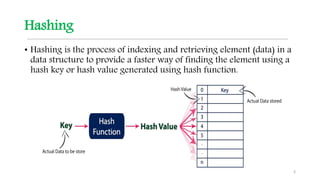
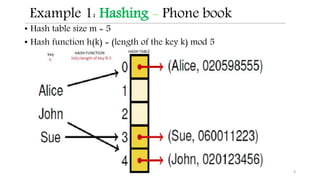
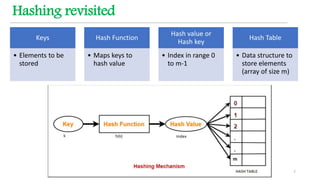
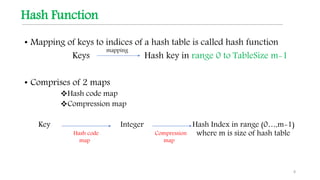
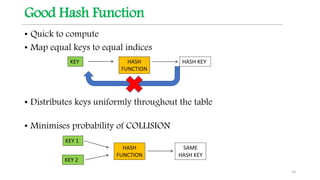
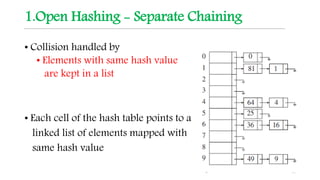
This document discusses hashing techniques for indexing and retrieving elements in a data structure. It begins by defining hashing and its components like hash functions, collisions, and collision handling. It then describes two common collision handling techniques - separate chaining and open addressing. Separate chaining uses linked lists to handle collisions while open addressing resolves collisions by probing to find alternate empty slots using techniques like linear probing and quadratic probing. The document provides examples and explanations of how these hashing techniques work.


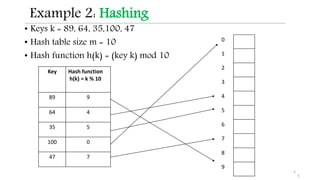

![Hash Function
• A hash function h maps keys of a given type to integers in a
fixed interval [0,……,m - 1]
h(k) hash value of k
9](https://image.slidesharecdn.com/hashingslideshare-210805140825/85/Data-Structures-Hashing-9-320.jpg)













![Linear Probing
Collision resolution strategy
Function f(i) = i where i is the probe parameter
Hashing function
hi(k) = [ h(k) + f(i) ] mod TableSize
= [ h(k) + i ] mod TableSize
Probe sequence: i iterating from 0 until alternative empty slot
0th probe = h(k) mod TableSize
1th probe = [ h(k) + 1] mod TableSize
2th probe = [ h(k) + 2] mod TableSize
. . .
ith probe = [ h(k) + i ]mod TableSize 25](https://image.slidesharecdn.com/hashingslideshare-210805140825/85/Data-Structures-Hashing-25-320.jpg)
![Linear probing
Insert keys 89, 18, 49, 58, 69
26
Index Keys
0
1
2
3
4
5
6
7
8
9 89
Index Keys
0
1
2
3
4
5
6
7
8 18
9 89
Index Keys
0 49
1
2
3
4
5
6
7
8 18
9 89
Insert 89 Insert 18 Insert 49
hi(k) =[ h( k ) + i ] mod Tablesize
= [ h( k ) + i ] % 10
i=0
h0(89)
=[ h(89)+0 ] % 10
=[ 9+0 ] % 10
= 9
i=0
h0(18)
=[ h(18)+0 ] % 10
=[ 8+0 ] % 10
= 8
i=0
h0(49)
=[ h(49)+0 ] % 10
=[ 9+0 ] % 10
= 9
i=1
h1(49)
=[ h(49)+1 ]%10
=[9 +1] % 10
= 0
Collision occurs as
Slot 9 occupied by 89](https://image.slidesharecdn.com/hashingslideshare-210805140825/85/Data-Structures-Hashing-26-320.jpg)
![Linear probing ………….. Contd.
Insert keys 89, 18, 49, 58, 69
27
Index Keys
0 49
1 58
2
3
4
5
6
7
8 18
9 89
Index Keys
0 49
1 58
2 69
3
4
5
6
7
8 18
9 89
Insert 58 Insert 69
i=0
h0(58)
=[ h(58)+0] % 10
=[ 8+0 ] % 10
= 8
(Collision)
i=0
h0(69)
=[ h(69)+0 ] % 10
= 9
(Collision)
i=1
h1(58)
=[ h(58)+1 ] % 10
=[ 8+1 ] % 10
= 9
(Collision)
i=2
h2(58)
=[ h(58)+2 ] % 10
=[ 8+2 ] % 10
= 0
(Collision)
i=3
h3(58)
=[ h(58)+3) % 10
=[ 8+3 ] % 10
= 1
i=1
h1(69)
=[ h(69)+1 ] % 10
= 0
(Collision)
i=2
h2(69)
=[ h(69)+2 ] % 10
= 1
(Collision)
i=3
h3(69)
=[ h(69)+3 ] % 10
= 2
hi(k) =[ h( k ) + i ] mod Tablesize
= [ h( k ) + i ] % 10](https://image.slidesharecdn.com/hashingslideshare-210805140825/85/Data-Structures-Hashing-27-320.jpg)
![Insertion Routine
LinearProbeInsert(k)
if (table is full) error
probe = h(k) // probe= location
while (table [probe] occupied)
probe = (probe+1) mod m
table [probe] = k
28](https://image.slidesharecdn.com/hashingslideshare-210805140825/85/Data-Structures-Hashing-28-320.jpg)

