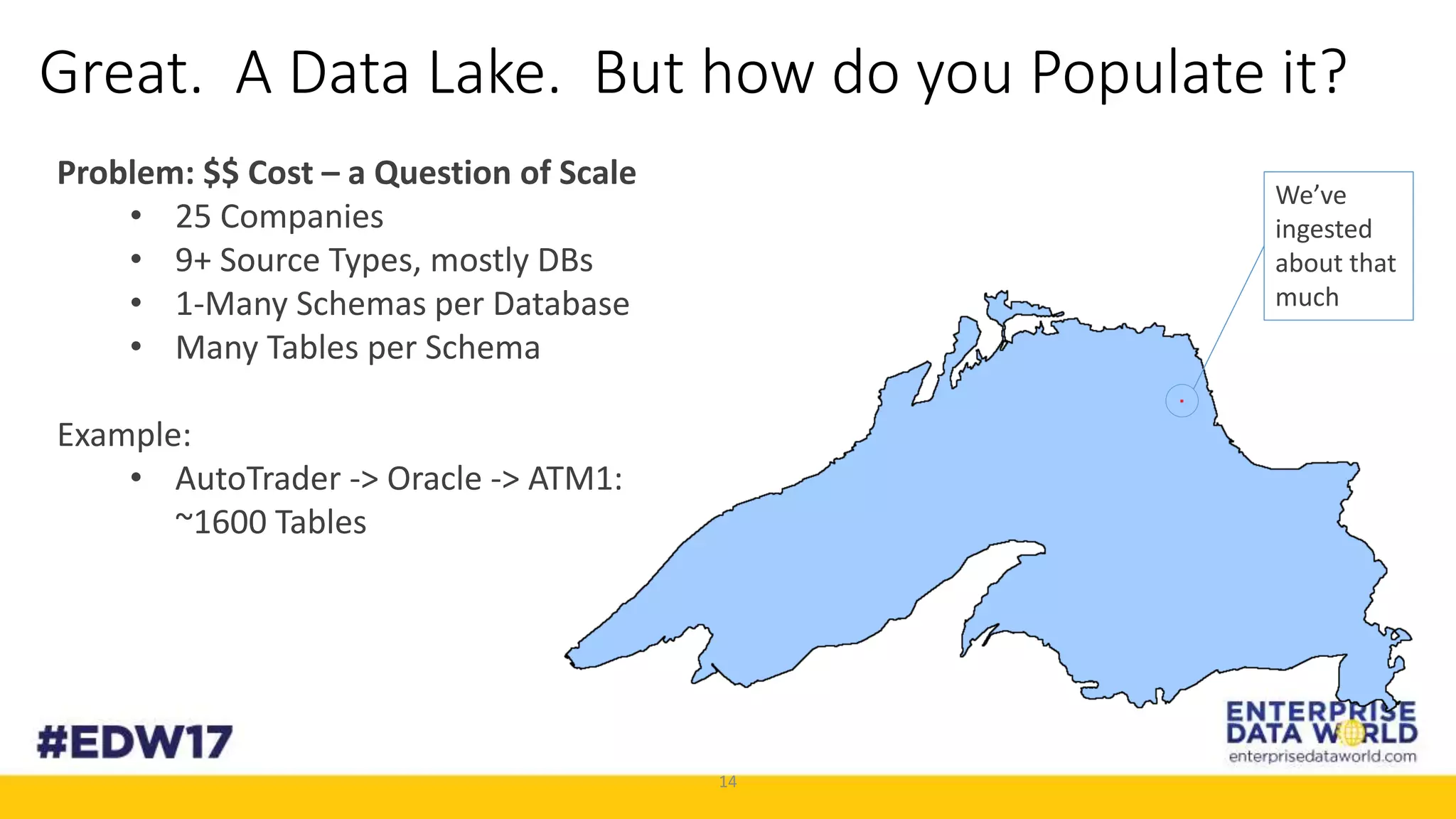
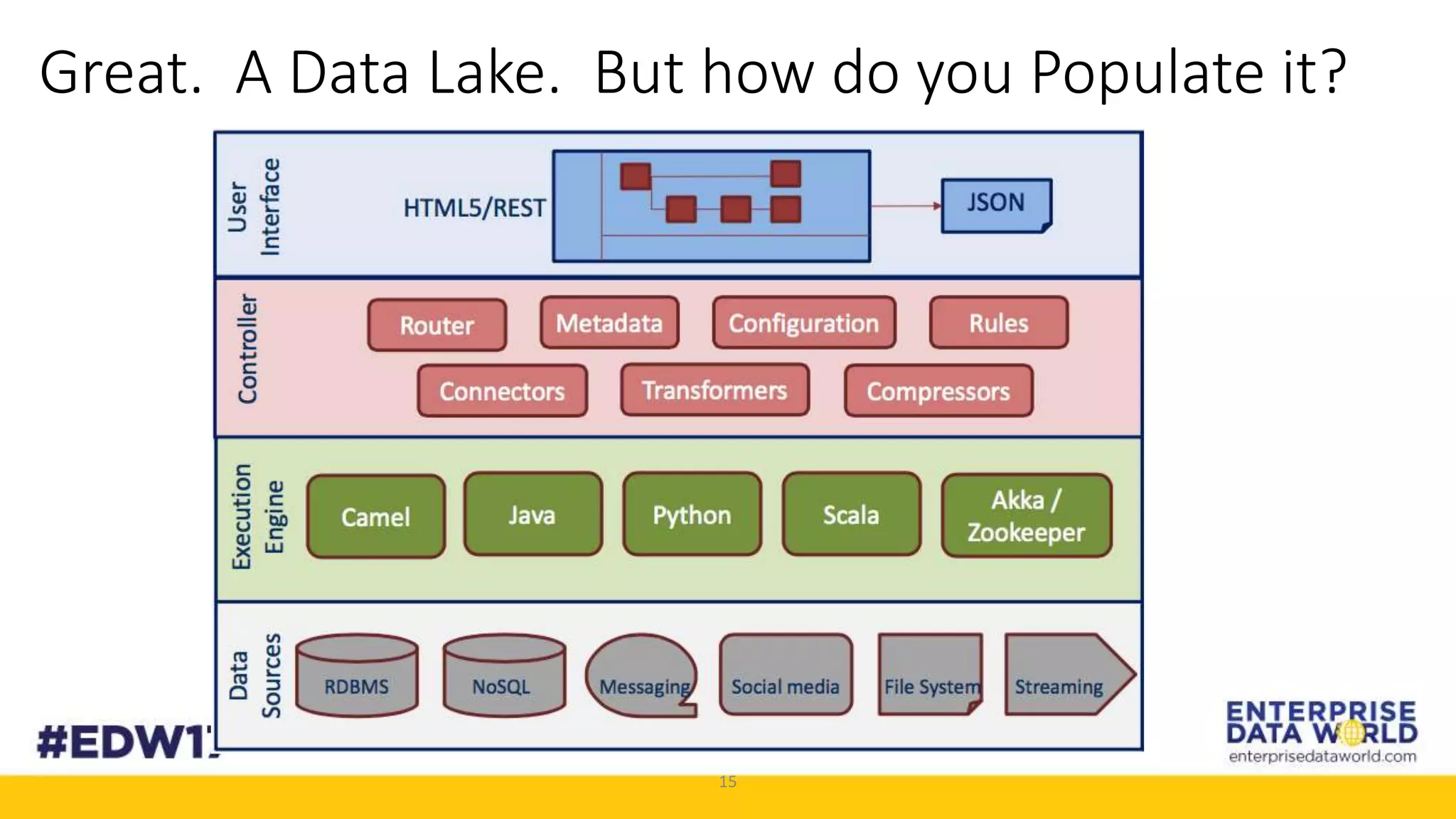
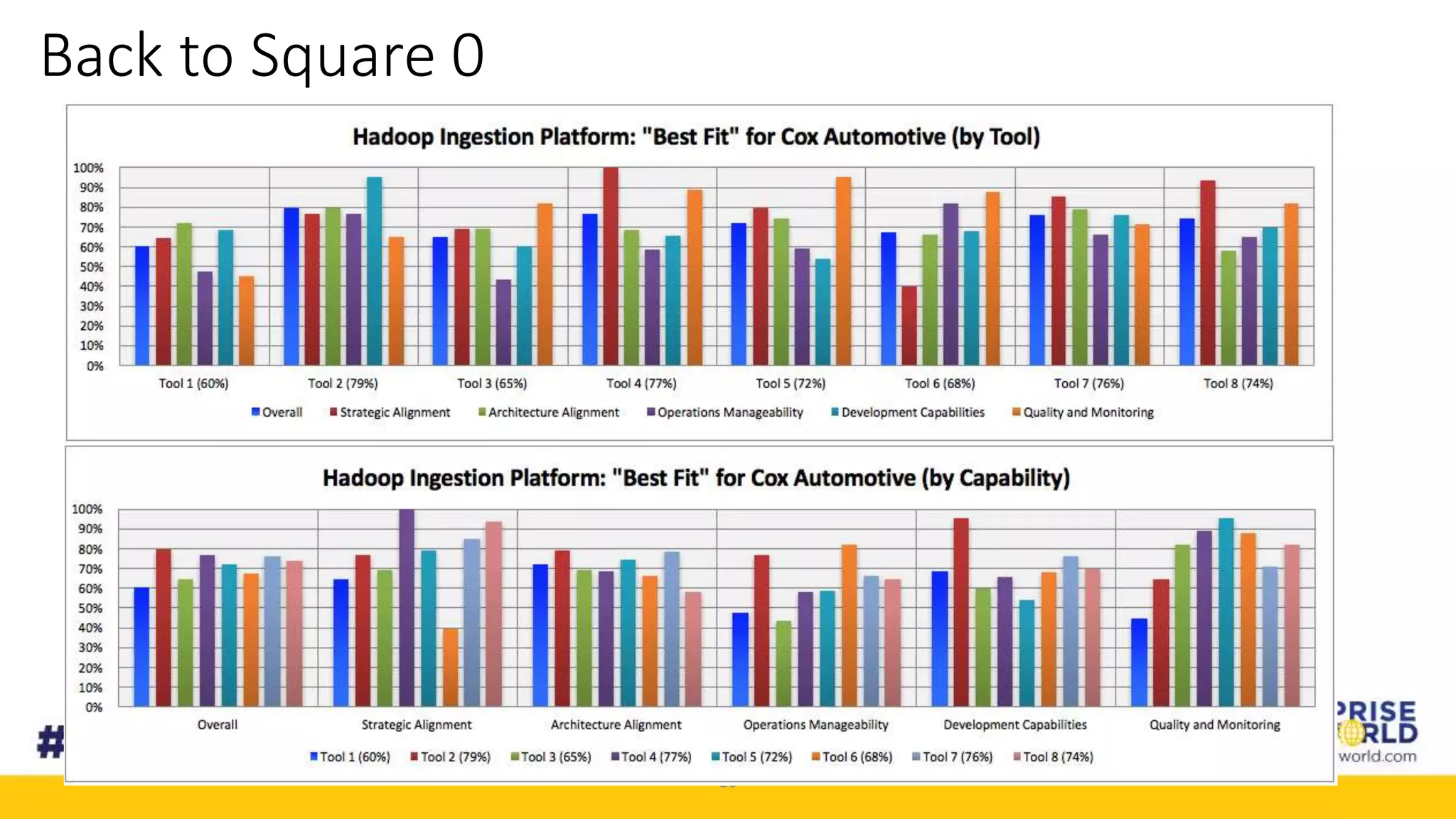
