Download as PDF, PPTX










![Sqoop - FYI
Design considerations - I
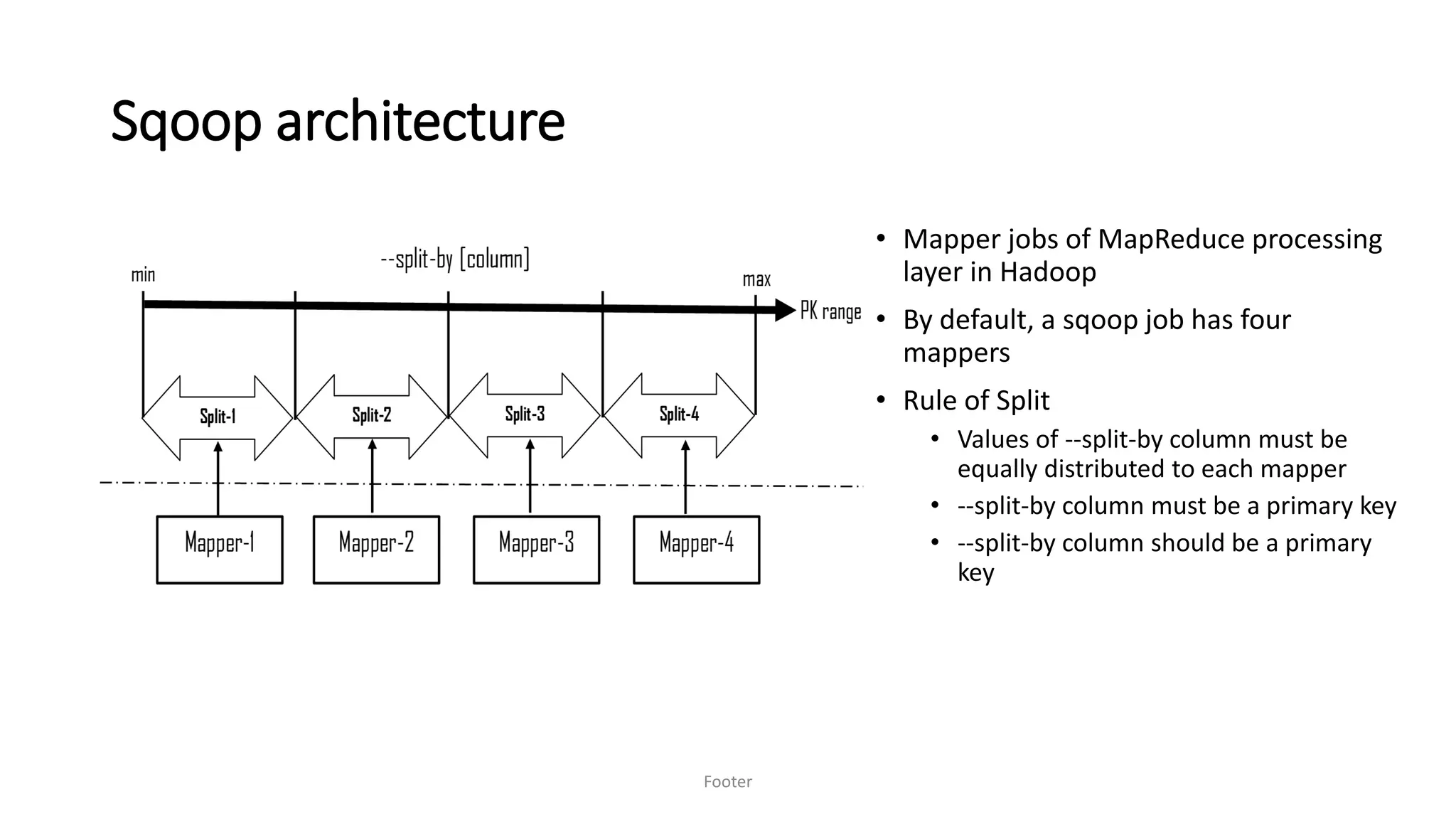
• Mappers
• --num-mappers [n] argument
• run in parallel within Hadoop. No formula but needs to be judiciously set
• Cannot split
