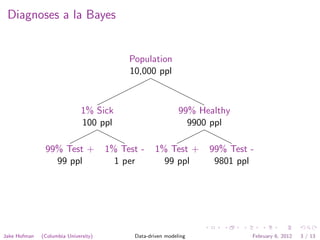
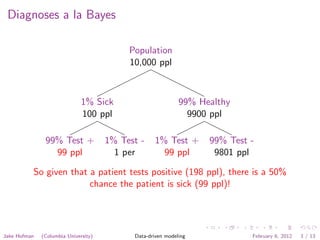
The document discusses using Naive Bayes classifiers for document classification. It explains how to represent documents as word vectors and model each word as an independent Bernoulli random variable. The likelihood of a document belonging to a class is calculated, and Bayes' rule is used to determine the posterior probability. Parameters are estimated by counting words in documents of each class. Weights and bias terms are calculated to yield a linear classifier, and predictions are made by adding the weights of words that appear.