![Search Routine
LinearProbeSearch(k)
if (table is empty) error
probe = h(k) // probe= location
while (table [probe] occupied and table [probe]!=k )
probe = (probe+1) mod m
if table [probe] = k
return probe
else
not found
30](https://image.slidesharecdn.com/hashingslideshare-210805140825/85/Data-Structures-Hashing-30-320.jpg)


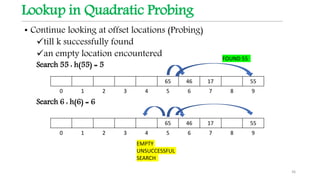
![Quadratic Probing
Collision resolution strategy
Function f(i) = i2 where i is the probe parameter
Hashing function
hi(k) = [ h(k) + f(i) ] mod TableSize
= [ h(k) + i2 ] mod TableSize
Probe sequence: i iterating from 0
0th probe = h(k) mod TableSize
1th probe = [ h(k) + 1 ] mod TableSize
2th probe = [ h(k) + 4 ] mod TableSize
3rd probe = [ h(k) + 9 ] mod TableSize
. . . ith probe = [ h(k) + i2
] mod TableSize 33](https://image.slidesharecdn.com/hashingslideshare-210805140825/85/Data-Structures-Hashing-33-320.jpg)
![Quadratic Probing
Insert keys 89, 18, 49, 58, 69
34
Index Keys
0
1
2
3
4
5
6
7
8
9 89
Index Keys
0
1
2
3
4
5
6
7
8 18
9 89
Index Keys
0 49
1
2
3
4
5
6
7
8 18
9 89
Insert 89 Insert 18 Insert 49
hi(k) = [ h ( k ) + i2 ] mod Tablesize
= [ h ( k ) + i2 ] % 10
i=0
h0(89)
=[ h(89)+ 02]%10
=[ 9 + 0] % 10
= 9
i=0
h0(18)
=[ h(18)+ 02]%10
=[ 8 + 0] % 10
= 8
i=0
h0(49)
=[ h(49)+ 02
]%10
= 9
i=1
h1(49]
=[ h(49)+ 12
]%10
= 0
Collision occurs as
Slot 9 occupied by 89](https://image.slidesharecdn.com/hashingslideshare-210805140825/85/Data-Structures-Hashing-34-320.jpg)
![Quadratic probing ………….. Contd.
Insert keys 89, 18, 49, 58, 69
35
Index Keys
0 49
1
2 58
3
4
5
6
7
8 18
9 89
Index Keys
0 49
1
2 58
3 69
4
5
6
7
8 18
9 89
Insert 58 Insert 69
i=0
h0(58)= [ h(58)+ 02]%10
= 8
(Collision)
i=0
h0(69) = [ h(69)+ 02]%10
= 9
(Collision)
i=1
h1(58) = [ h(58)+ 12]%10
= 9
(Collision)
i=2
h2(58)= [ h(58)+ 22]%10
= 2
i=1
h1(69) = [ h(69)+ 12
]%10
= 0
(Collision)
i=2
h2(69) = [ h(69)+ 22]%10
= 3
hi(k) = [ h ( k ) + i2 ] mod Tablesize
= [ h ( k ) + i2 ] % 10](https://image.slidesharecdn.com/hashingslideshare-210805140825/85/Data-Structures-Hashing-35-320.jpg)


