Download as PDF, PPTX







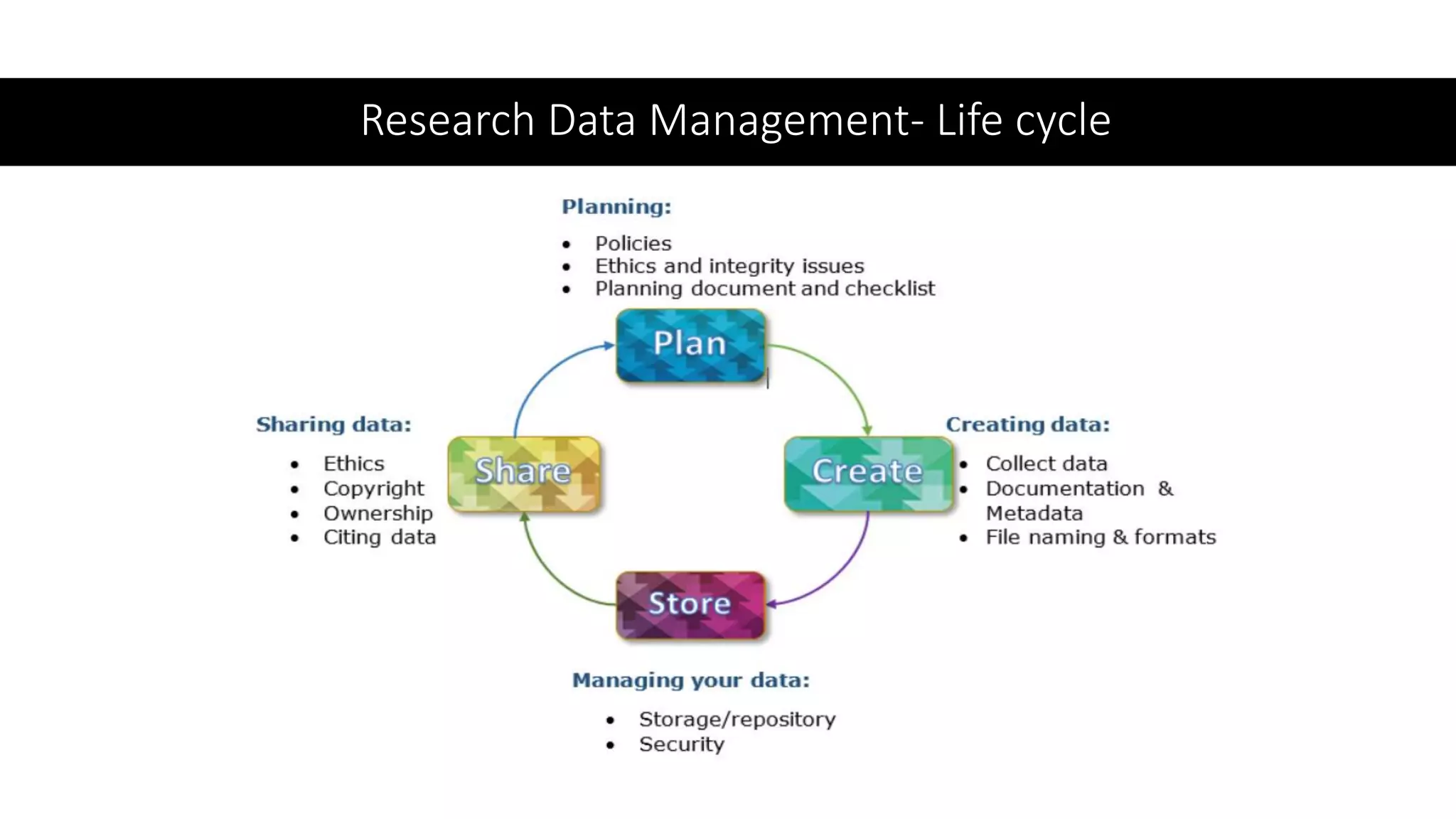














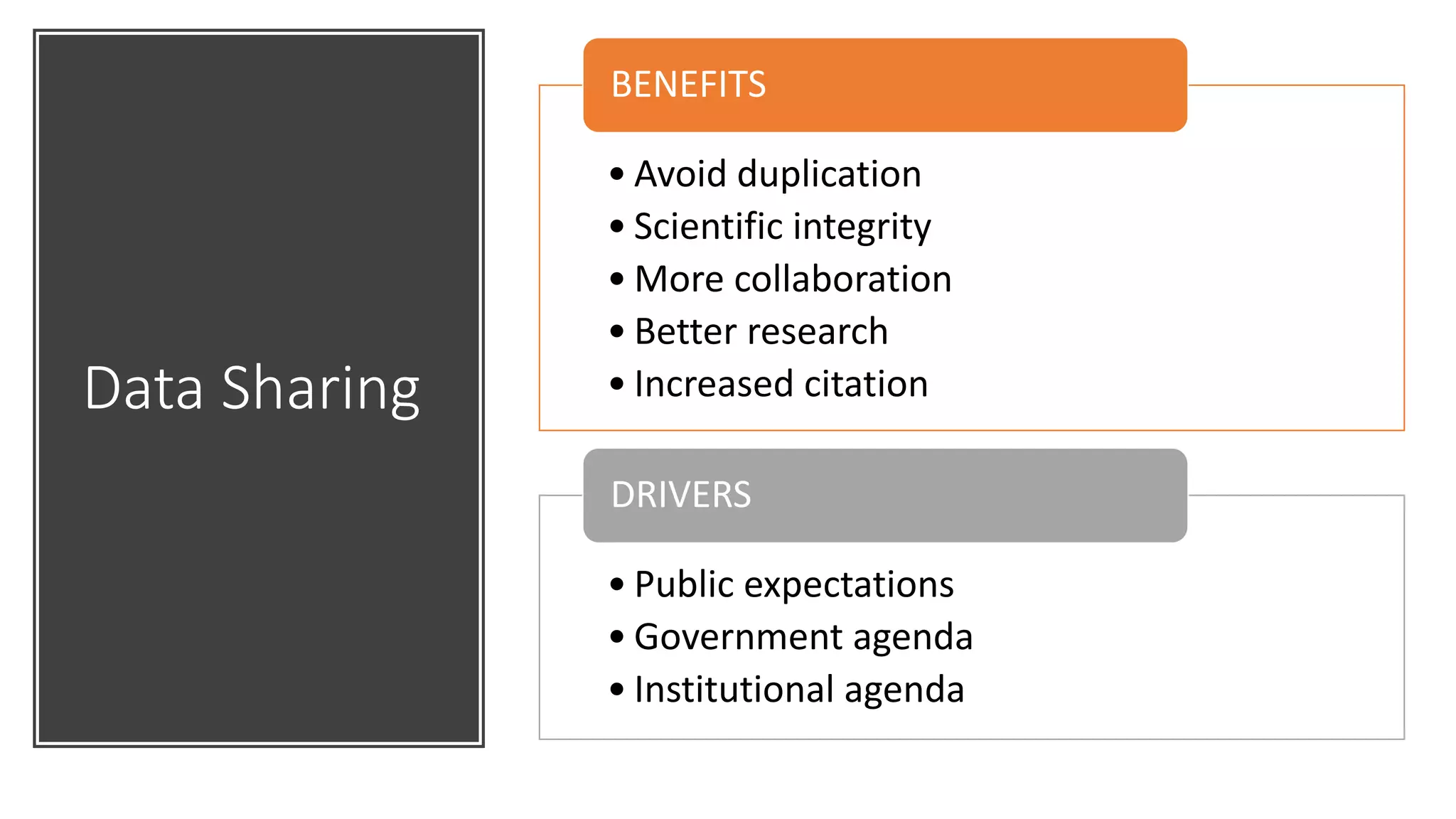









This document discusses research data management (RDM). It defines research data and describes the RDM lifecycle. Key aspects of RDM include creating data management plans, documenting and organizing data, and ensuring long-term preservation and sharing of data. The document outlines best practices for RDM, such as using appropriate file formats and metadata standards. It also discusses challenges around sensitive data and guidelines for data sharing and citation. The roles libraries can play in supporting RDM are identified, such as developing RDM policies, training researchers, and setting up data repositories.





















































































