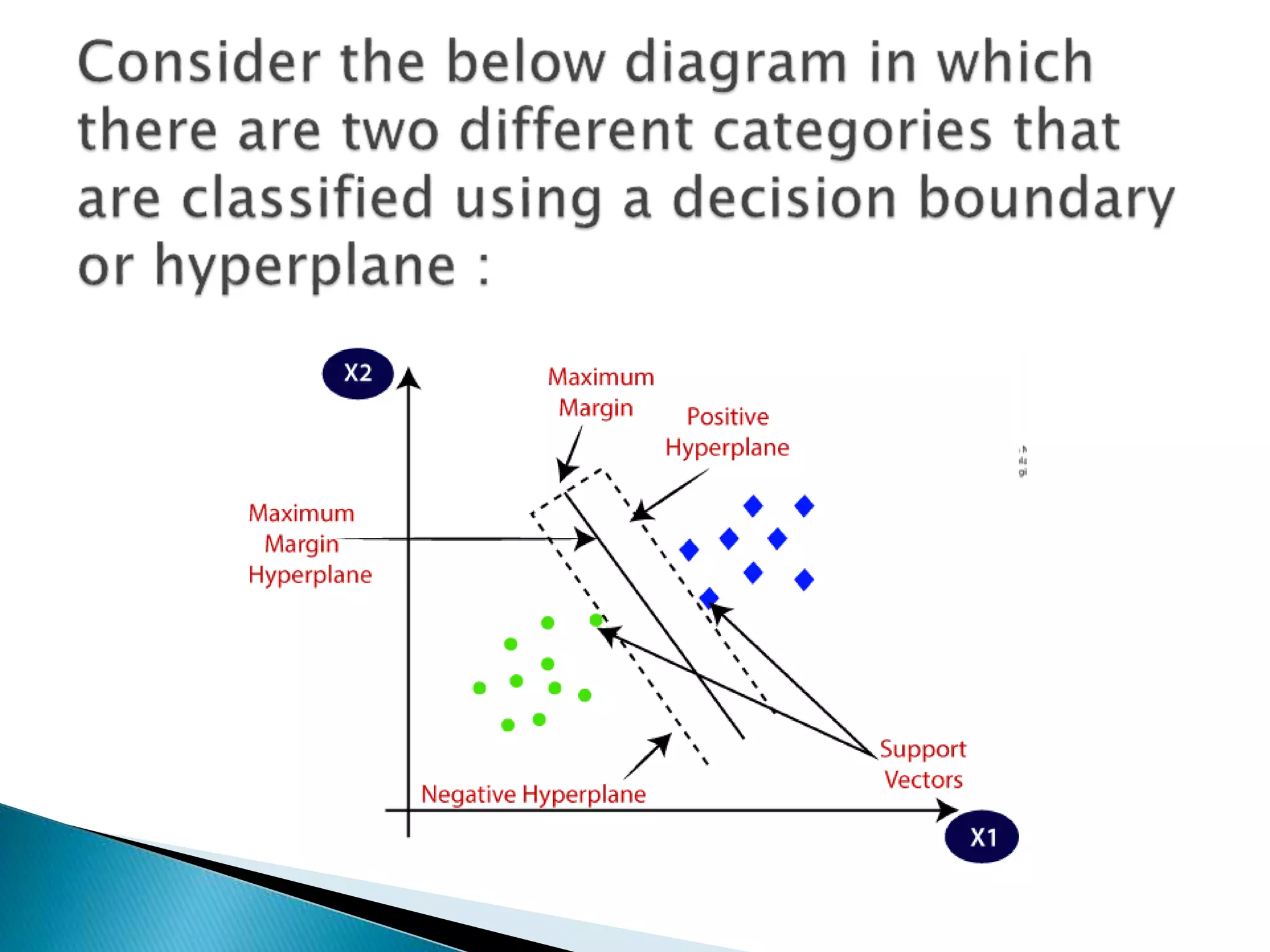
The document introduces Support Vector Machine (SVM) algorithms, primarily used for classification problems in machine learning, focusing on the creation of hyperplanes to segregate data. It discusses linear and non-linear SVMs for different types of data, along with the classification of association rules like support and confidence in consumer behavior. Additionally, it covers applications of SVMs in various fields, including web usage mining and market analysis.


























![SUPPORT VECTOR MACHINE ( SVM)akjhgaskjdgjksdgajkgdagdaakg[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/supportvectormachinesvm1-240702134610-f37092eb-thumbnail.jpg?width=640&height=640&fit=bounds)
![SVM[Support vector Machine] Machine learning](https://cdn.slidesharecdn.com/ss_thumbnails/svm-250403184638-1cd9afdb-thumbnail.jpg?width=640&height=640&fit=bounds)


















































