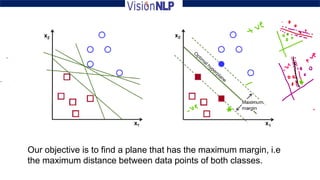
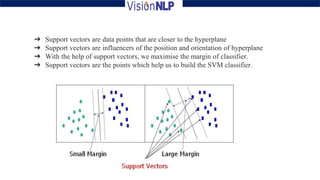
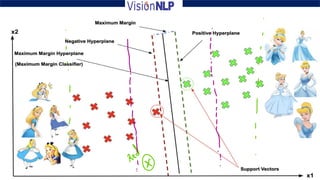
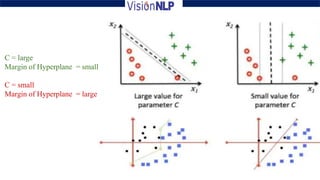
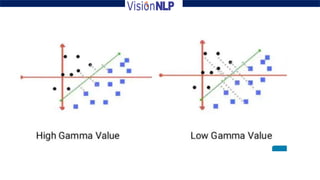
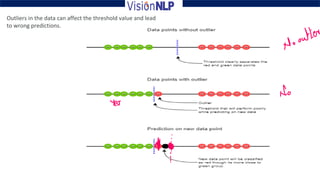
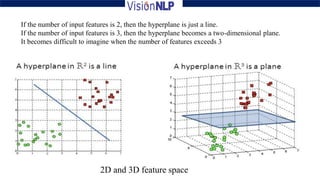
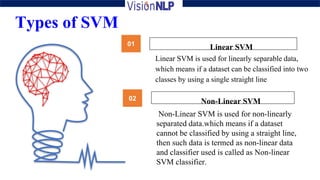
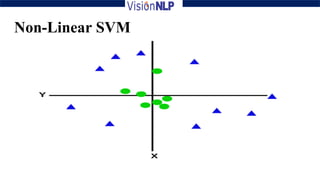
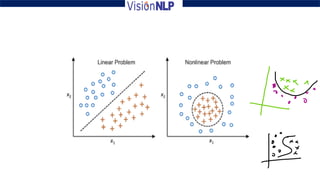
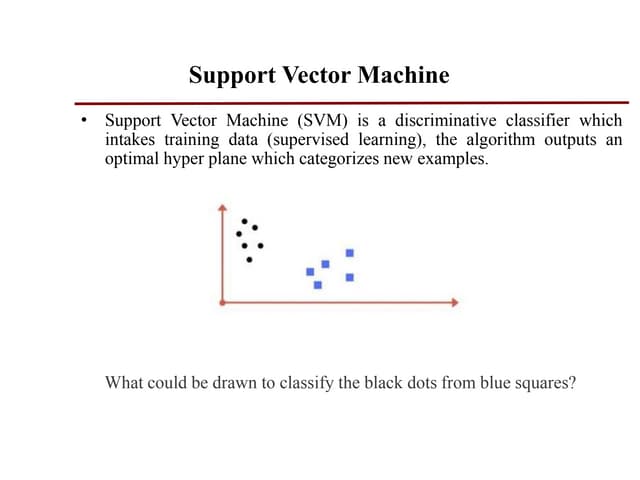
Support vector machines (SVM) is a supervised machine learning algorithm used for both classification and regression tasks. The goal of SVM is to find the optimal hyperplane that distinctly classifies data points by maximizing the margin between the two classes. It works well for smaller sized data with high dimensional features and performs classification by finding support vectors that are closest to the hyperplane.












![SVM[Support vector Machine] Machine learning](https://cdn.slidesharecdn.com/ss_thumbnails/svm-250403184638-1cd9afdb-thumbnail.jpg?width=640&height=640&fit=bounds)













![SUPPORT VECTOR MACHINE ( SVM)akjhgaskjdgjksdgajkgdagdaakg[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/supportvectormachinesvm1-240702134610-f37092eb-thumbnail.jpg?width=640&height=640&fit=bounds)


