![Double Hashing
• Uses 2 hash functions h1(k) and h2(k)
• h1(k) is first position to check keys
h1(k) = k mod TableSize
• h2(k) determines offset
h2(k) = R – (k * mod R) where R is a prime smaller than
TableSize
• Collision resolution strategy
Function f(i) = i ∗ h2(k)
• Hashing function
hi(k)= [ h1(k) + f(i) ] mod TableSize
hi(k)= [ h1(k) + i ∗ h2(k) ] mod TableSize
39
hi(k)= [ h1(k) + f(i) ] mod TableSize](https://image.slidesharecdn.com/hashingslideshare-210805140825/85/Data-Structures-Hashing-39-320.jpg)
![Double Hashing
Hashing function
hi(k)= [ h1(k) + i ∗ h2(k) ] mod TableSize
where h1(k) = k mod TableSize and h2(k)=R – (k * mod R)
Probe sequence: i iterating from 0
0th probe = h(k) mod TableSize
1th probe = [ h1(k) + 1∗ h2(k) ] mod TableSize
2th probe = [ h1(k) + 2 ∗ h2(k) ] mod TableSize
3rd probe = [ h1(k) + 3 ∗ h2(k) ] mod TableSize
. . .
ith probe = [ h1(k) + i ∗ h2(k) ] mod TableSize
40](https://image.slidesharecdn.com/hashingslideshare-210805140825/85/Data-Structures-Hashing-40-320.jpg)
![Double Hashing
Insert keys 89, 18, 49, 58, 69
41
hi(k)= [ h1(k) + i ∗ h2(k) ] mod TableSize
= [ h1(k) + i ∗ h2(k) ] % 10
KEY 89 18 49 58 69
h1(k)=k % 10 9 8 9 8 9
h2(k) = R – ( k mod R )
=7 – ( k % 7 )
2 3 7 5 1
hi(k) = ( h1(k) + i * h2(k) ) % 10
For i=0
h0(89)
= (9+0*2) % 10
= 9
h0(18)
= (8+0*3) % 10
= 8
h0(49)
= (9+0*7) % 10
= 9
h0(58)
= (8+0*7) % 10
= 8
h0(69)
= (9+0*7) % 10
= 9
i=1
h1(49)
= (9+1*7) % 10
= 6
h1(58)
= (8+1*7) % 10
= 3
h1(69)
= (9+1*7) % 10
= 0
0 1 2 3 4 5 6 7 8 9
69 58 49 18 89
HASH TABLE](https://image.slidesharecdn.com/hashingslideshare-210805140825/85/Data-Structures-Hashing-41-320.jpg)
![Double Hashing
DoubleHashingInsert(k)
if (table is full) error
probe=h1(k) ; offset=h2(k) // probe= location
while (table[probe] occupied)
probe=(probe+offset) mod m
table[probe]=k
42](https://image.slidesharecdn.com/hashingslideshare-210805140825/85/Data-Structures-Hashing-42-320.jpg)