• --autoreset-to-one-mapper to perform unsplit extraction
• Source has no PK
• Split based on natural or surrogate key
• Source has character keys
• Divide and conquer! Manual partitions and run one mapper per partition
• If key value is an integer, no worries
Footer](https://image.slidesharecdn.com/odevcyatradataindatalakesaurabhgupta-180907194100/75/Achieve-data-democracy-in-data-lake-with-data-integration-23-2048.jpg)

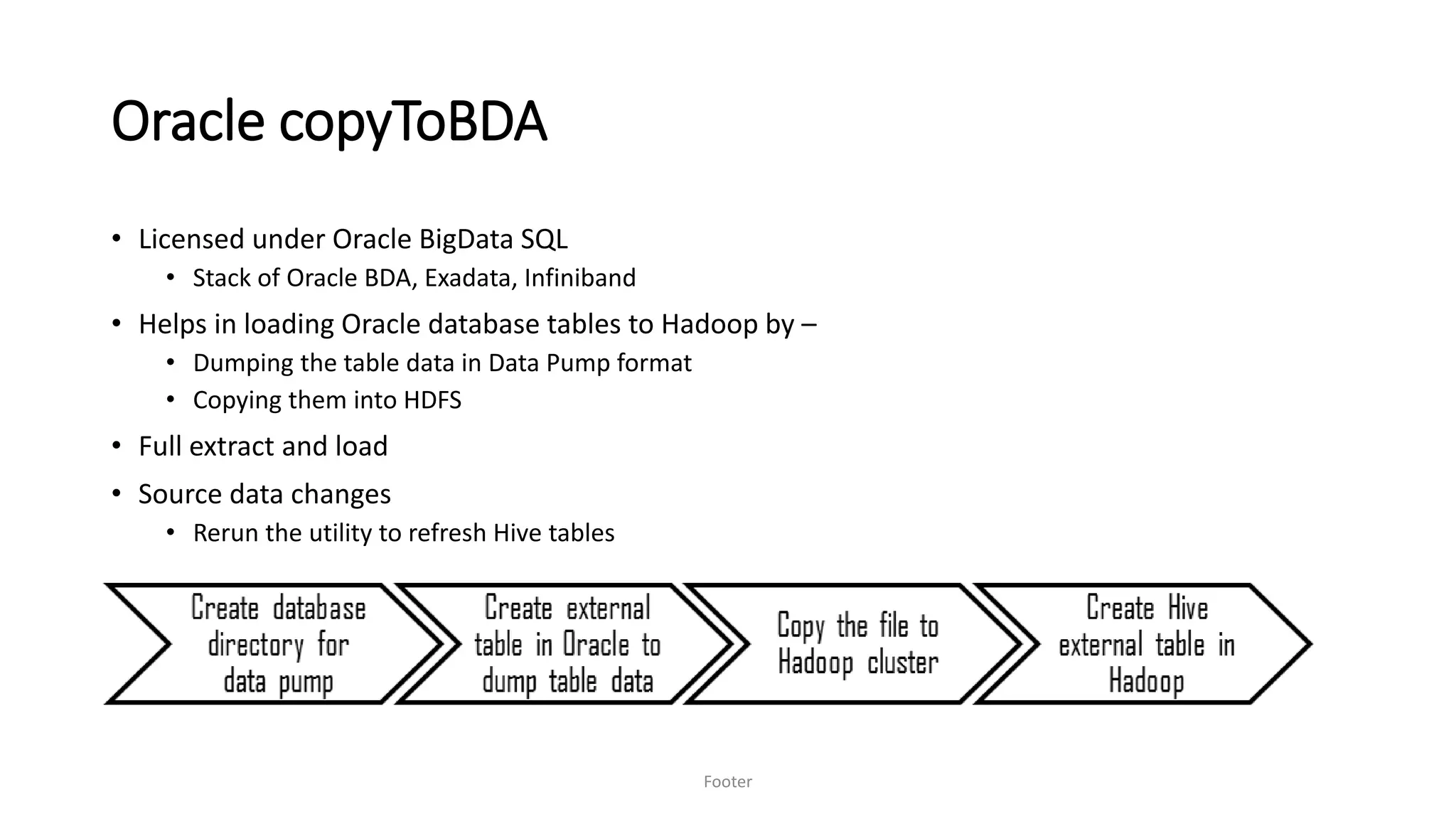
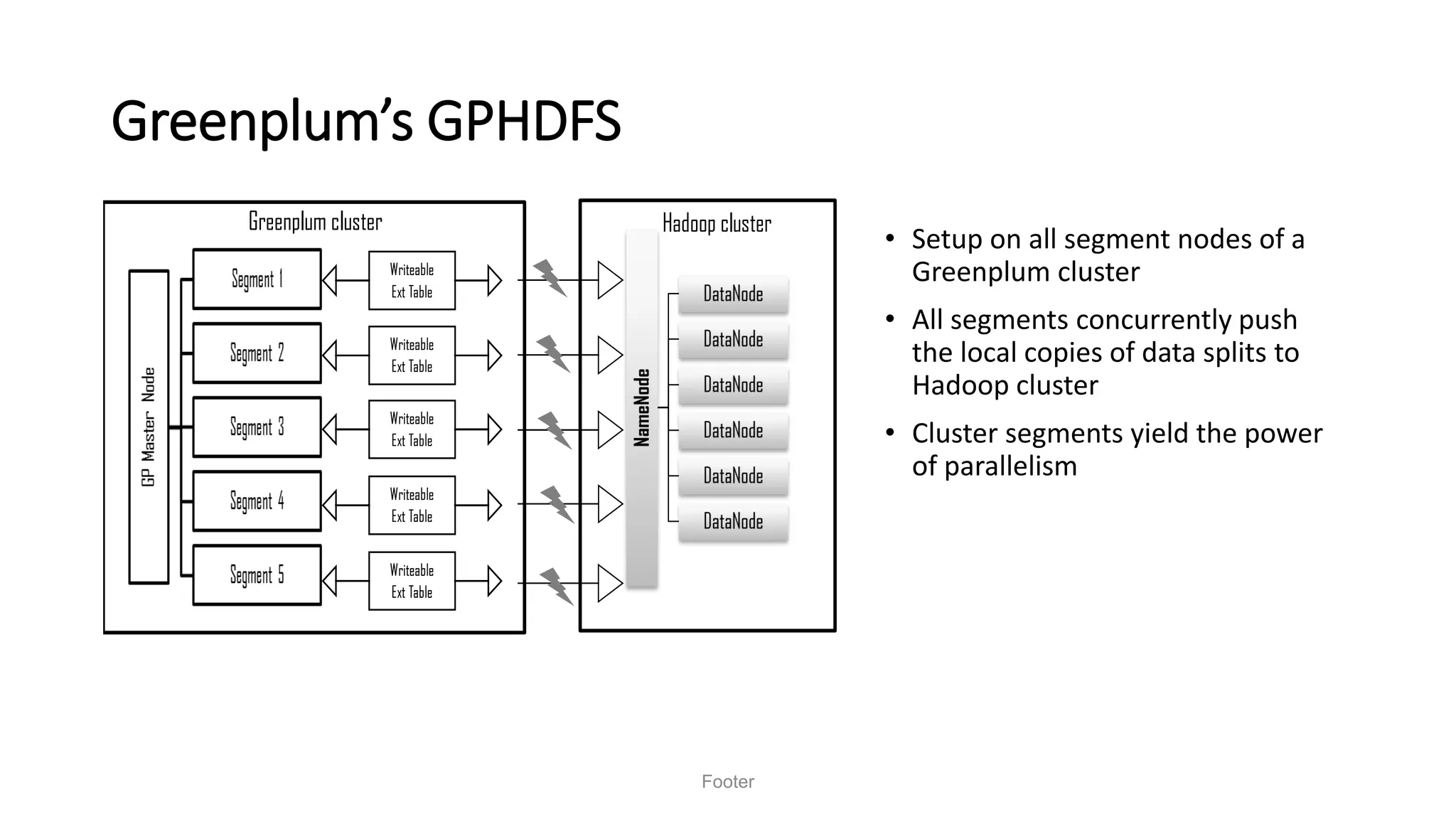
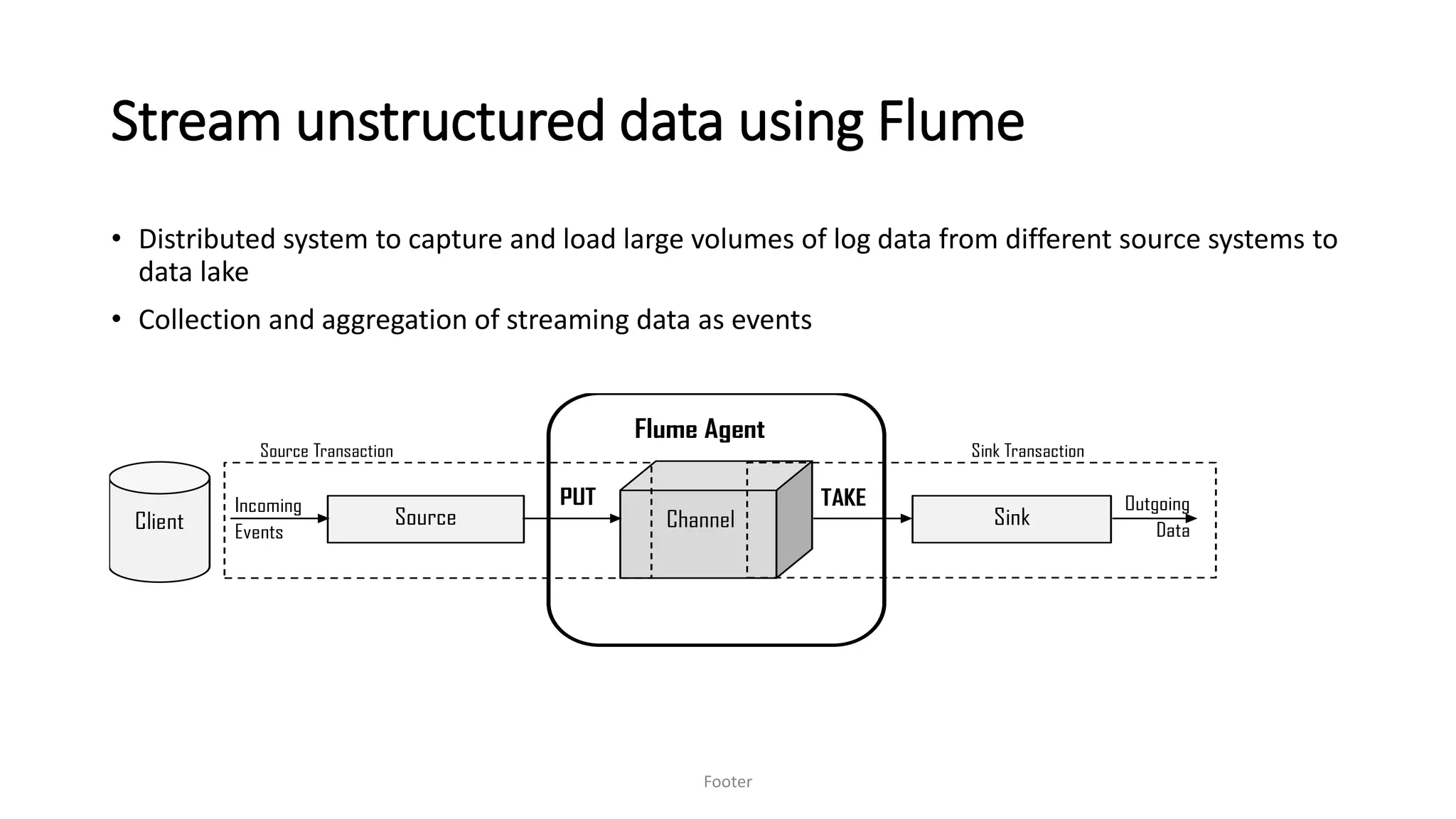