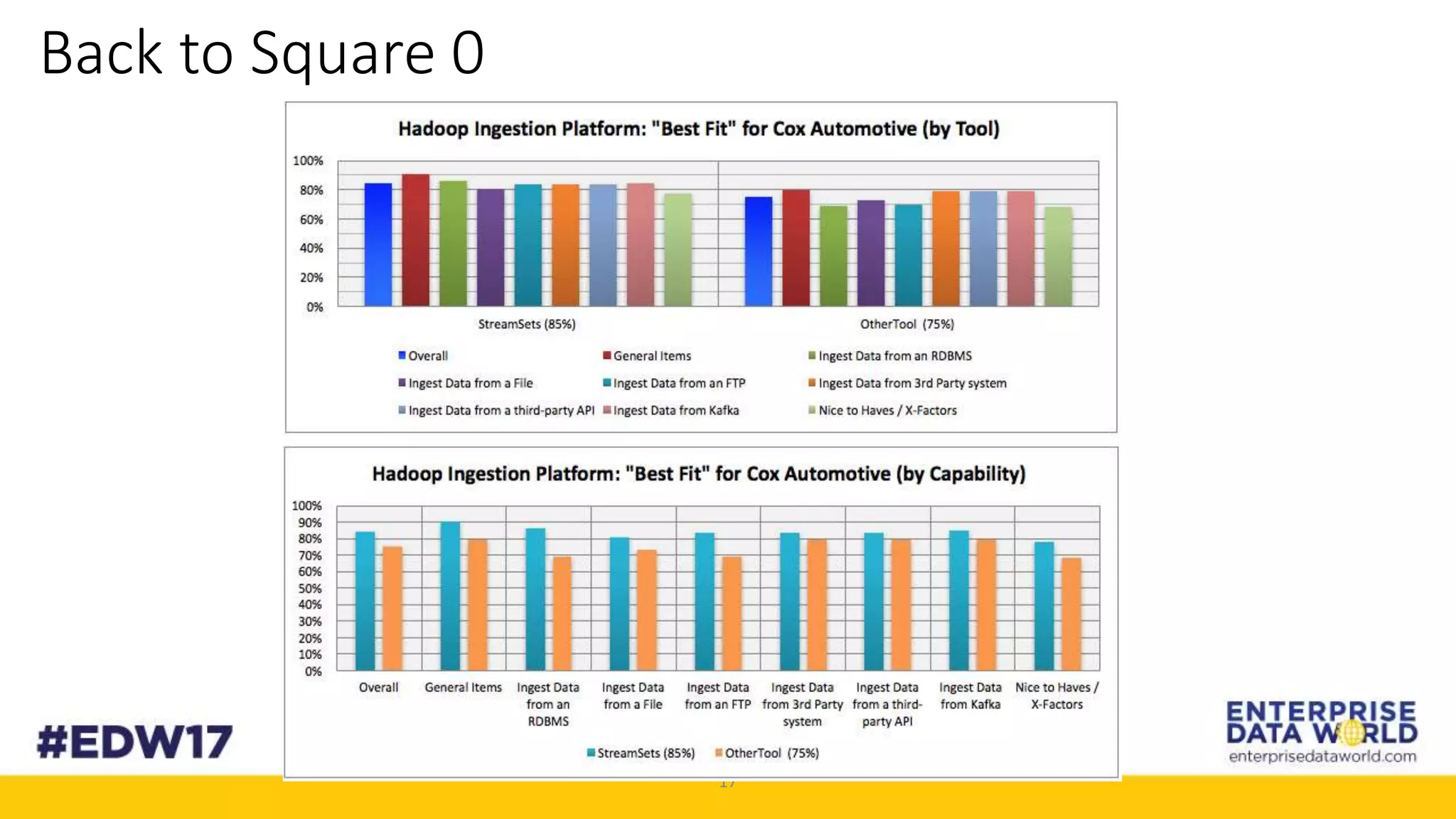
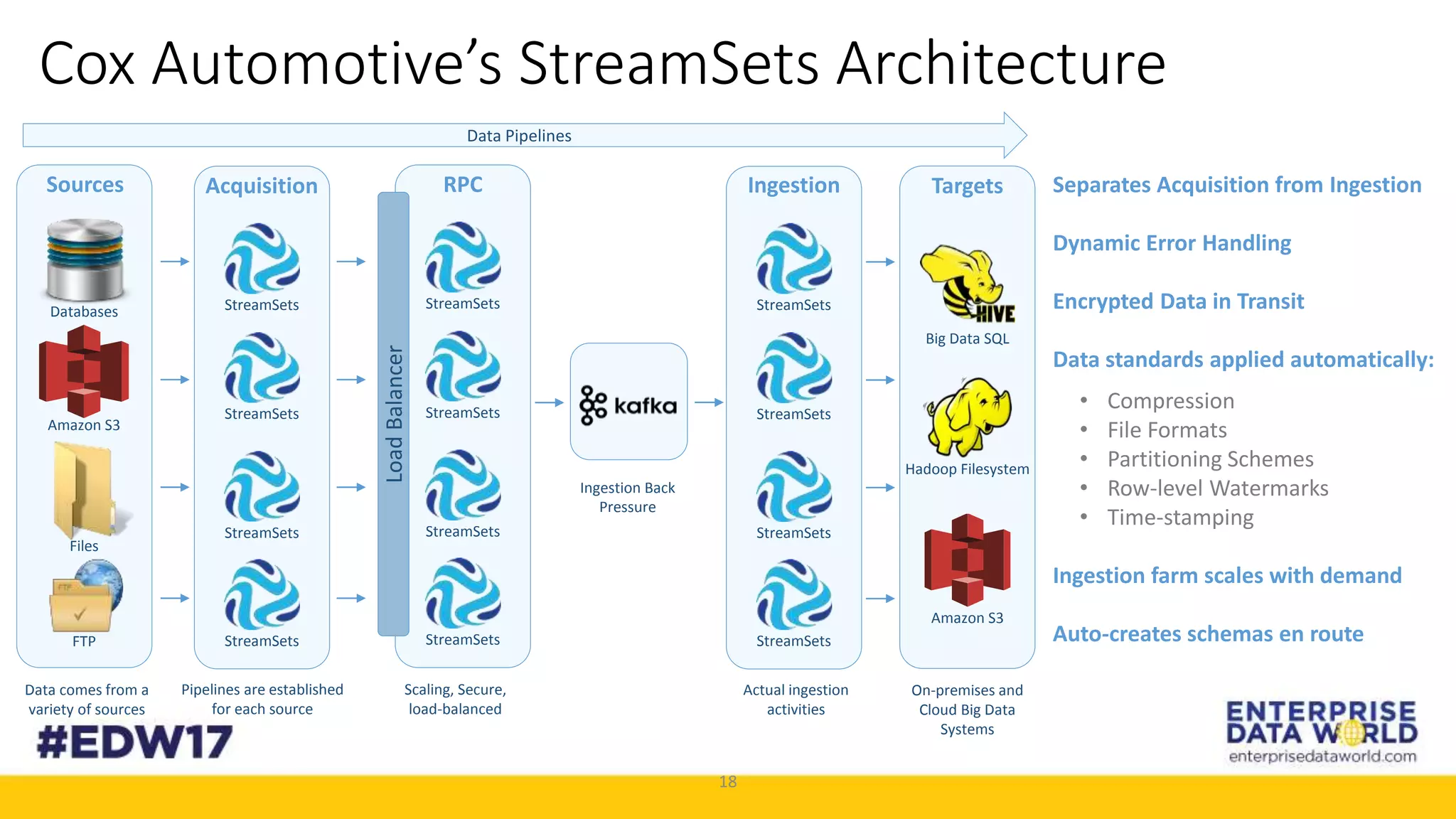
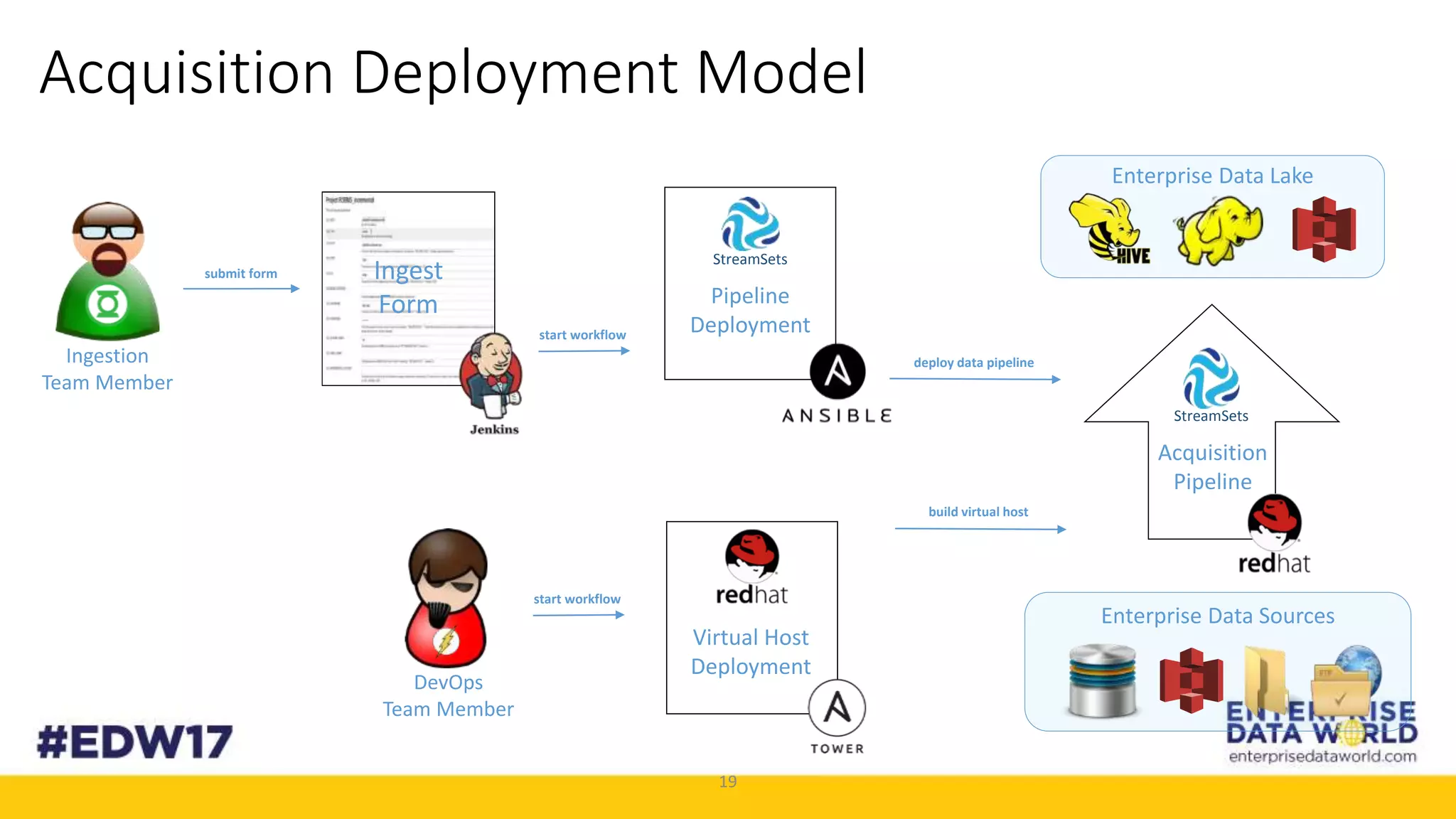
