Download as PDF, PPTX
















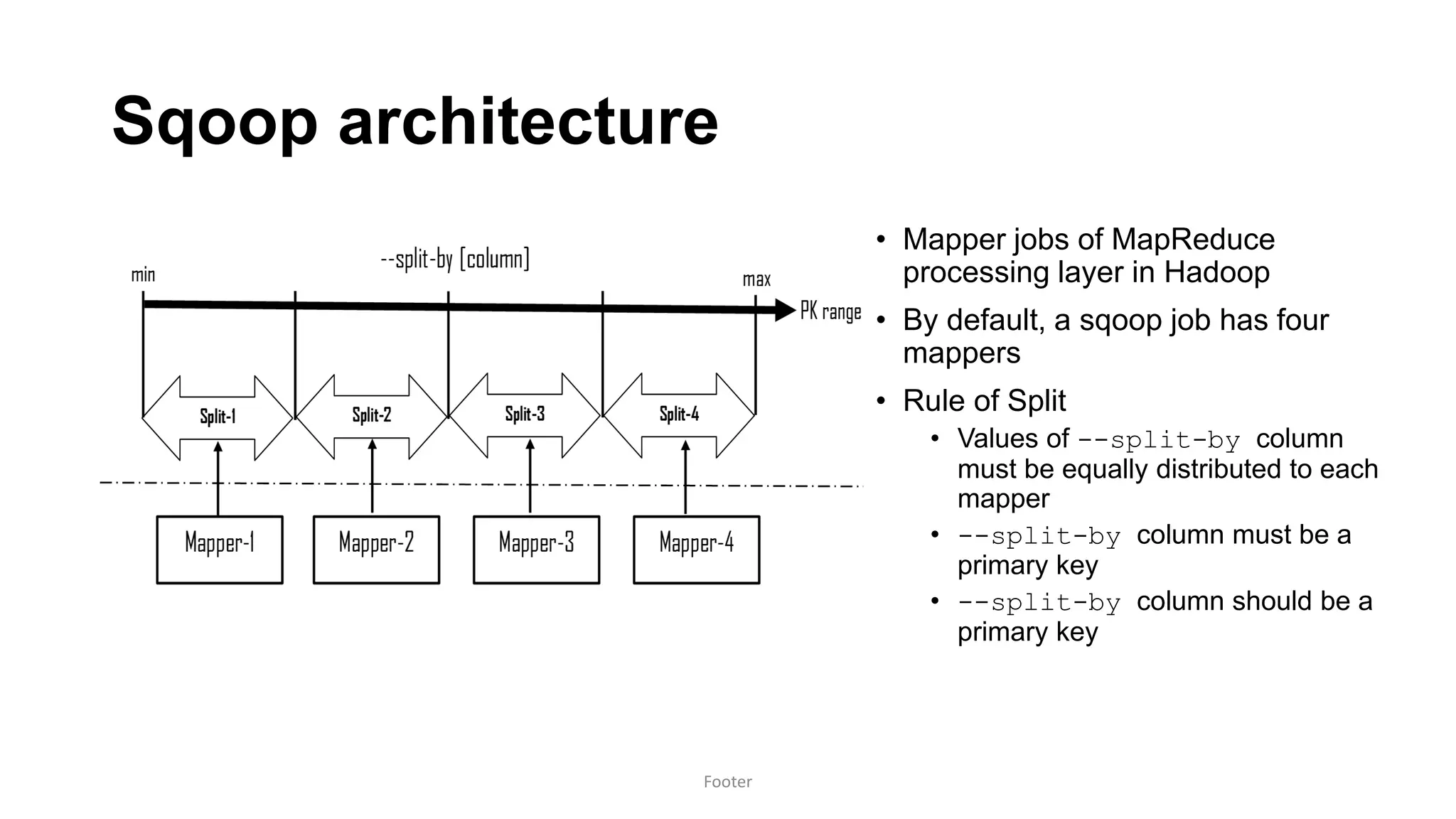
![Sqoop
Design considerations - I
• Mappers
• --num-mappers [n] argument
• run in parallel within Hadoop. No formula but needs to be judiciously set