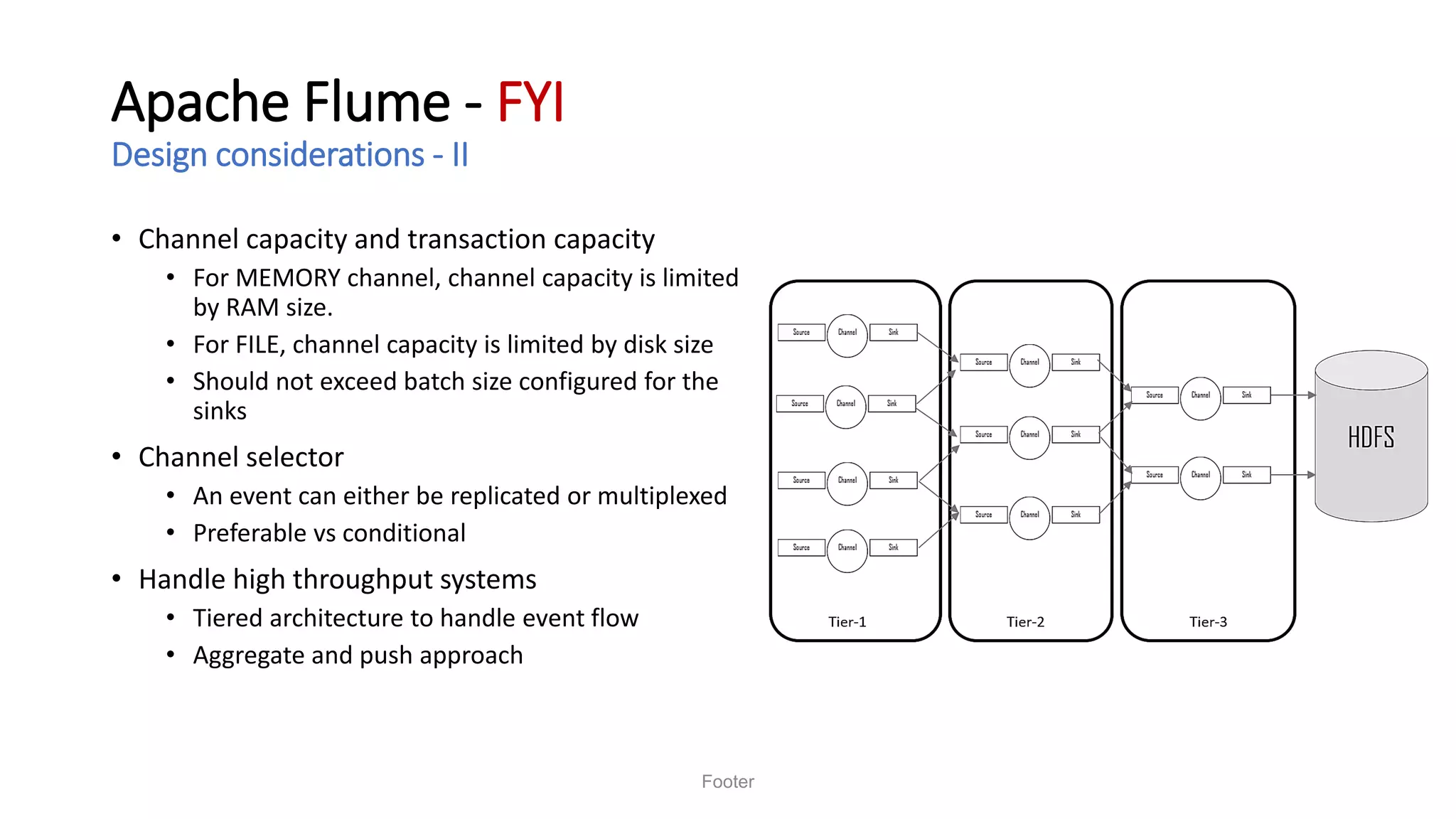



Saurabh K. Gupta discusses achieving data democratization through effective data integration. He outlines key considerations for data lake architecture and data ingestion frameworks to implement a data lake that empowers data democratization. The document provides an overview of data lake styles, principles for data ingestion, and techniques for batched and streaming data integration like Apache Sqoop, Apache Flume, and change data capture.



































