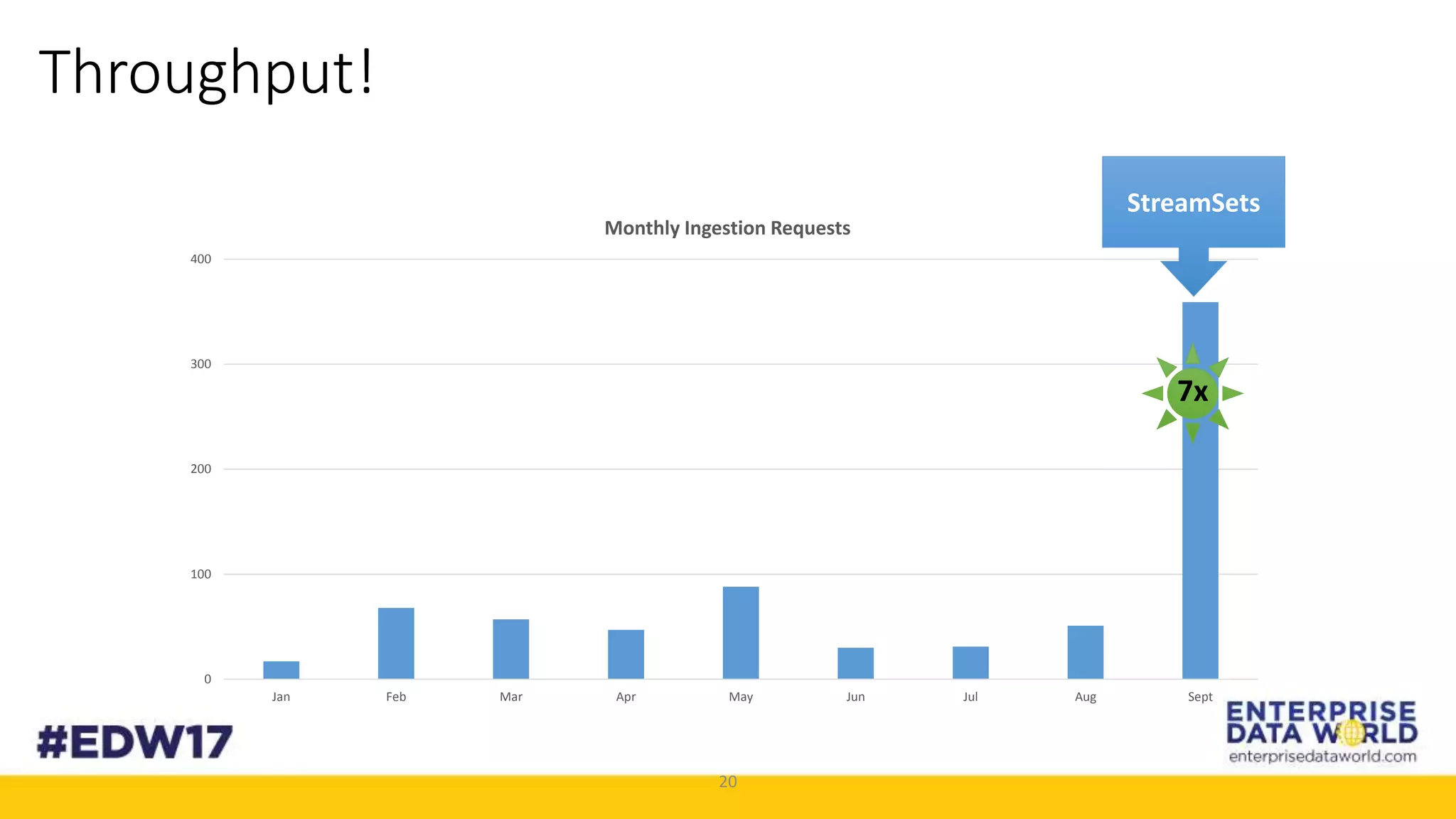

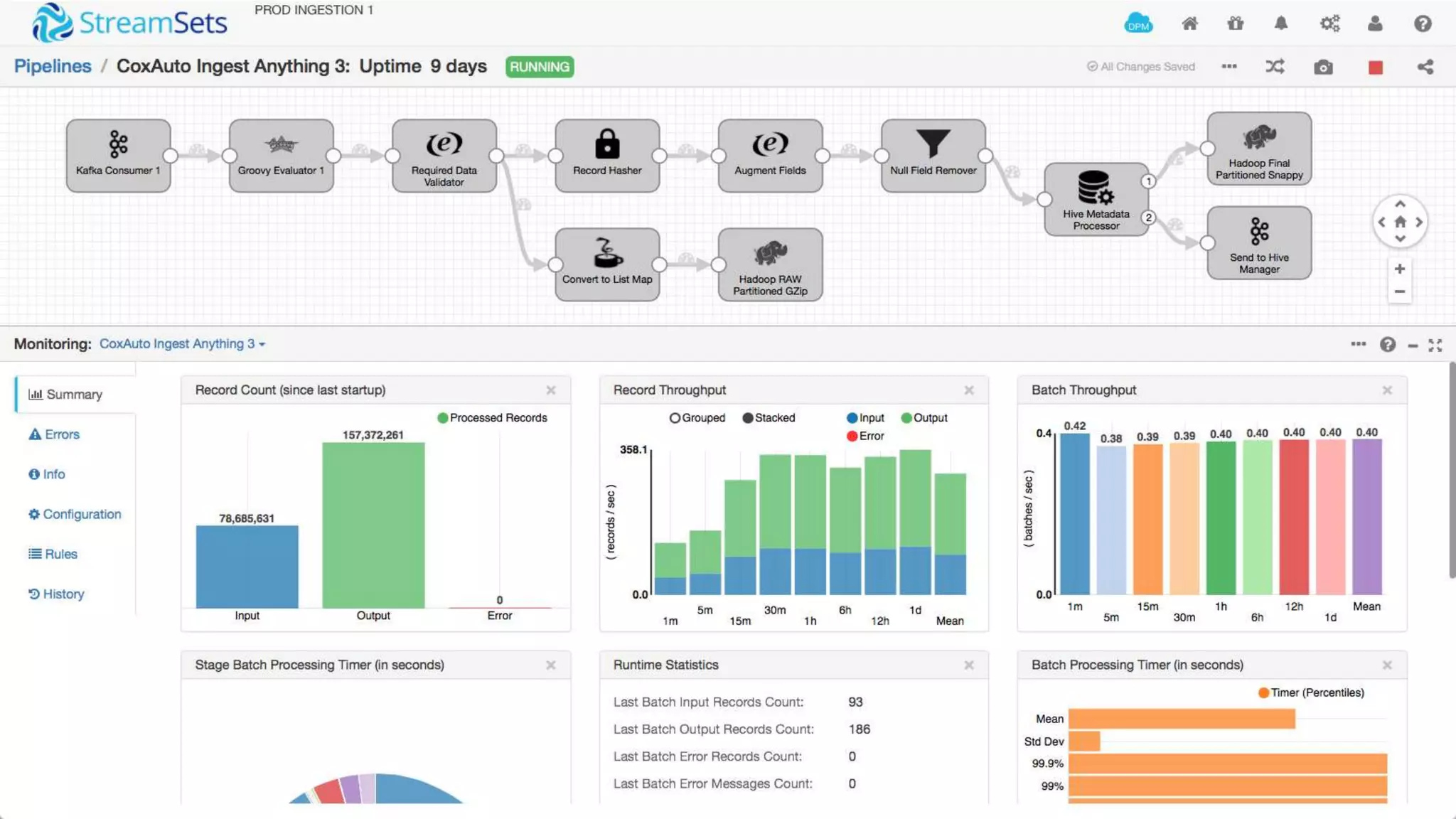
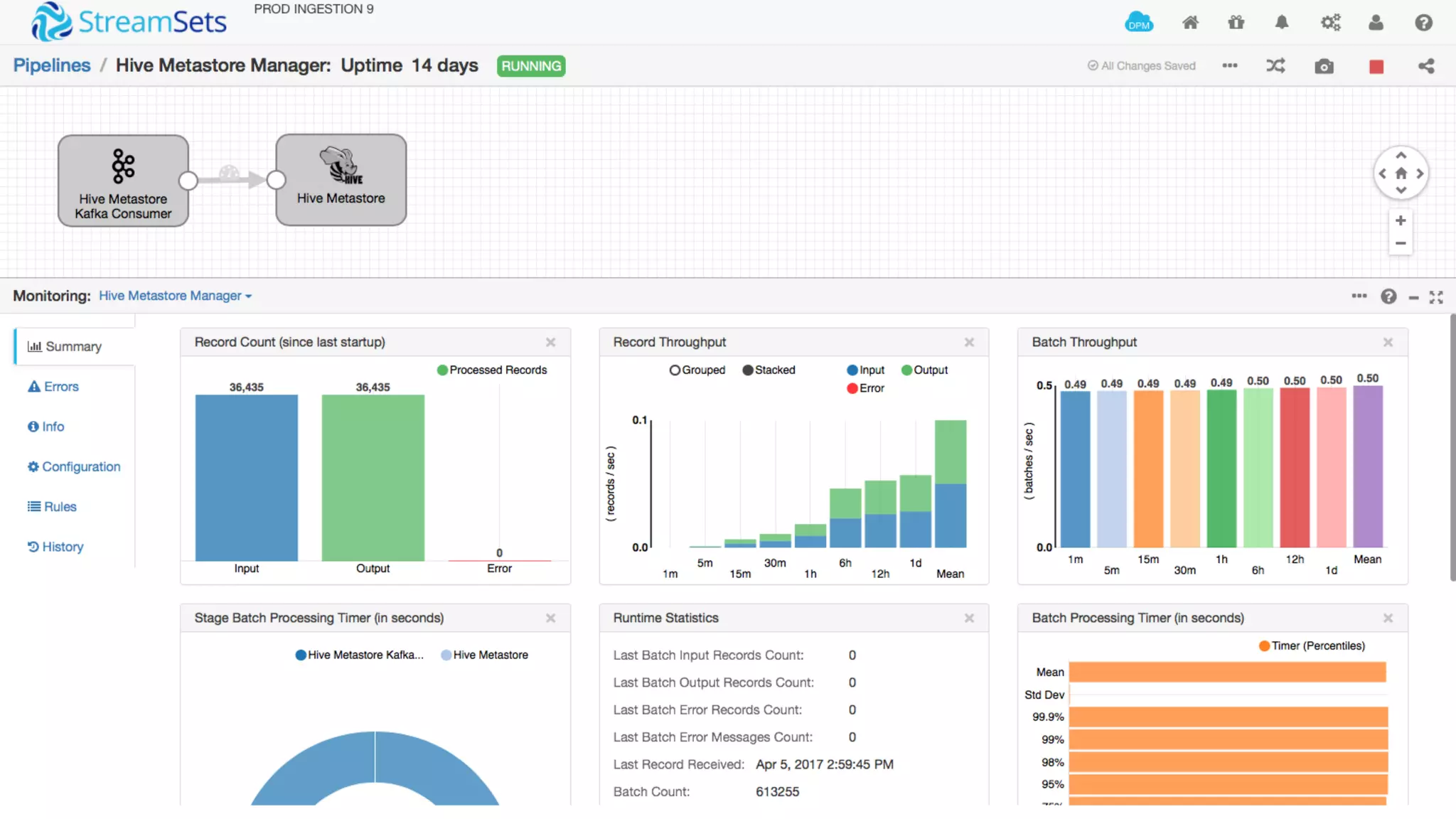