• Cannot split
• --autoreset-to-one-mapper to perform unsplit extraction
• Source has no PK
• Split based on natural or surrogate key
• Source has character keys
• Divide and conquer! Manual partitions and run one mapper per partition
• If key value is an integer, no worries
Footer](https://image.slidesharecdn.com/sangam17dataindatalake-180907194418/75/Harness-the-power-of-Data-in-a-Big-Data-Lake-24-2048.jpg)


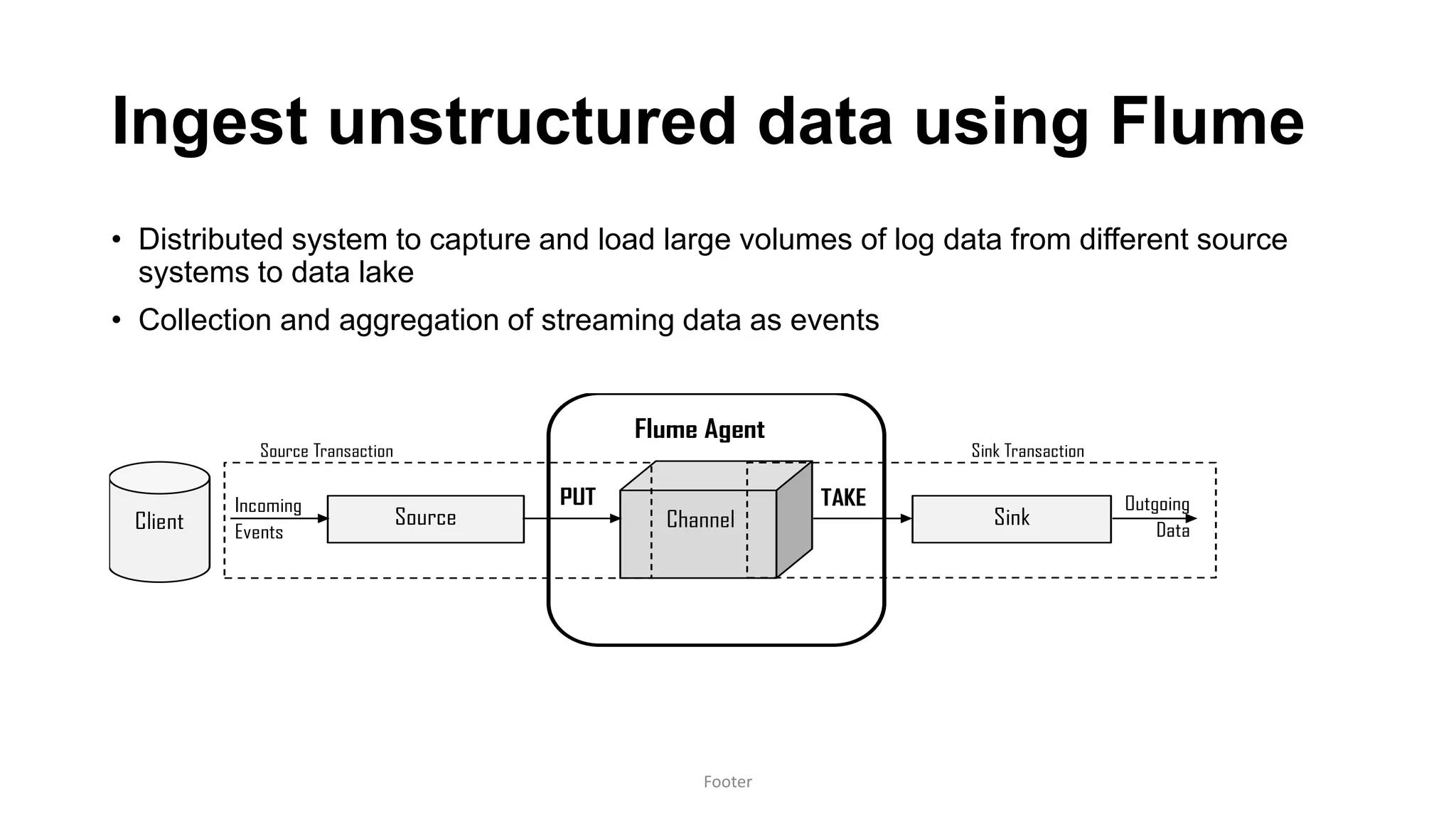

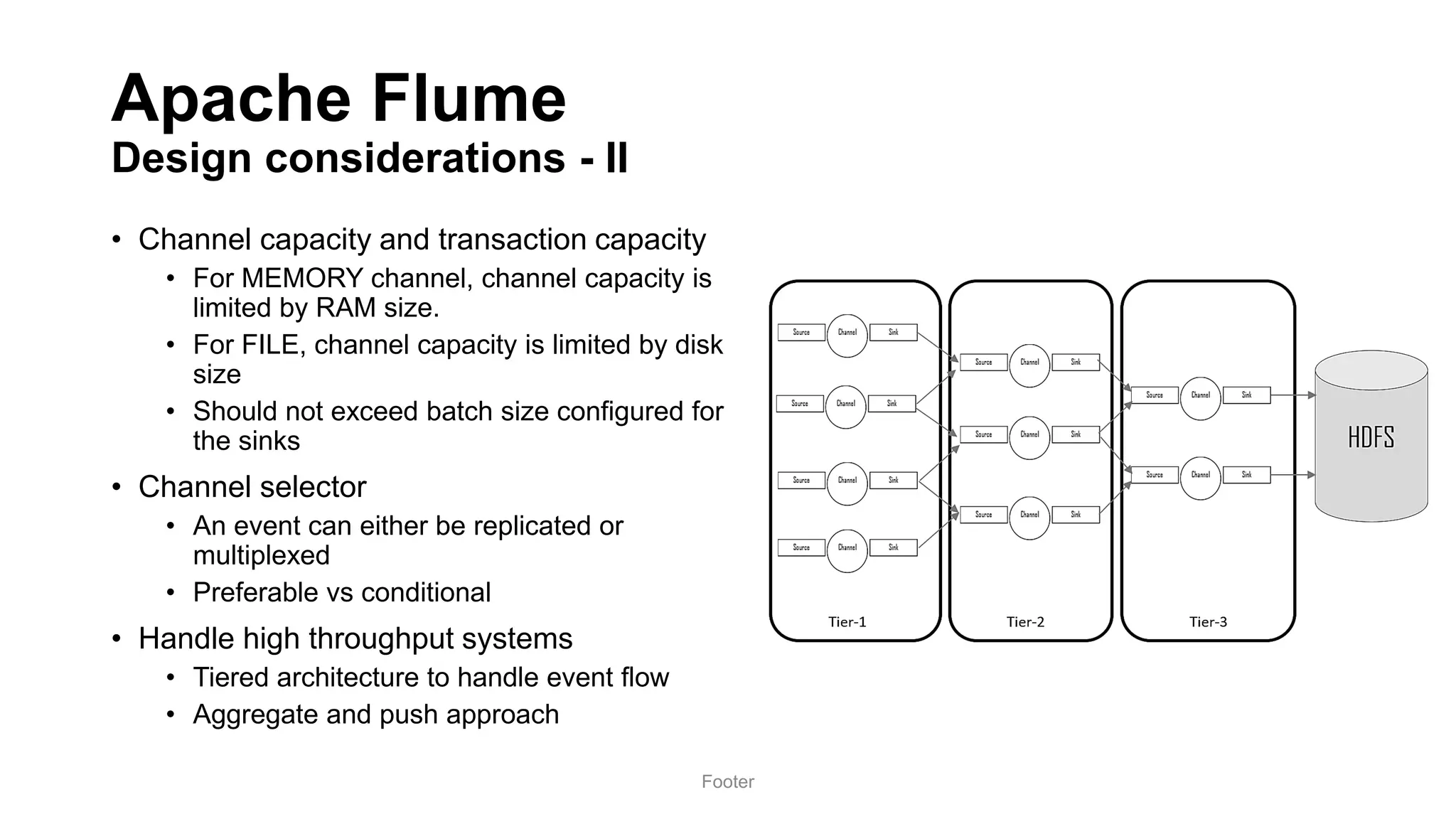



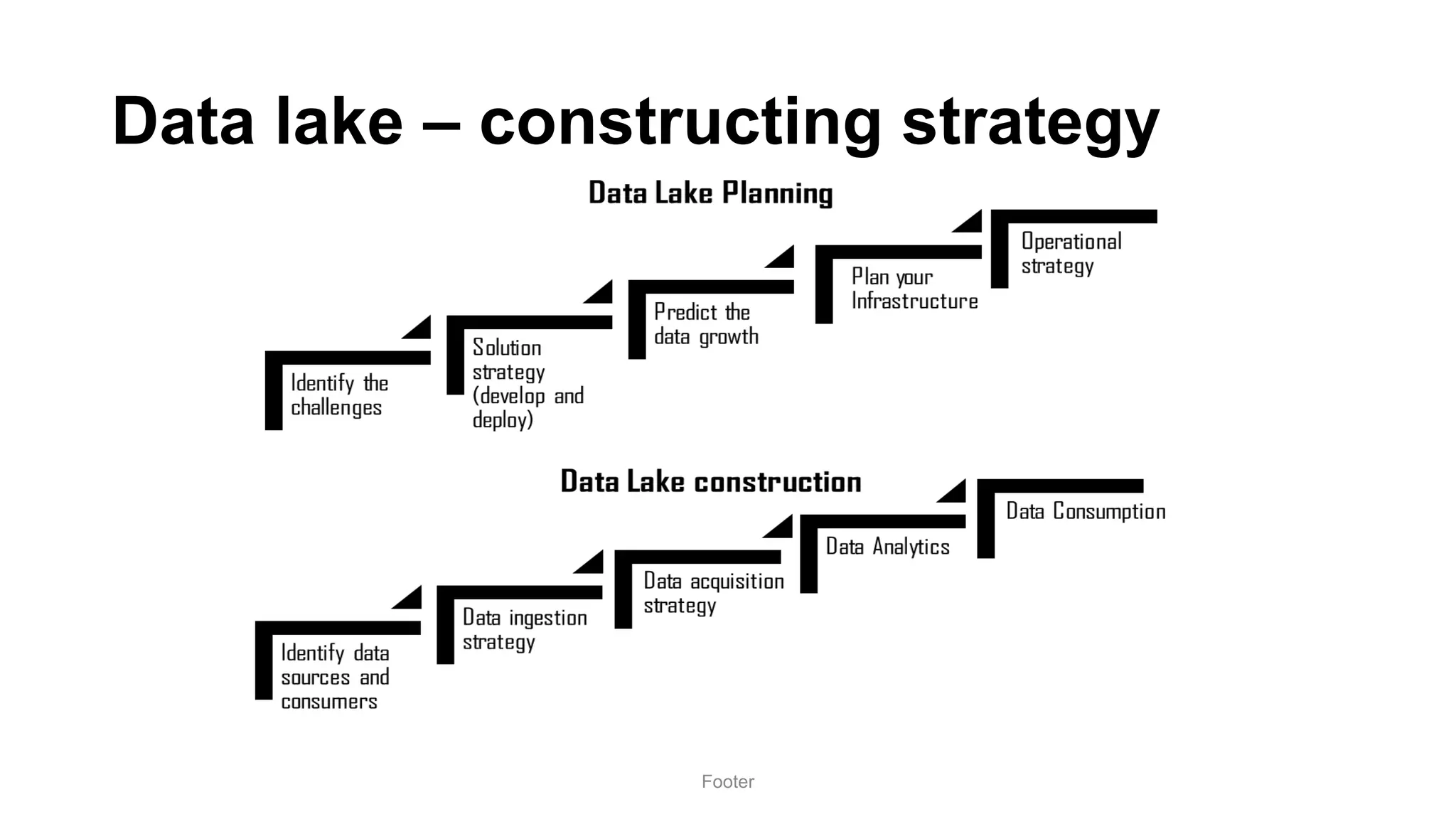
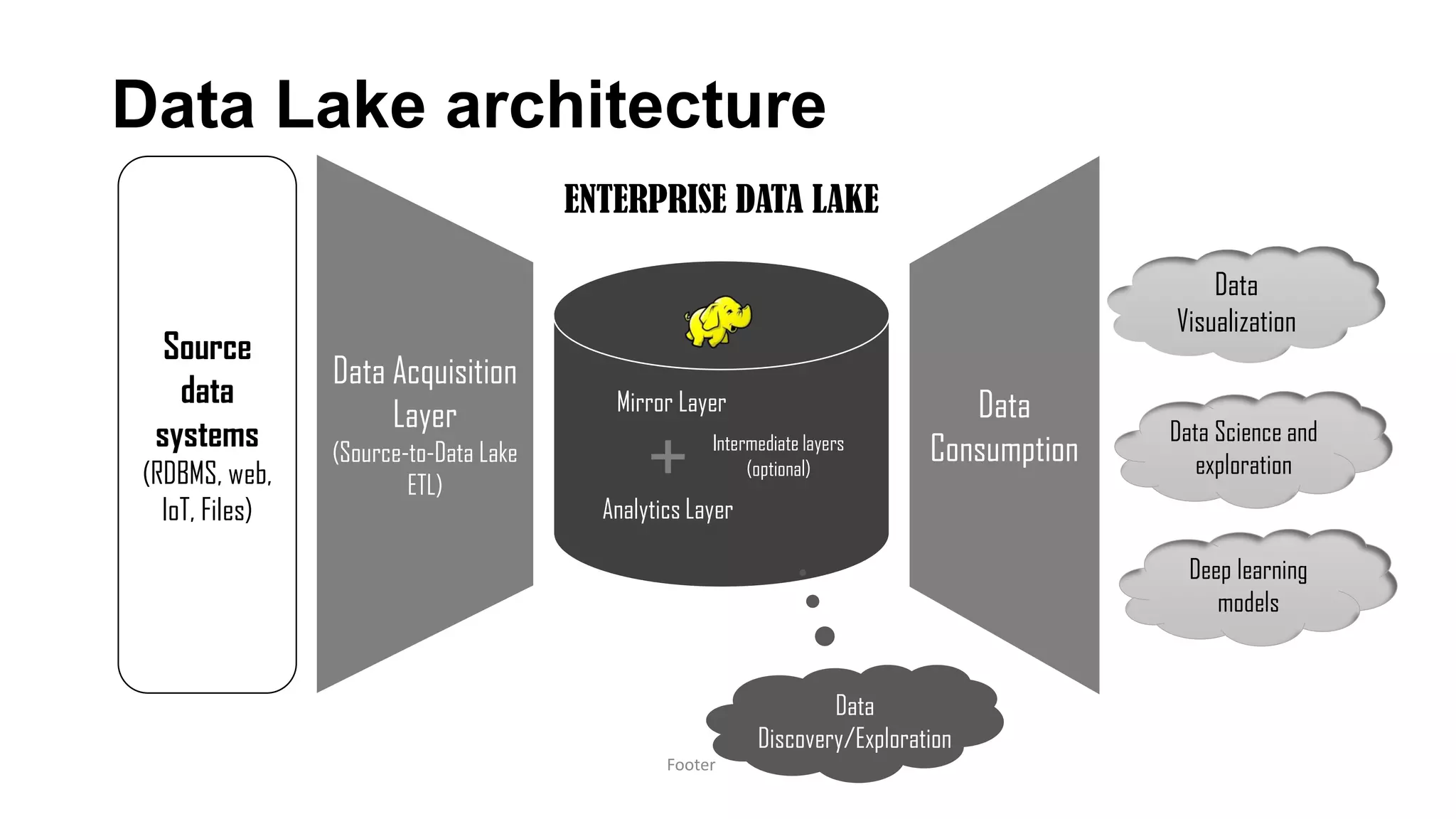
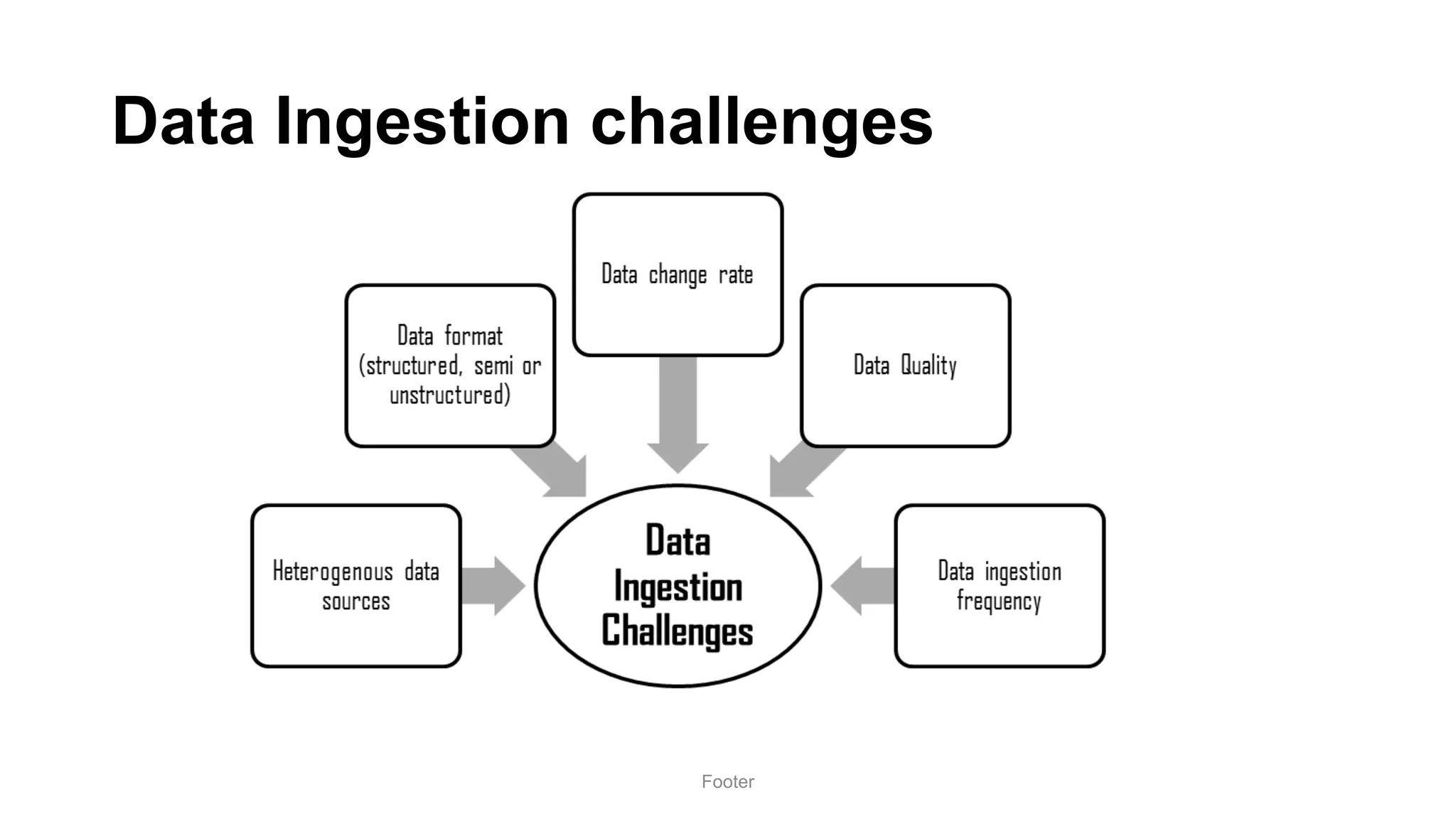
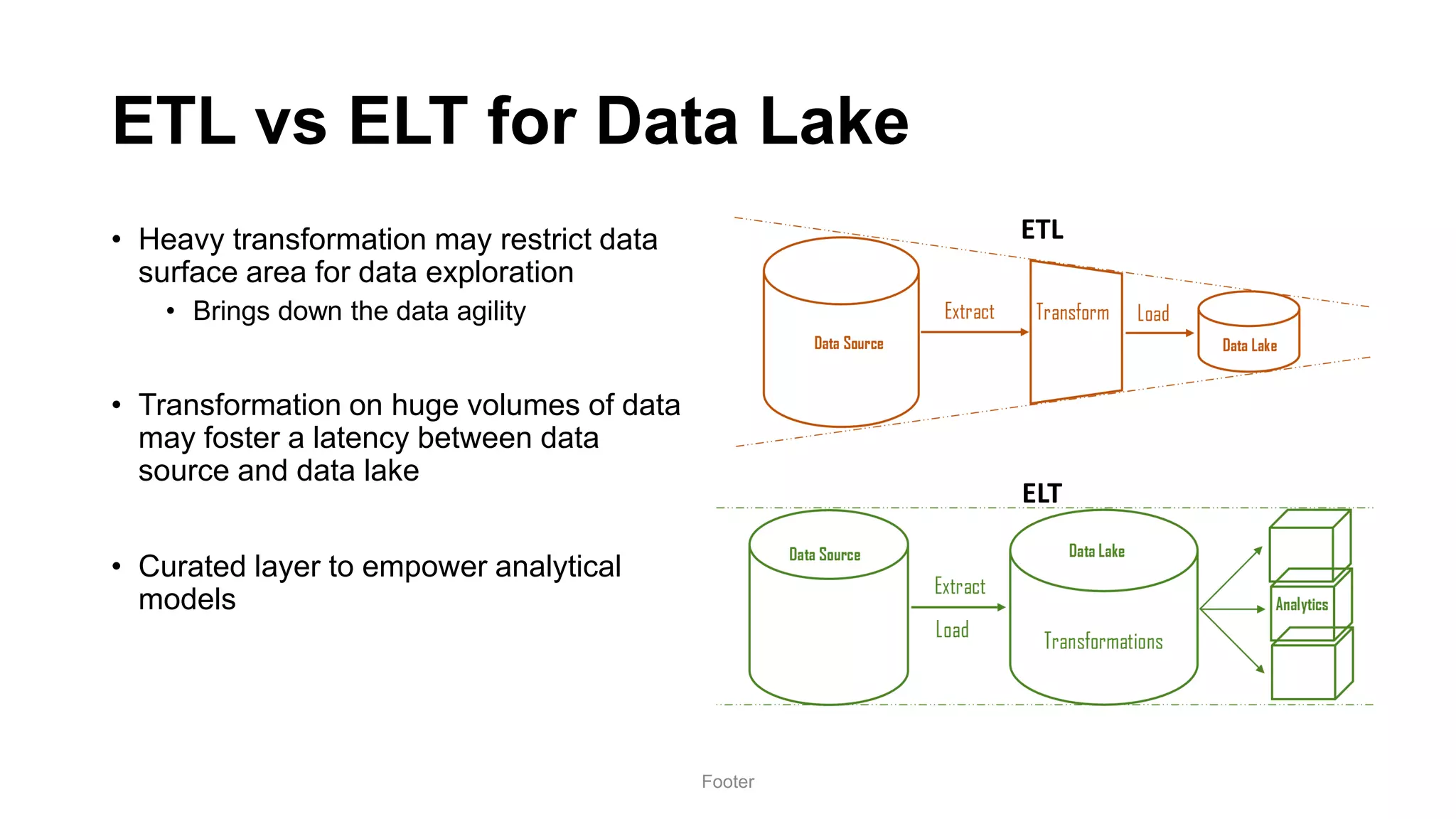
Harness the Power of Data in a Big Data Lake discusses strategies for ingesting and processing data in a data lake. It describes how to design a data ingestion framework that accounts for factors like data format, source, size, and location. The document contrasts ETL vs ELT approaches and discusses techniques for batched and change data capture ingestion of both structured and unstructured data. It also provides an overview of tools like Sqoop that can be used to ingest data from relational databases into a data lake.
















































![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)