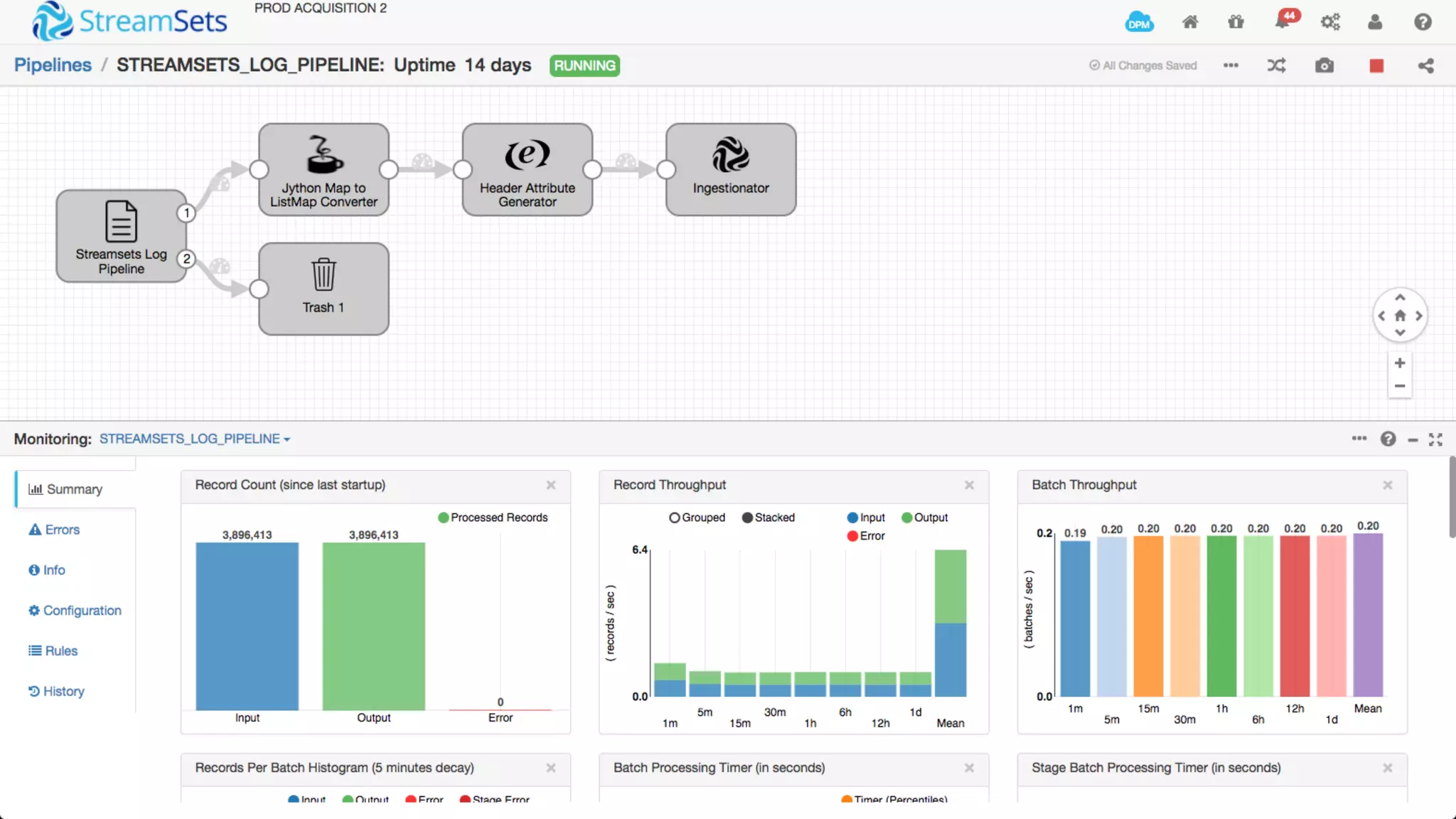



The document discusses Cox Automotive's strategies for building an enterprise data lake, emphasizing the importance of data integration across various companies in the automotive space. It highlights the challenges of data drift, the need for efficient data acquisition methods, and the use of StreamSets technology to manage data flows effectively. The goal is to empower organizations to harness their data seamlessly while maintaining high availability and accuracy.























































































